Saving the day: How Cloud SQL makes data protection easy
Nimesh Bhagat
Product Management, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialIf you’re managing a crucial application that has to be fully fault-tolerant, you need your system to be able to handle every fault, no matter the type and scope of failure, with minimal downtime and data loss. Protecting against these faults means juggling numerous variables that can impact performance as well as recovery time and cost.
Today’s managed database services take over the operational complexity that used to exist for database administrators. Growing your organization’s tolerance required adding machines, compute, and storage, plus the operational costs of IT management: performing backups, writing scripts, creating dashboards, and carrying out testing to make sure your platform is ready when problems arise--all in a secure way.
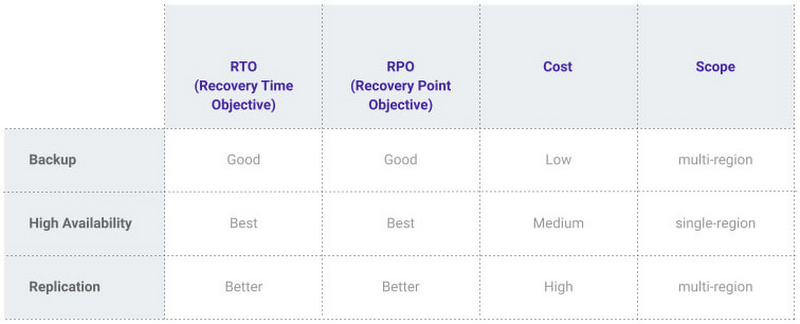
At Google, our Cloud SQL managed database service offers three fault tolerance mechanisms —backup, high availability, and replication—and there are three major factors to consider for each of them:
RTO (recovery time objective): When a failure happens, how much time can be lost before significant harm occurs?
RPO (recovery point objective): When a failure happens, how much data can be lost before significant harm occurs?
Cost: How cost-effective is this solution?
We’ve heard from customers like Major League Baseball, HSBC, and Equifax that they have strict data-protection needs and require highly fault-tolerant multi-region applications—and they’ve all chosen Cloud SQL to meet those needs.
Let’s take a closer look at how the decision-making process plays out for each recovery solution.
High availability (HA)
If your application is business critical, you require minimum RTO and zero RPO— a high availability configuration ensures that you and your customers are protected. If the primary instance fails, there’s another standby instance ready to take over with no data loss. There’s an additional cost here, but doing this manually brings a great operational cost, since you have to detect and verify the fault, do the failover, and make sure it’s correct—you can’t have two primary instances or you risk data corruption—then finally connect the application to the new database.Cloud SQL removes all that complexity. Choose high availability for a given instance and we’ll replicate the data across multiple zones, synchronously, to each zone’s persistent disk. If an HA instance has a failure, you don’t have to think about when to fail over because Cloud SQL detects the failure and automatically initiates failover, for a full recovery and no data loss within minutes. Cloud SQL also moves the IP address during failover so your application can easily reconnect. MLB, for example, uses Cloud SQL high availability to serve prediction data to live games with minimal downtime. Dev/test instances don’t need those same guarantees, but can use local backups to recover from any potential failure.
Cross-region replica
If a whole Google Cloud region goes down you still need your business to continue to run. That’s where cross-region replication comes in, a hot standby replica in another Google Cloud region provides RTO of minutes and RPO typically less than a minute . If you create a read replica in a region separate from your primary instance and you get hit with a regional outage, your application and database can start serving customers from another region within minutes. But this solution can be complex and enabling it yourself can be difficult and time-consuming. Securing cross-geography traffic demands end-to-end encryption and can bring connectivity issues too.This is where the fully managed Cloud SQL solution shines. We offer MySQL, PostgreSQL and SQL Server database engines as a cross-region replication solution that’s easily configured and bolstered by Google’s interconnected global network. Just say, “I'm in U.S. East, I want to create a replica in U.S. West,” and it’s done, reliably and securely.
Backup
When you suffer data loss because of an operations error (for example, a bug in a script dropped your tables) or human error (for example, someone dropped the wrong table by accident), backups help you restore lost data to your Cloud SQL instance. Our low cost backup mechanism features point-in-time, granular recovery, meaning that if you accidentally delete data or something else goes wrong, you can ask for recovery of, for example, the state of that database down to the millisecond, such as Monday at 12:53pm. Your valuable data is replicated multiple times in multiple geographic locations automatically. This enables the automatic handling of failover in cases of major failure. You can always rest assured that your database is available and data is secure, even in the times of major failure crises.Cloud SQL provides automated and on-demand backups. With automated backups, Google manages the backups so that you can easily restore them when required. Also, the scheduled backing is automatically taken by default. With on-demand backup, you can create a backup at any time. This could be useful if you are about to perform a risky operation on your database, as Cloud SQL lets you select a custom location for your backup data. When the backup is stored in multiple regions, and there's an outage in the region that contains the source instance, you can restore a backup to a new or existing instance in a different region. This is also useful if your organization needs to comply with data residency regulations that require you to keep your backups within a specific geographic boundary.
Putting it all together
For critical workloads, MLB configures their Cloud SQL instances with backups, high availability, and cross-region replication. Doing so ensures they can recover from many failure types.
To recover from human error (“Oops, I didn’t mean to delete that”), MLB uses backups and point-in-time recovery to recovery to a millisecond or specific database transaction
To automatically recover from primary instance failures and zonal outages, MLB uses Cloud SQL’s high availability configuration
To protect against regional outages, MLB uses cross-region replication
Creating a robust configuration, like MLB did, takes just a few minutes. Get started in our Console or review documentation.


