Streamline read scalability with Cloud SQL autoscaling read pools
Phil Sung
Software Engineer
Shahzeb Farrukh
Product Manager
A common pattern for applications that read frequently from a database is to offload read-heavy workloads to a read replica. This allows applications to scale without impacting critical write operations on the primary database instance. However, these read-heavy workloads can easily exceed the capacity of a single read replica. While developers can manually implement multiple replicas behind a load balancer, this approach is complex and difficult to maintain and scale.
Cloud SQL provides a simplified, fully managed solution to scale your reads using read pools for MySQL and PostgreSQL. This feature allows you to provision multiple read replicas that are accessible via a single read endpoint, so you can easily add and remove read replicas without having to make any application changes. To further improve efficiency, we recently introduced autoscaling for Cloud SQL read pools, which dynamically adjusts your read capability based on real-time application needs. Read pools with autoscaling are now generally available under Cloud SQL Enterprise Plus edition. You can find more details in the MySQL and PostgreSQL documentation, as well as the release notes.
Why read pools?
When you create a read pool replicating from a primary instance, Cloud SQL automatically provisions multiple read replicas, referred to as read pool nodes, and creates a single load balancer (called the read endpoint) that dispatches queries to the nodes round-robin. A pool can contain anywhere from 1 to 20 nodes.
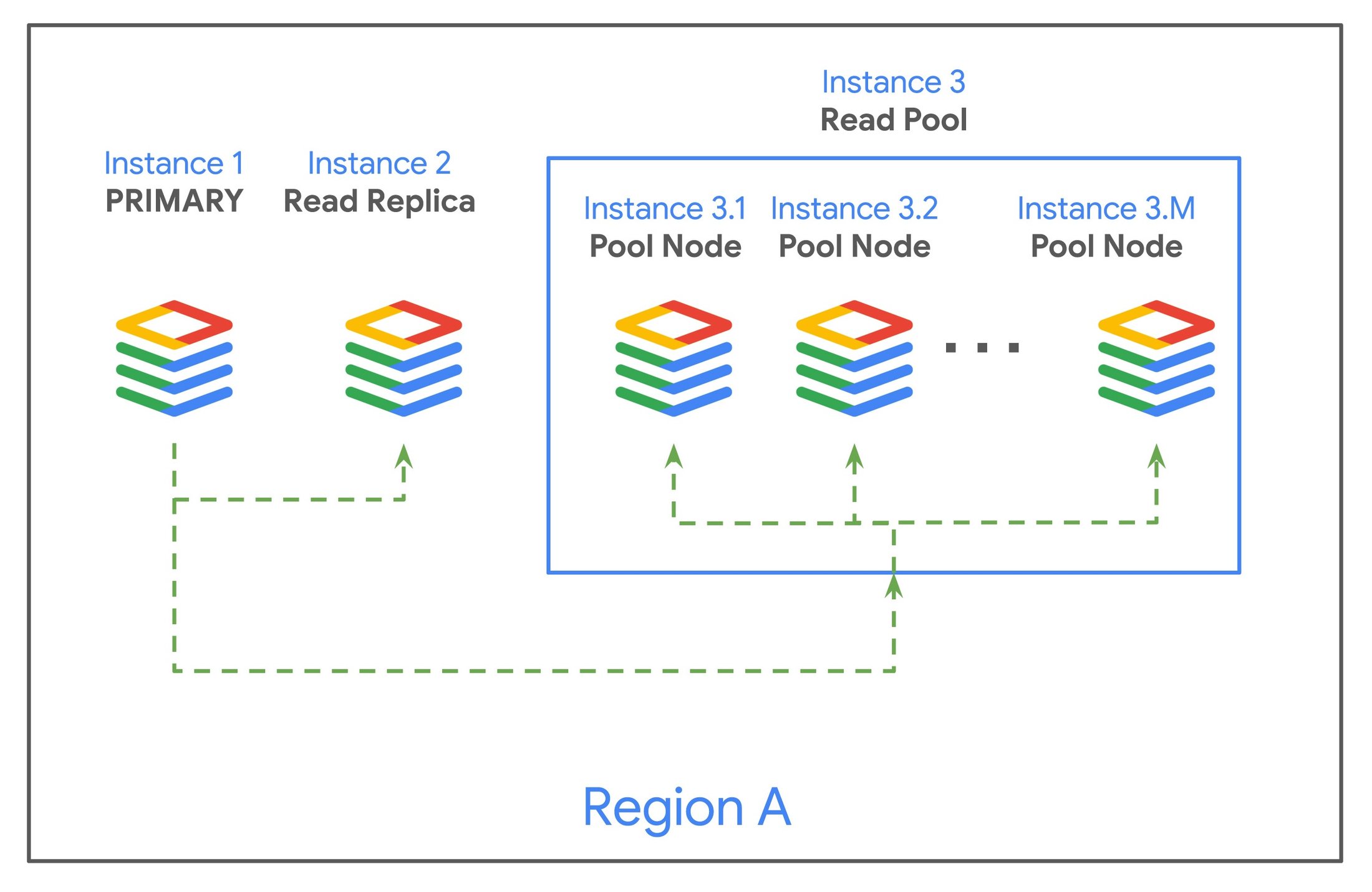
A read pool is managed as a single entity to reduce your operational burden. The pool represents a homogeneous set of nodes; whenever you make any configuration change such as updating database flags, the VM type, or other parameters, the change is automatically applied to all nodes in the pool. You can also scale out and in by adding or removing nodes from the pool at any time in response to changes in the workload. Since all queries flow through the read endpoint's load balancer, you don’t need to reconfigure your applications, even as the nodes in the pool are being updated, added, or removed.
Easier scaling with read pool autoscaling
Read pools truly shine in scenarios with variable workloads. With the general availability of autoscaling for Cloud SQL read pools, managing these fluctuations is even easier.
Key benefits of read pool autoscaling:
-
Manage traffic spikes automatically: Maintain application responsiveness during peak demand as the pool dynamically scales up to 20 nodes based on database connections or CPU usage.
-
Simplify operations: Because autoscaling is integrated with a single read endpoint, your applications stay connected to the same address even as underlying nodes are adjusted.
-
Optimize costs: Pay only for the resources you actually use by automatically scaling in during low-traffic periods, preventing the expense of over-provisioning.
How Cloud SQL improves availability with read pools
Engineered for mission-critical reliability, Cloud SQL read pools provide the foundation for your high-availability read workloads. By maintaining at least two nodes, your read pool is backed by a 99.99% availability SLA, which includes coverage for maintenance downtime. To do this, Cloud SQL intelligently manages your environment in the following ways:
-
When you add nodes to a read pool, existing connections continue without interruption on the preexisting nodes. New connections may be directed to the newly added nodes and the load shifts to be evenly balanced across the nodes as pre-existing connections finish their work.
-
For read pools containing two or more nodes, when you modify the VM type or database flags, or perform most other configuration updates, the read pool is updated with near-zero downtime.
-
As for any other Cloud SQL instance, Cloud SQL automatically detects and repairs issues with the underlying hardware for your read pool instances. Whenever a node is found to be unhealthy, it is removed from the load balancer rotation and a new node is created to replace it.
Enabling and using read pools with autoscaling
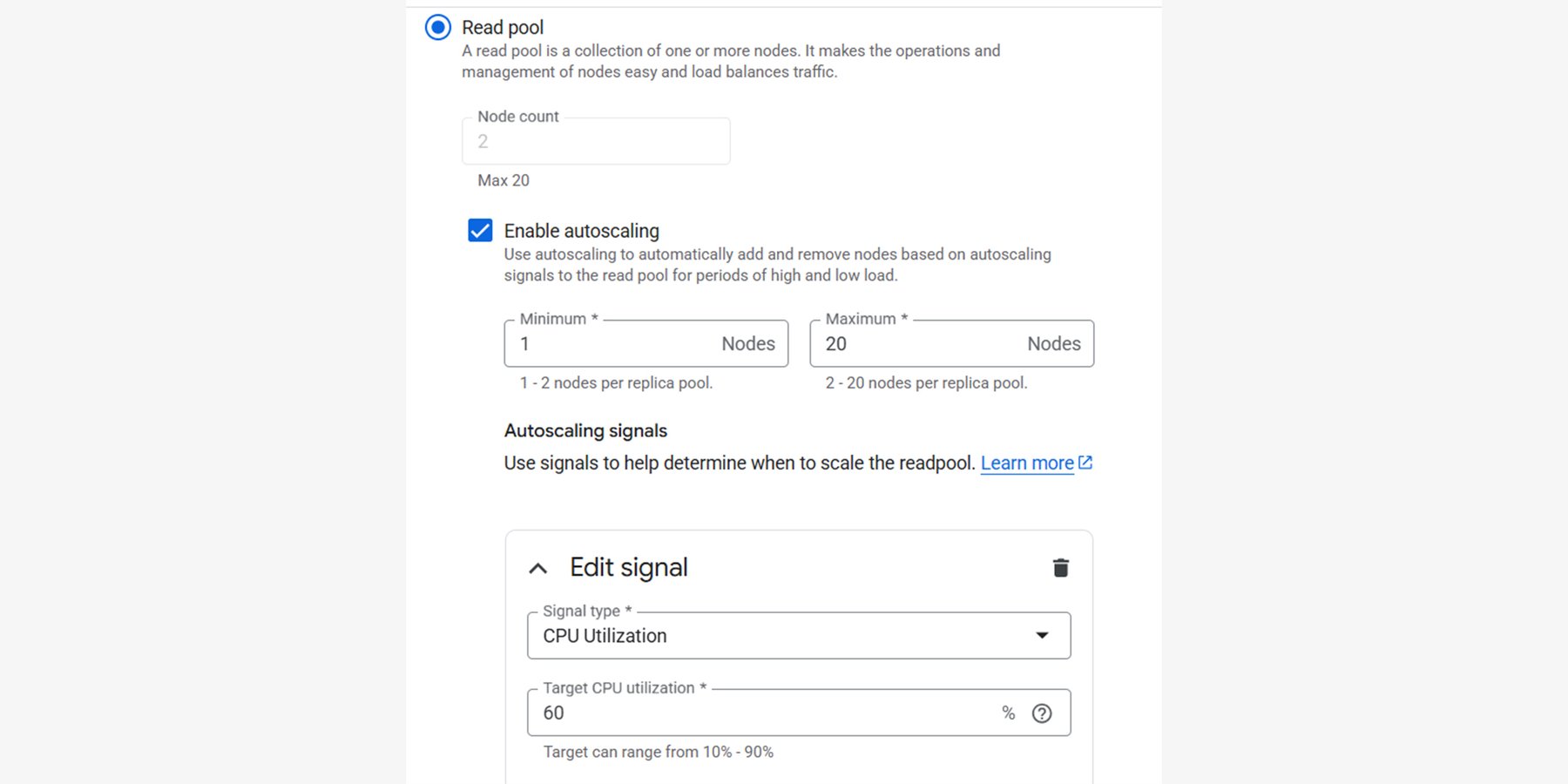
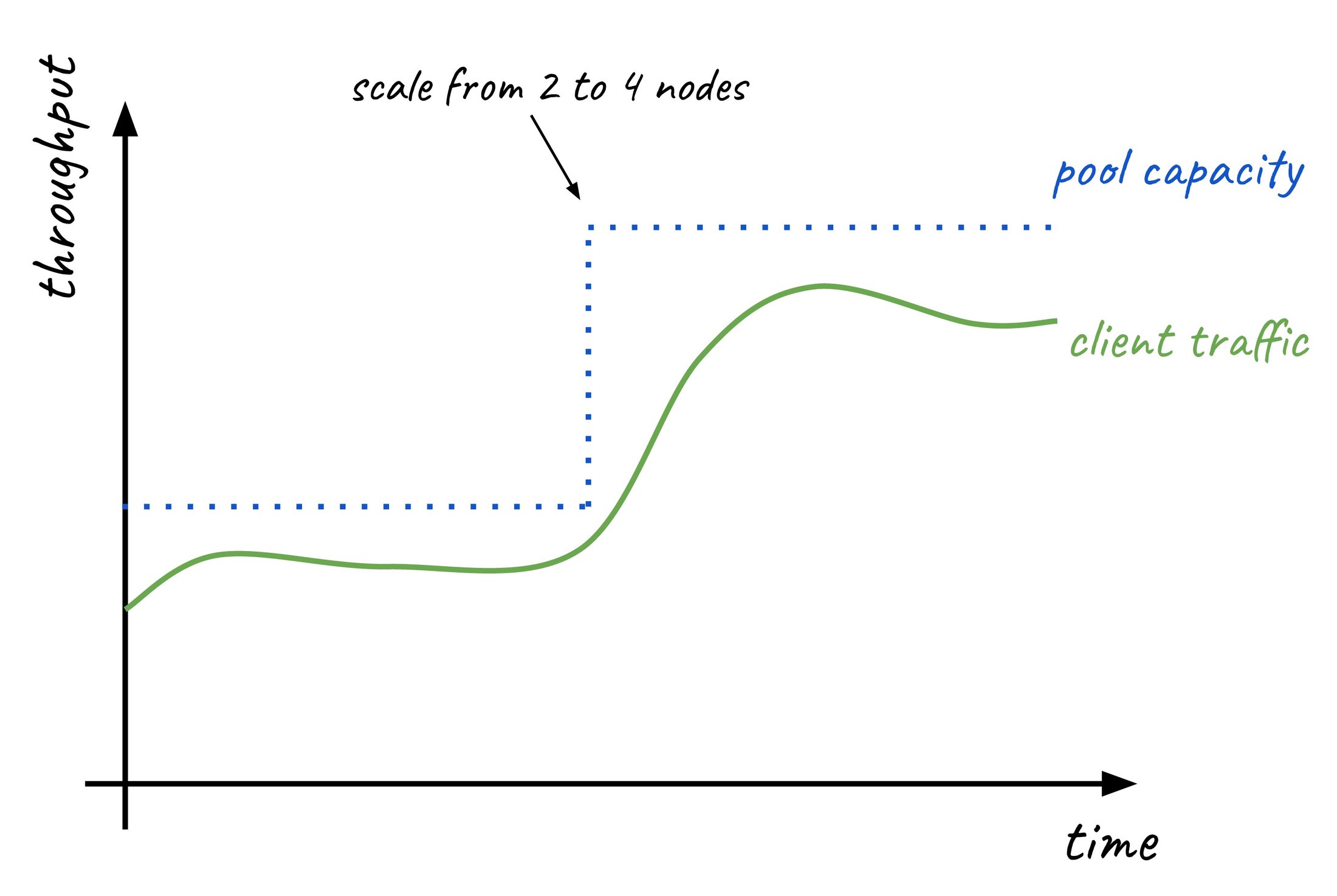
Read pools excel in environments with highly variable workloads. With Cloud SQL autoscaling, you can define minimum and maximum node counts while setting targets for key metrics like CPU utilization or database connections.
Retail is a prime example. Traffic often fluctuates based on daily cycles, seasonal shifts, or flash sales. By dynamically scaling out to meet these peaks and scaling once demand subsides, you provide a strong customer experience without the overhead of an over-provisioned environment.
If you've already created an Enterprise Plus edition instance, you can create a read pool that replicates from it. The following command creates a read pool with two nodes and enables autoscaling, configured to scale between 2 and 10 nodes based on keeping CPU utilization around 60%:
You can obtain the read endpoint's IP address by inspecting the instance in Google Cloud console or using the gcloud CLI. This IP address doesn't change for the lifetime of the pool.
If you have an existing read pool, you can easily enable autoscaling on it:
This command configures myreadpool to automatically scale between two and 10 nodes, targeting a maximum of 100 database connections per node on average.
While autoscaling is recommended for most variable workloads, you can still manually scale your read pool if needed by updating the node count directly:
Get started today
By using read pools with new autoscaling capabilities, you can avoid the tedious tasks associated with managing a large set of read replicas, and give your applications the read capacity they need, when they need it, without overspending. To get started today, please refer to the following resources:
- Cloud SQL documentation for read pools
- About read pools (MySQL, PostgreSQL)
- Creating and managing read pools (MySQL, PostgreSQL): includes example commands for gcloud CLI, Terraform, and REST API
- Read pool autoscaling (MySQL, PostgreSQL): includes example commands for gcloud CLI, Terraform, and REST API
- Sign up for the new Cloud SQL free trial, a dedicated 30-day program designed to give both new and existing Google Cloud users hands-on access to premium, enterprise-grade features of Cloud SQL (PostgreSQL and MySQL).
