Cloud Bigtable under the hood: How we improved single-row read throughput by 20-50%
Gabor Dinnyes
Bigtable Software Engineer
Nick Suttle
Bigtable Software Engineering Manager
Bigtable is a scalable, distributed, high-performance NoSQL database that processes more than 6 billion requests per second at peak and has more than 10 Exabytes of data under management. Operating at this scale, Bigtable is highly optimized for high-throughput and low-latency reads and writes. Even so, our performance engineering team continually explores new areas to optimize. In this article, we share details of recent projects that helped us push Bigtable’s performance envelope forward, improving single-row read throughput by 20-50% while maintaining the same low latency.
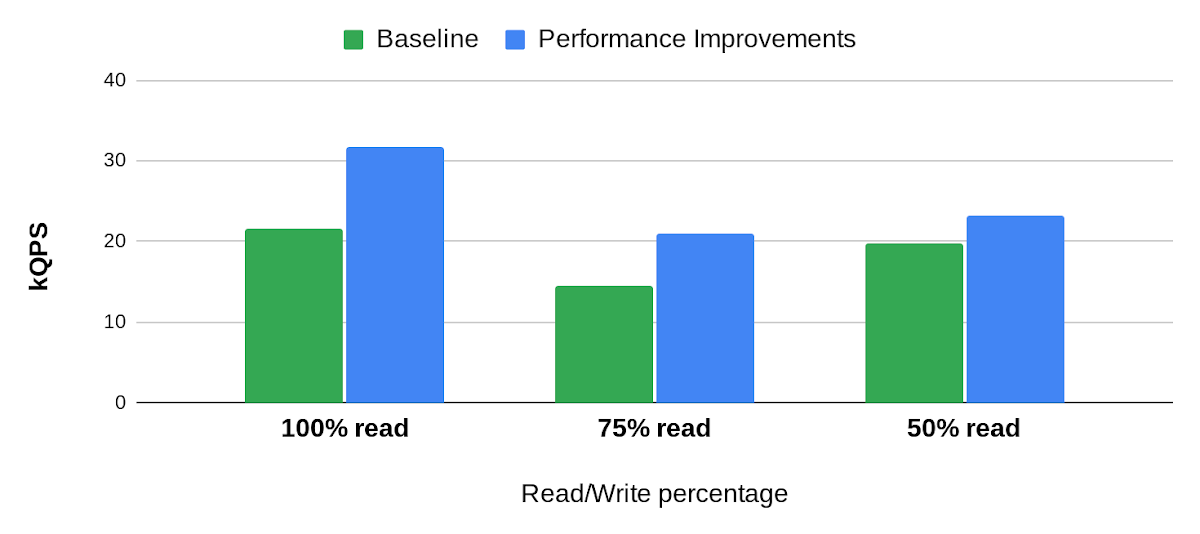
Below is an example of the impact we delivered to one of our customers, Snap. The compute cost for this small-point read-heavy workload reduced by 25% while maintaining the previous level of performance.
Performance research
We use a suite of benchmarks to continuously evaluate Bigtable’s performance. These represent a broad spectrum of workloads, access patterns and data volumes that we see across the fleet. Benchmark results give us a high-level view of performance opportunities, which we then enhance using sampling profilers and pprof for analysis. This analysis plus several iterations of prototyping confirmed feasibility of improvements in the following areas: Bloom filters, prefetching, and a new post-link-time optimization framework, Propeller.
Bloom filters
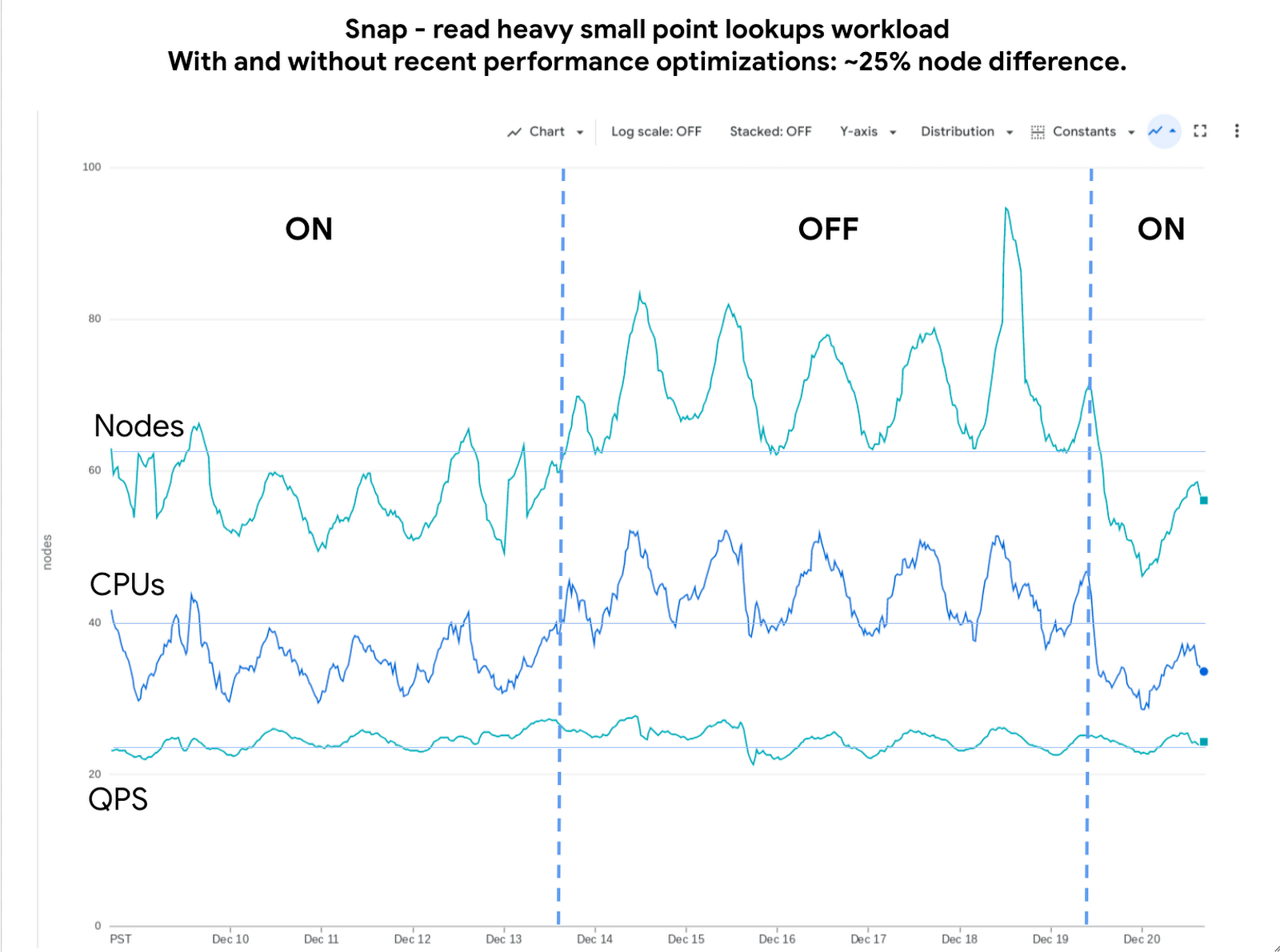
Bigtable stores its data in a log-structured merge tree. Data is organized into row ranges and each row range is represented by a set of SSTables. Each SSTable is a file that contains sorted key-value pairs. During a point-read operation, Bigtable searches across the set of SSTables to find data blocks that contain values relevant to the row-key. This is where the Bloom filter comes into play. A Bloom filter is a space-efficient probabilistic data structure that can tell whether an item is in a set, it has a small number of false positives (item may be in the set), but no false negatives (item is definitely not in the set). In Bigtable’s case, Bloom filters reduce the search area to a subset of SSTables that may contain data for a given row-key, reducing costly disk access.
We identified two major opportunities with the existing implementation: improving utilization and reducing CPU overhead.
First, our statistics indicated that we were using Bloom filters in a lower than expected percentage of requests. This was due to our Bloom filter implementation expecting both the “column family” and the “column” in the read filter, while a high percentage of customers filter by “column family” only — which means the Bloom filter can’t be used. We increased utilization by implementing a hybrid Bloom filter that was applicable in both cases, resulting in a 4x increase in utilization. While this change made the Bloom filters larger, the overall disk footprint increased by only a fraction of a percent, as Bloom filters are typically two orders of magnitude smaller than the data they represent.
Second, the CPU cost of accessing the Bloom filters was high, so we made enhancements to Bloom filters that optimize runtime performance:
Local cache for individual reads: When queries select multiple column families and columns in a single row, it is common that the query will use the same Bloom filter. We take advantage of this by storing a local cache of the Bloom filters used for the query being executed.
Bloom filter index cache: Since Bloom filters are stored as data, accessing them for the first time involves fetching three blocks — two index blocks and a data block — then performing a binary search on all three. To avoid this overhead we built a custom in-memory index for just the Bloom filters. This cache tracks which Bloom filters we have in our block cache and provides direct access to them.
Overall these changes decreased the CPU cost of accessing Bloom filters by 60-70%.
Prefetching
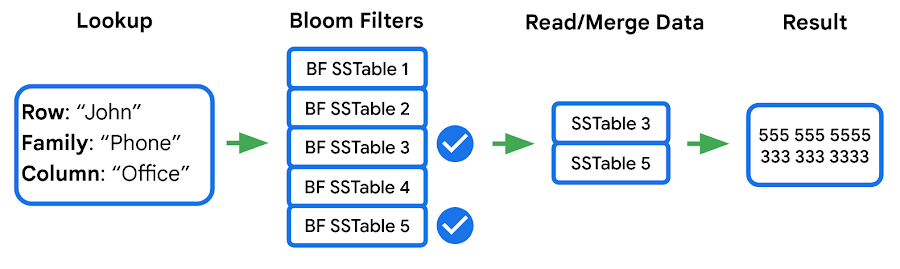
In the previous section we noted that data for a single row may be stored in multiple SSTables. Row data from these SSTables is merged into a final result set, and because blocks can either be in memory or on disk, there’s a risk of introducing additional latency from filesystem access. Bigtable’s prefetcher was designed to read ahead of the merge logic and pull in data from disk for all SSTables in parallel.
Prefetching has an associated CPU cost due to the additional threading and synchronization overhead. We reduced these costs by optimizing the prefetch threads through improved coordination with the block cache. Overall this reduced the prefetching CPU costs by almost 50%.
Post-link-time optimization
Bigtable uses profile guided optimizations (PGO) and link-time optimizations (ThinLTO). Propeller is a new post-link optimization framework released by Google that improves CPU utilization by 2-6% on top of existing optimizations.
Propeller requires additional build stages to optimize the binary. We start by building a fully optimized and annotated binary that holds additional profile mapping metadata. Then, using this annotated binary, we collected hardware profiles by running a set of training workloads that exercise critical code paths. Finally, using these profiles as input, Propeller builds a new binary with an optimized and improved code layout. Here is an example of the improved code locality.
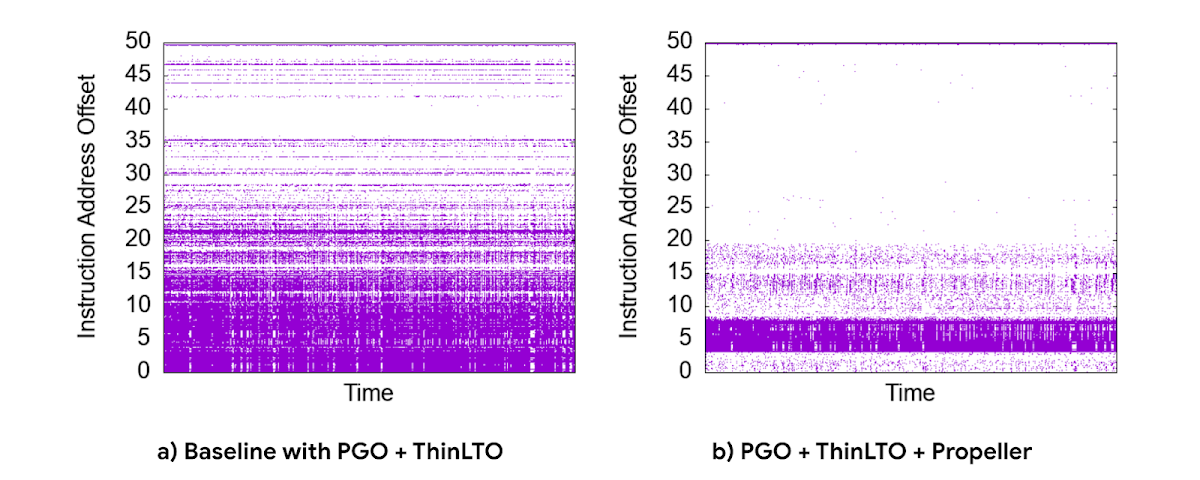
The new build process used our existing performance benchmark suite as a training workload for profile collection. The Propeller optimized binary showed promising results in our tests, showing up to 10% improvement in QPS over baseline.
However, when we released this binary to our pilot production clusters, the results were mixed. It turned out that there was overfitting for the benchmarks. We investigated sources of regression by quantifying profile overlap, inspecting hardware performance counter metrics and applied statistical analysis for noisy scenarios. To reduce overfitting, we extended our training workloads to cover a larger and more representative set of use cases.
The result was a significant improvement in CPU efficiency — reducing fleetwide utilization by 3% with an even more pronounced reduction in read-heavy workloads, where we saw up to a 10% reduction in CPU usage.
Conclusion
Overall, single-row read throughput increased by 20-50% whilst maintaining the same latency profile. We are excited about these performance gains, and continue to work on improving the performance of Bigtable. Click here to learn more about Bigtable performance and tips for testing and troubleshooting any performance issues you may encounter.

