Enhance business continuity for your on-premises SQL Server instance with Cloud SQL for SQL Server
Alex Cârciu
Solutions Architect, Google Cloud
Database professionals managing SQL Server need to design their systems to be resilient against data loss in disaster scenarios. This often involves using a mix of full, differential and transaction log backups. The frequency of the transaction log backups can be tuned to fit your recovery point objective (RPO) definition, with some professionals recommending taking log backups as often as once per minute.
One common model customers use for further reducing data loss is replicating these backups to another environment, so you have a standby copy of your primary SQL Server database in another service. For example, Cloud SQL uses cross-region read replicas as part of a disaster recovery (DR) procedure. You can promote a cross-region replica to fail over to another region should the primary instance's region become unavailable.
In this blog post, we'll explore how to easily set up a DR architecture using Cloud SQL for both on-premises and other public cloud providers' SQL Server instances, through seamless replication of regular backups and subsequent import into Cloud SQL for SQL Server.
Cloud SQL supports importing transaction log backups. This opens up multiple possibilities, including near real-time database migration of your database or having a Cloud SQL for SQL Server to act as DR for your existing database instances, offering a flexible, robust and reliable solution to ensure business continuity and data integrity.
Setting up a Cloud SQL for SQL Server DR architecture
You start by restoring a full backup of your database to the designated Cloud SQL for SQL Server DR instance. Then, you upload sequentially your transaction log backups to Cloud Storage. With the help of an EventArc trigger, a Cloud Function that orchestrates the import operations is executed. The function makes a request to the Cloud SQL instance to import and restore the uploaded backup file.
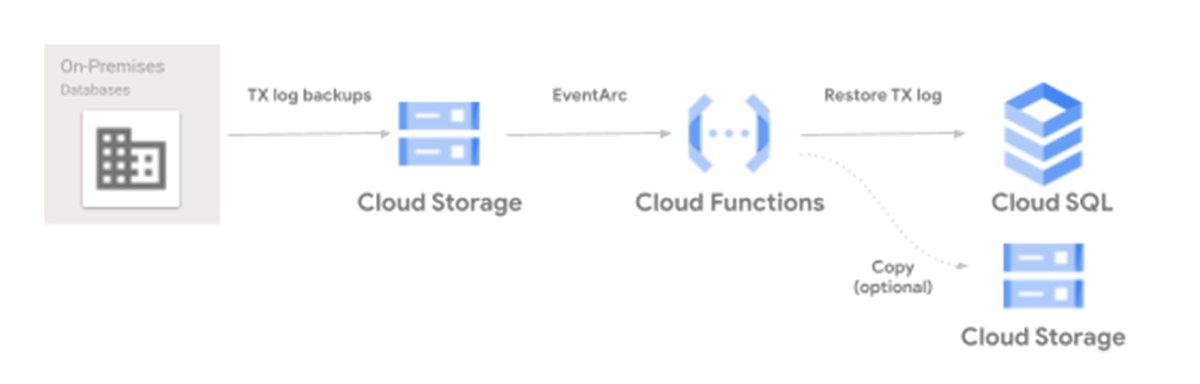
The function checks the progress of the restore operation. If the restore operation succeeds, it deletes the file from the source cloud storage bucket, optionally making a copy of it on a second storage bucket. If the operation does not succeed, the function will act depending on the type of error encountered.
Google Cloud Database Migration Service (DMS) for SQL Server automates this process of restoring full and transaction log backups to Cloud SQL for SQL Server, however its primary focus is to perform streamlined SQL Server database migrations. You can use it to establish a continuous data flow between your source SQL Server instance and Cloud SQL for SQL Server, monitor it, and migrate to Cloud SQL. For a deeper understanding of SQL Server database migrations using Google Cloud Database Migration Service (DMS) for SQL Server, refer to the Google Cloud Database Migration Service for SQL Server documentation.
Setting up this solution
First, you need to provision and set up your Cloud SQL for SQL Server instance and a Cloud Storage bucket to store your SQL Server backups. Run the following commands in your Cloud Shell.
1. If you don’t already have a SQL Server Instance, create one using the following command:
export PROJECT_ID=$(gcloud config get-value project)
gcloud sql instances create <CLOUD_SQL_INSTANCE_NAME> \
--database-version=SQLSERVER_2022_STANDARD --cpu=4 --memory=8GiB \
--zone=us-central1-a --root-password=<PASSWORD> \
--project=${PROJECT_ID} \
--network=projects/$PROJECT_ID/global/networks/<VPC_NETWORK_NAME> \
--no-assign-ip
2. Use the gcloud describe command to get the service account information of your Cloud SQL Instance
gcloud sql instances describe <CLOUD_SQL_INSTANCE_NAME>
Note the serviceAccountEmailAddress field value. You need it later. It should be something in the form of p*******-****@******.iam.gserviceaccount.com.
3. You need a Cloud Storage bucket to upload your full and transaction log backup files:
gcloud storage buckets create gs://<BUCKET_NAME> \
--project=${PROJECT_ID} \
--location=<BUCKET_LOCATION> \
--public-access-prevention
4. Grant objectViewer rights for the Cloud SQL service account on the bucket you just created:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:<service-account-email-address>" \
--role="roles/storage.objectViewer"
5. Now, you create a cloud function that triggers when a new object is uploaded to the bucket. First, create a service account for the function:
gcloud iam service-accounts create cloud-function-sql-restore-log --display-name "Service Account for Cloud Function and SQL Admin API"
6. Create a role called Cloud SQL import that has rights to perform imports on Cloud SQL instances and can also orchestrate files on the buckets.
gcloud iam roles create cloud.sql.importer \
--project ${PROJECT_ID} \
--title "Cloud SQL Importer Role" \
--description "Grant permissions to import and synchronize data from a cloud storage bucket to a Cloud SQL instance" \
--permissions "cloudsql.instances.get,cloudsql.instances.import,eventarc.events.receiveEvent,storage.buckets.get,storage.objects.create,storage.objects.delete,storage.objects.get"
7. Attach the Cloud SQL import role to the Cloud function service account.
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:cloud-function-sql-restore-log@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="projects/${PROJECT_ID}/roles/cloud.sql.importer"
8. Deploy the cloud function that triggers when a new object is uploaded to the bucket. The function will restore the full and transaction log backup files and also handle the file synchronization on the bucket. Run the following instructions in the Cloud Shell or in an environment of your choice where you have installed gcloud CLI:
-
Clone the SQL Server restore cloud function repository:
git clone https://github.com/google/example-demos-for-msft-workloads.git
-
Navigate to the restore-sql-server-transaction-logs/Function folder
cd example-demos-for-msft-workloads/restore-sql-server-transaction-logs/Function
-
From the restore-sql-server-transaction-logs/Function folder, run the following gcloud command to deploy the cloud function:
gcloud functions deploy <CLOUD_FUNCTION_NAME> \
--gen2 \
--region=<REGION_NAME> \
--retry \
--runtime=python312 \
--source=. \
--timeout=540 \
--entry-point=fn_restore_log \
--set-env-vars USE_FIXED_FILE_NAME_FORMAT=False,PROCESSED_BUCKET_NAME=,MAX_OPERATION_FETCH_TIME_SECONDS=30 \
--no-allow-unauthenticated \
--trigger-bucket="<BUCKET_NAME>" \
--service-account cloud-function-sql-restore-log@${PROJECT_ID}.iam.gserviceaccount.com
9. To invoke an authenticated function, the underlying principal must have the invoker IAM permission. Assign the Invoker role (roles/run.invoker) through Cloud Run for 2nd gen functions to the function’s service account:
gcloud functions add-invoker-policy-binding <CLOUD_FUNCTION_NAME> \
--region="<REGION_NAME>" \
--member="serviceAccount:cloud-function-sql-restore-log@${PROJECT_ID}.iam.gserviceaccount.com"
10. Upload a full backup of your SQL Server on-prem database to the bucket that you created earlier.
The function needs certain information to make the proper request for restoring the uploaded backup file to the Cloud SQL for SQL Server instance. This information includes:
-
Target Cloud SQL Instance name
-
Database name
-
Backup type (full, differential or transaction log backup)
-
Information if the backup should be restored with the recovery option or not (leaving the database ready to perform subsequent restores in case of no recovery used)
There are two ways for the function to get this information: Either from the file name itself or from object metadata. To enable the function to use the file name functionality, set the USE_FIXED_FILE_NAME_FORMAT environment variable to "True". In this way, the function expects all the uploaded backup files to have a fixed name pattern from which it infers the needed information. If you are going with this option, the name of the file might be:
<CLOUD_SQL_INSTANCE_NAME>_<DB_NAME>_[Full/Diff]_[Recovery].BAK
The [Full/Diff] and [Recovery] groups are optional. If they are not specified, the TLOG backup type and NORECOVERY options are used.
Alternatively, set the USE_FIXED_FILE_NAME_FORMAT parameter to False and set the following metadata when you upload the backup files:
-
CloudSqlInstance - The name of the cloud sql for sql server instance where the restore request is made. Mandatory.
-
DatabaseName - The name of the database where the function executes the restore operation. Mandatory.
-
BackupType - This is the backup type. Can be only "FULL", "DIFF" or "TLOG". Mandatory.
-
Recovery - This is the recovery type. Can be only "True" or "False". Mandatory.
11. Upload the file to Cloud Storage:
gcloud storage cp <OBJECT_LOCATION> gs://<BUCKET_NAME>
Replace <OBJECT_LOCATION> with the full path to your full backup file.
12. Check if the function triggered successfully. To do that, you can inspect the logs of the function by using the following gcloud command:
gcloud functions logs read <CLOUD_FUNCTION_NAME> --region=<REGION_NAME>
13. You can also connect to your Cloud SQL for SQL Server instance using the SQL Server Management Studio. If the restore of the full backup was done successfully, you will see something similar to this:
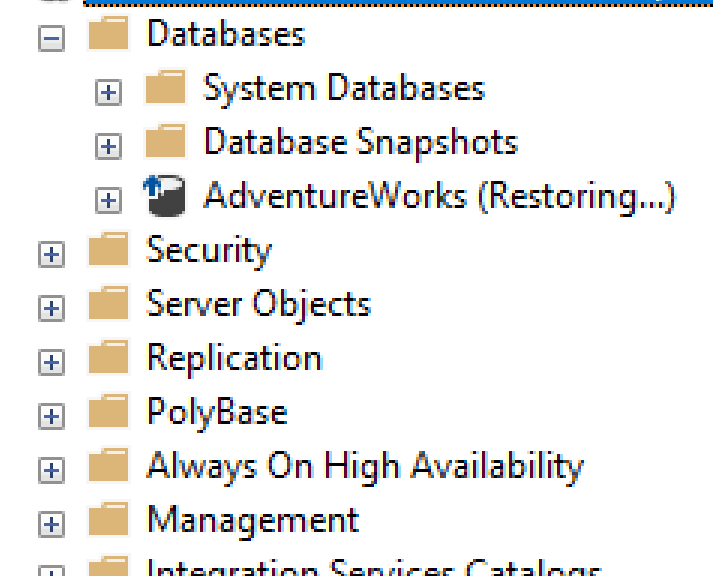
Alternatively, you can manually import the full backup with the --no-recovery argument using the gcloud command.
In SQL Server, when the restore with no recovery option is used, the uncommitted transactions are kept, allowing roll forwards through subsequent backup restores. The downside is that users are prohibited from accessing that database. In our case, we want to apply further restores of transaction log backups, so we will use the no-recovery option.
For more information about importing full backups, see Import data from a BAK file to Cloud SQL for SQL Server documentation.
At this point, you have successfully deployed a Cloud Function that restores full, differential or transaction log backups whenever they get uploaded to Cloud Storage. However, to have your Cloud SQL for SQL Server serve as a DR instance, you need to set up an automated way of uploading the transaction logs to Cloud Storage. First, you need to create a service account that has rights to upload files to the bucket. You use service account impersonation:
1. Create a service account:
gcloud iam service-accounts create tx-log-backup-writer \
--description="Account that writes transaction log backups to Cloud Storage" \
--display-name="tx-log-backup-writer"
2. Grant rights on the service account to create and view objects on the bucket.
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage buckets add-iam-policy-binding gs://<BUCKET_NAME> --member=serviceAccount:tx-log-backup-writer@${PROJECT_ID}.iam.gserviceaccount.com --role=roles/storage.objectAdmin
3. Provide access for your local Google Cloud user (or service account) to impersonate the service account you just created earlier:
gcloud iam service-accounts add-iam-policy-binding tx-log-backup-writer@${PROJECT_ID}.iam.gserviceaccount.com \
--member="user:<YOUR_GOOGLE_CLOUD_USER>" \
--role=roles/iam.serviceAccountTokenCreator
Alternatively you can create a new user specific for this purpose. For more information about service account impersonation, see Use service account impersonation.
Perform the following actions on a machine with read access to the transaction log backup files:
1. Create a folder on a machine with access to the transaction log backup files. Inside the folder, clone the contents from the scheduled-upload folder of the repository.
git clone https://github.com/google/example-demos-for-msft-workloads.git
2. Navigate to the restore-sql-server-transaction-logs/scheduled-upload folder:
cd example-demos-for-msft-workloads/restore-sql-server-transaction-logs/scheduled-upload
3. Edit the upload-script.ps1 file and change the value of the constants as follows:
New-Variable -Name LocalPathForBackupFiles -Value "" -Option Constant
New-Variable -Name BucketName -Value "" -Option Constant
New-Variable -Name AccountName -Value "" -Option Constant
-
LocalPathForBackupFiles - is the folder which the script will look for new files for upload.
-
BucketName - is the name of the cloud storage bucket where the files will be uploaded.
-
AccountName - is the name of the service account that is impersonated.
4. Install the gcloud CLI if not already installed.
5. Acquire new user credentials for your Application Default Credentials by running the command
gcloud auth application-default login
Login with your Google Cloud user for which you set up impersonation.
6. Create a scheduled task so that the script is called regularly. For example, the scheduled task below script starts execution at 2:45 PM and runs every minute. Replace <username> with a local user account with privileges to read and edit the settings.json file files on your machine.
schtasks /create /sc minute /mo 1 /tn "Cloud Storage Upload script" /tr "powershell <full-path-to-the-upload-script>" /st 14:45 /ru <local_account_username> /rp
Note: You will be prompted to provide the password for the local <local_account_username> when you create the task.
The powershell script uploads every minute only new transaction log backup files from your specified folder to Cloud Storage.
You can monitor the execution of the function and set up alerting based on execution count. For example, you can set up an alert if the function did not execute successfully in the last 10 minutes. For more information about monitoring, see Monitor your Cloud Function and Cloud functions metrics.
Note: You can also set up a Storage Transfer Service job to automate the transfer of your backup files from a local file system or from a compatible Cloud Storage location to your Google Cloud Storage bucket. For more information, see What is Storage Transfer Service?
When performing a DR switch, you want to have your database accessible. For that, you need to restore a valid backup file with the recovery option set to true. For example, you could use the last successfully restored transaction log backup. Depending on the fixed file name format setting used, rename the backup file so that it contains the string “_recovery” or set the value of the metadata key “Recovery” to “True” when uploading the file to the Cloud Storage bucket.
Once you've restored the health of your initial primary instance and determined it's suitable for a fallback, you'll need to synchronize data from your Cloud SQL DR instance. Then, during a low-workload period, switch your applications to connect to the restored primary instance.
To synchronize your DR instance with the former primary instance, consider these methods:
-
Restore from backups: Utilize full and differential database backups from your Cloud SQL for SQL Server instance.
-
Replication setup: Establish replication from your Cloud SQL for SQL Server DR instance to the former primary.
For more information about exporting or replicating data from Cloud SQL for SQL Server, see Export data from Cloud SQL for SQL Server and Replicating your data from Cloud SQL for SQL Server. In any fallback scenario, we advise you to conduct thorough testing to ensure that the fallback doesn't introduce any new issues or cause disruptions to operations.
In conclusion, implementing a DR instance of your existing SQL Server on Google Cloud is a strategic approach to enhance the resilience of your database infrastructure. It helps ensure business continuity, safeguards against data loss, and provides a scalable and secure environment for critical applications.


