Benchmarking Spanner’s price-performance for key-value workloads
Suraj Pasuparthy
Senior Software Engineer
Lokesh Agarwal
Staff Software Engineer
In today’s competitive business landscape, cost is a crucial factor for success. Spanner is Google’s fully managed database service for both relational and non-relational workloads, offering strong consistency at a global level, high performance at virtually unlimited scale, and high availability with an up to five-nines SLA. Spanner is a versatile database that caters to a vast array of workloads, powering some of the world’s most popular products. And with Spanner’s recent price performance improvements, it’s even more affordable, due to improved throughput and storage per node.
In this blog post, we will demonstrate how we benchmark a subset of these workloads, key-value workloads, using the industry-standard Yahoo! Cloud Serving Benchmark (YCSB) benchmark. YCSB is an open-source benchmark suite for evaluating and comparing the performance of key-value workloads across different databases. While Spanner is often associated with relational workloads, key-value workloads are also common on Spanner among industry-leading enterprises.
Spoiler alert
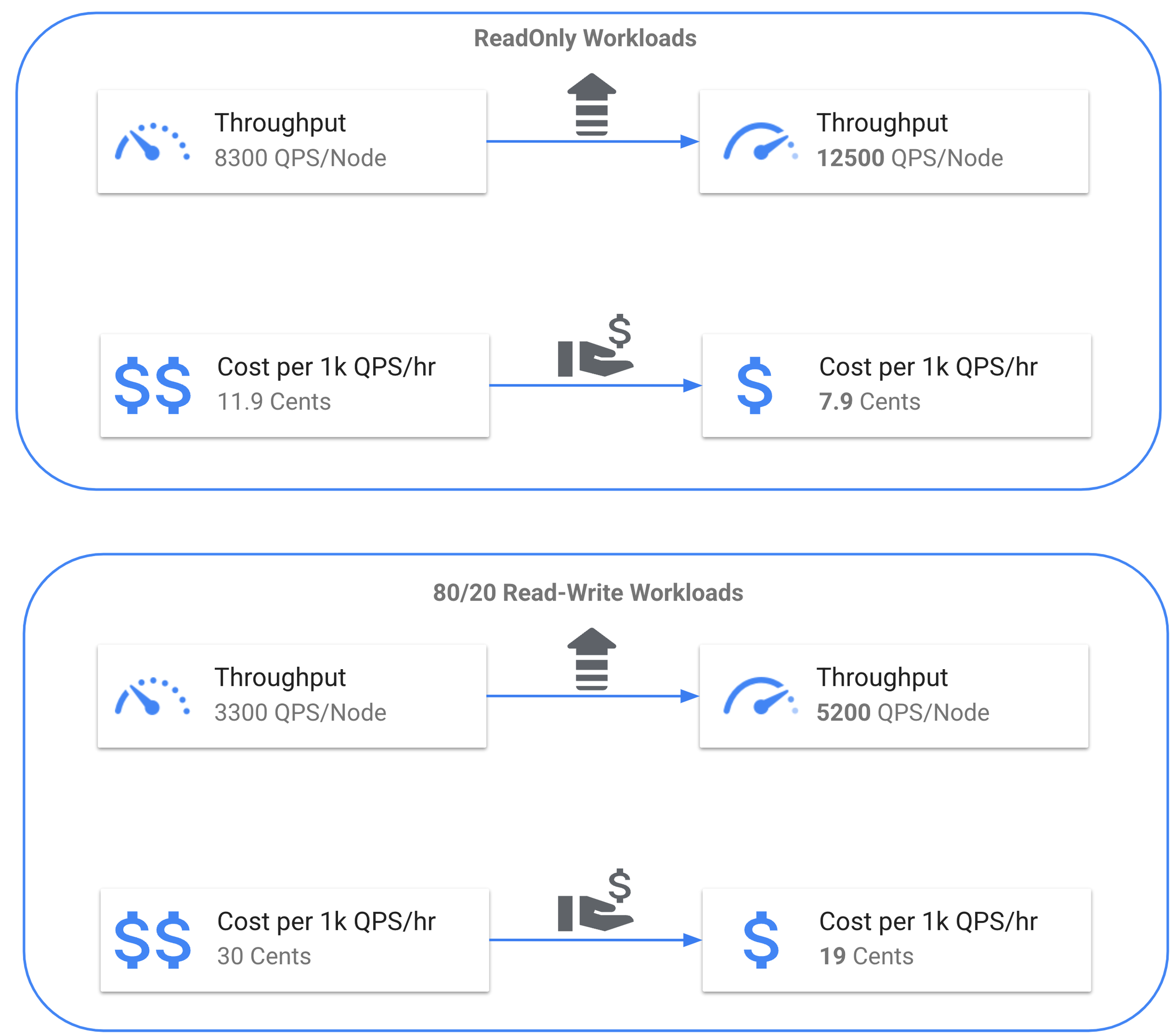
The results show that our recent price-performance improvements provide at least a 50% increase in throughput per node, with no change in overall system costs. When running at the recommended CPU utilization in regional configurations, this throughput is delivered with single-digit millisecond latency.
With that out of the way, let’s dig deeper into the YCSB benchmarking setup that we used to derive the above results.
Methodology
We used the YCSB benchmark on Spanner to run these benchmarks.
Workload characteristics
We want to mimic typical production workloads with our benchmark. To that end, we picked the following characteristics:
- Read staleness: Read workload comparison is based on “consistent/strong reads” and not “stale/snapshot” reads.
- Read/write ratio: The evaluation was done for a 100% read-only workload and a 80/20 split read/write workload.
- Data distribution: We use the Zipfian distribution for our benchmarks since it more closely represents real-world scenarios.
- Dataset size: A workload dataset size of 1TB was used for this benchmark. This ensures that most requests will not be served from memory.
- Instance configuration: We used a three-node Spanner instance in a regional instance configuration
- CPU utilization: We present here two sets of benchmarks: the first set of benchmarks run at the recommended 65% CPU utilization for latency-sensitive and fail-over safe workloads; a second set of benchmarks runs at near 100% CPU utilization to maximize Spanner’s throughput. The performance numbers at 100% CPU utilization are also published in our public documentation.
- Client VMs: We used Google Compute Engine to host the client VMs, which are co-located in the same region as the Spanner instance.
Price-performance Metric
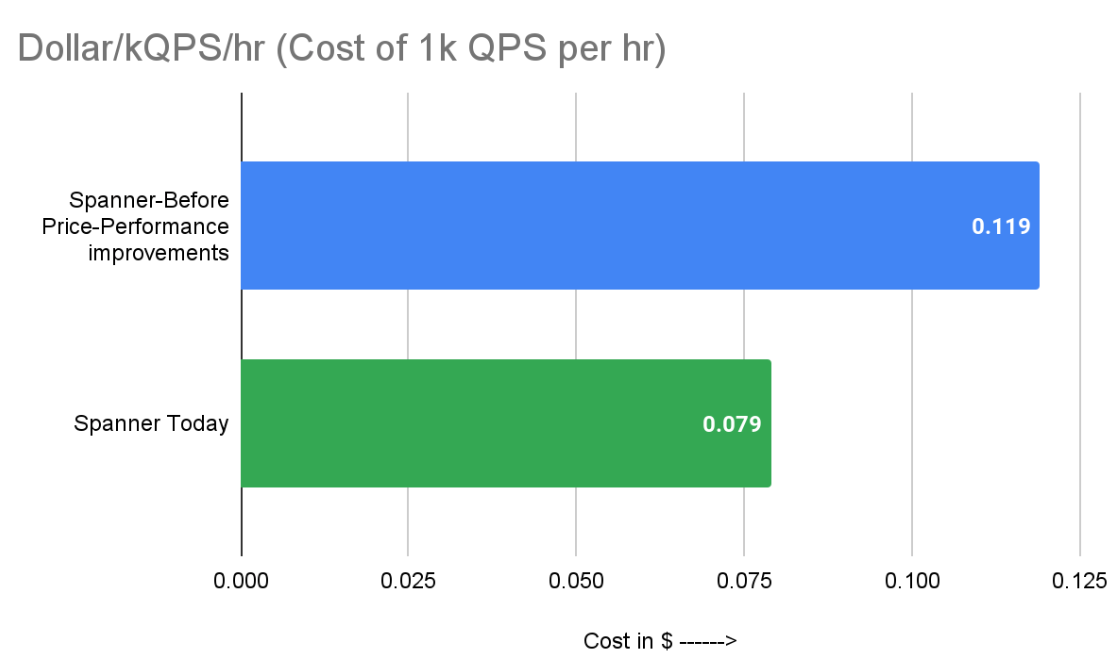
To simplify cost estimates, we introduce a normalized metric called "Dollars per kQPS-Hr." Simply put, this is the hourly cost for sustaining 1k QPS for a given workload.
Pricing
Spanner’s cost is determined by the amount of compute provisioned by the customer. For example, a single-node regional instance in us-east4 costs $0.99 per hour. For the results that we present here, we consider the cost of a Spanner node without any discounts for long-term committed usage, e.g., committed use discounts. Those discounts would only make price-performance better, due to reduced cost per node. For more details on Spanner pricing, please refer to the official pricing page.
For simplicity, we also exclude storage costs from our pricing calculations, since we are measuring the cost of each additional “thousand” QPS.
Results
Benchmarks at recommended CPU utilization
The results below show reduction in costs for different workloads due to the ~50% improvement in throughput per node.
Benchmark 1: 100% Reads
YCSB Configuration: We used the Workloadc.yaml configuration in the recommended_utilization_benchmarks folder to run this benchmark.
Deriving the metric for Spanner: A three-node Spanner instance with a preloaded 1TB of data produced a throughput of 37,500 QPS at the recommended 65% CPU utilization. This equates to 12,500 QPS per Spanner node.
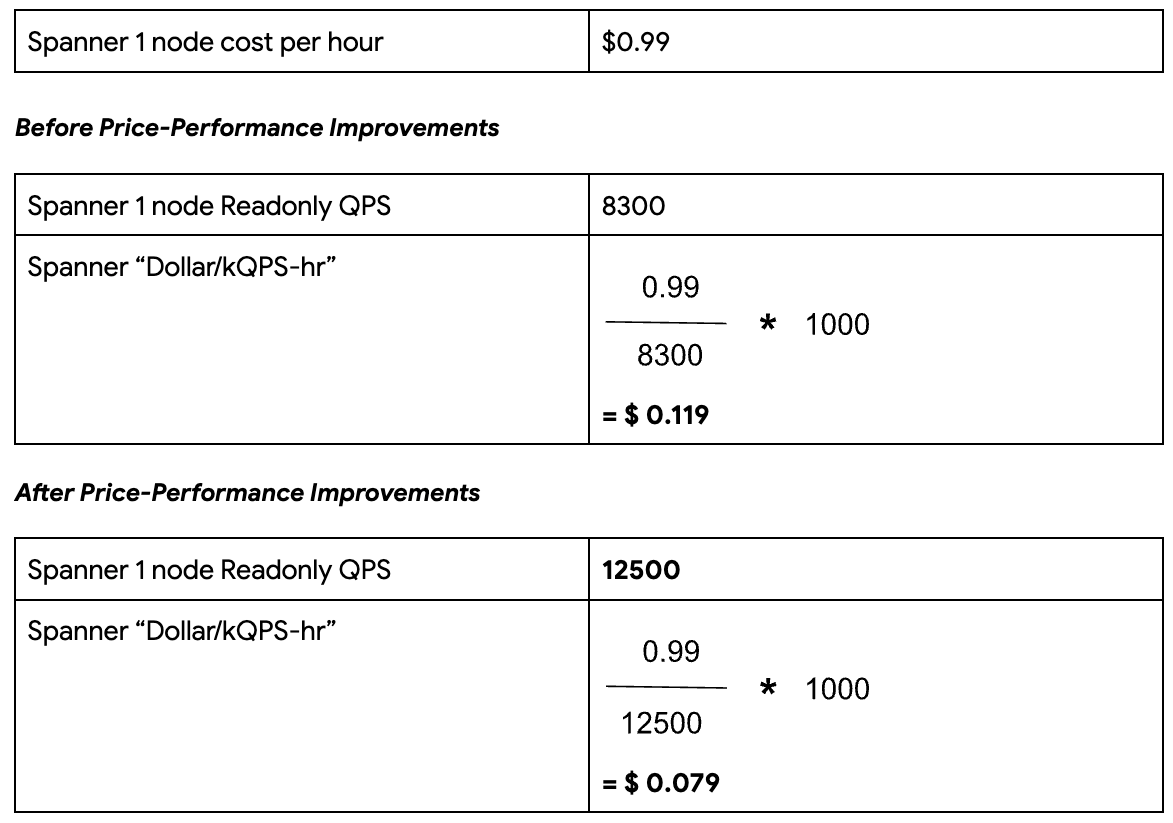
It now costs just 7.9 cents to sustain 1k read QPS for one hour in Spanner.
Benchmark 2: 80% Read-20% Write
YCSB Configuration: We used the ReadWrite_80_20.yaml configuration in the recommended_utilization_benchmarks folder to run this benchmark.
Deriving the metric for Spanner: A three-node Spanner instance with a preloaded 1TB of data produced a throughput of 15,600 QPS at the recommended 65% CPU utilization. This equates to 5,200 QPS per Spanner node.
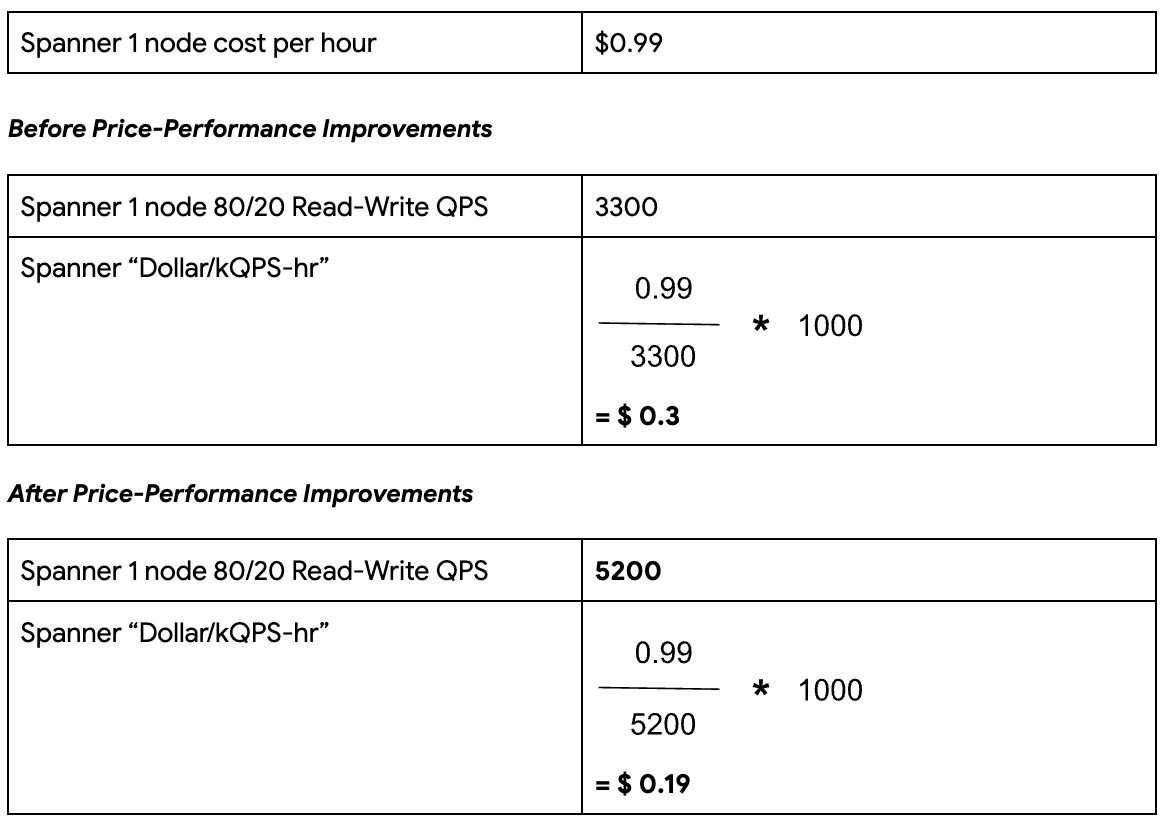
It now costs just 19 cents to sustain 1k 80/20 Read-Write QPS for one hour in Spanner.

Benchmarks at near 100% CPU utilization
Benchmark 1: 100% Reads
YCSB Configuration: We used the Workloadc.yaml configuration in the throughput_benchmarks folder to run this benchmark.
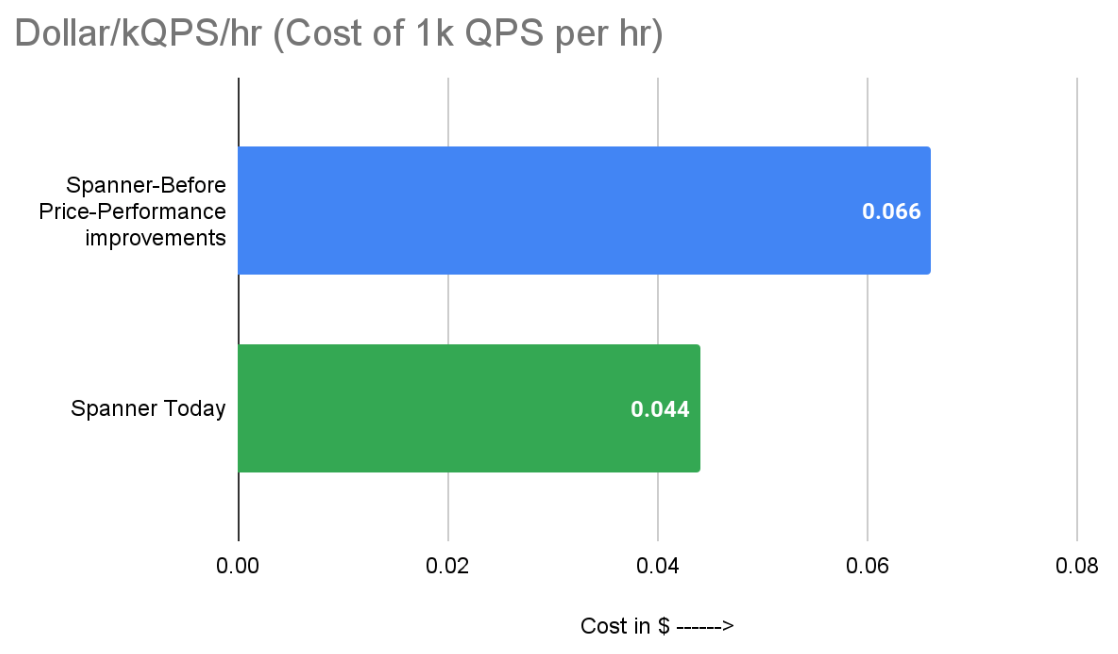
Deriving the metric for Spanner: A three-node Spanner instance with a preloaded 1TB of data produced a throughput of 67,500 QPS at near 100% CPU utilization. This equates to 22,500 QPS per Spanner node.
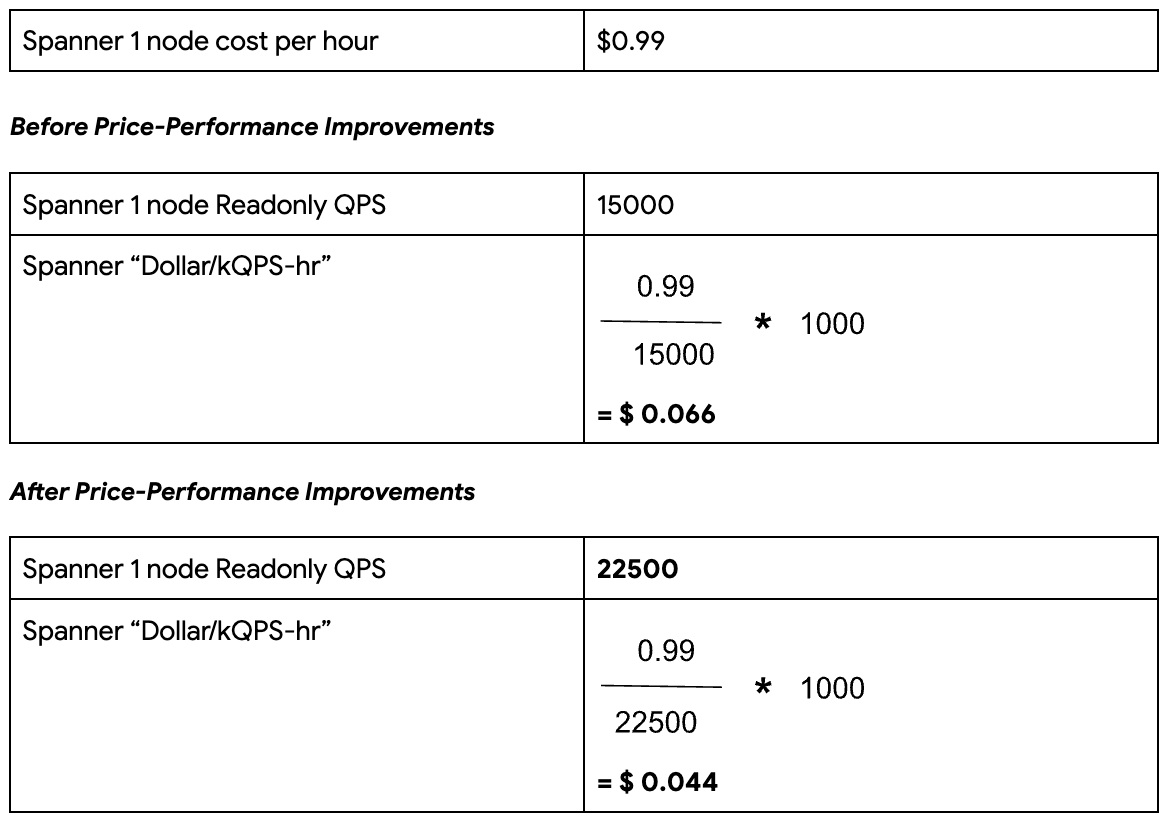
It now costs just 4.4 cents to sustain 1k Read QPS for one hour in Spanner at ~100% CPU utilization.
Benchmark 2: 80% Read-20% Write
YCSB Configuration: We used the ReadWrite_80_20.yaml configuration in the throughput_benchmarks folder to run this benchmark.
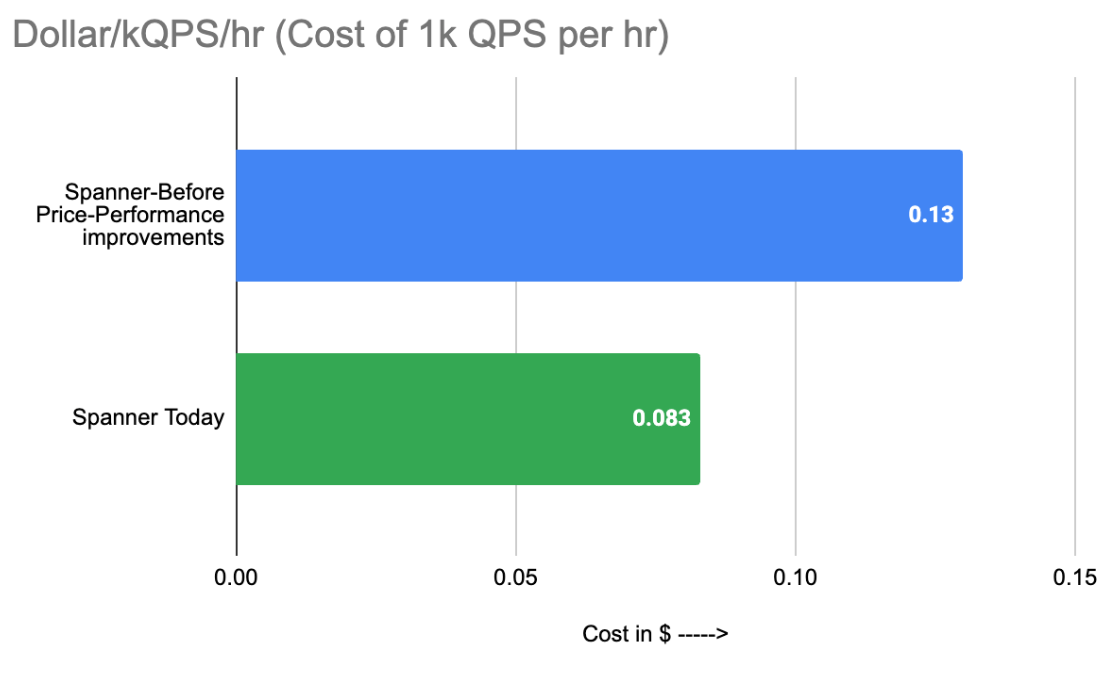
Deriving the metric for Spanner: A three-node Spanner instance with a preloaded 1TB of data produced a throughput of 35,400 QPS at near 100% CPU utilization. This equates to 11,800 QPS per Spanner node.
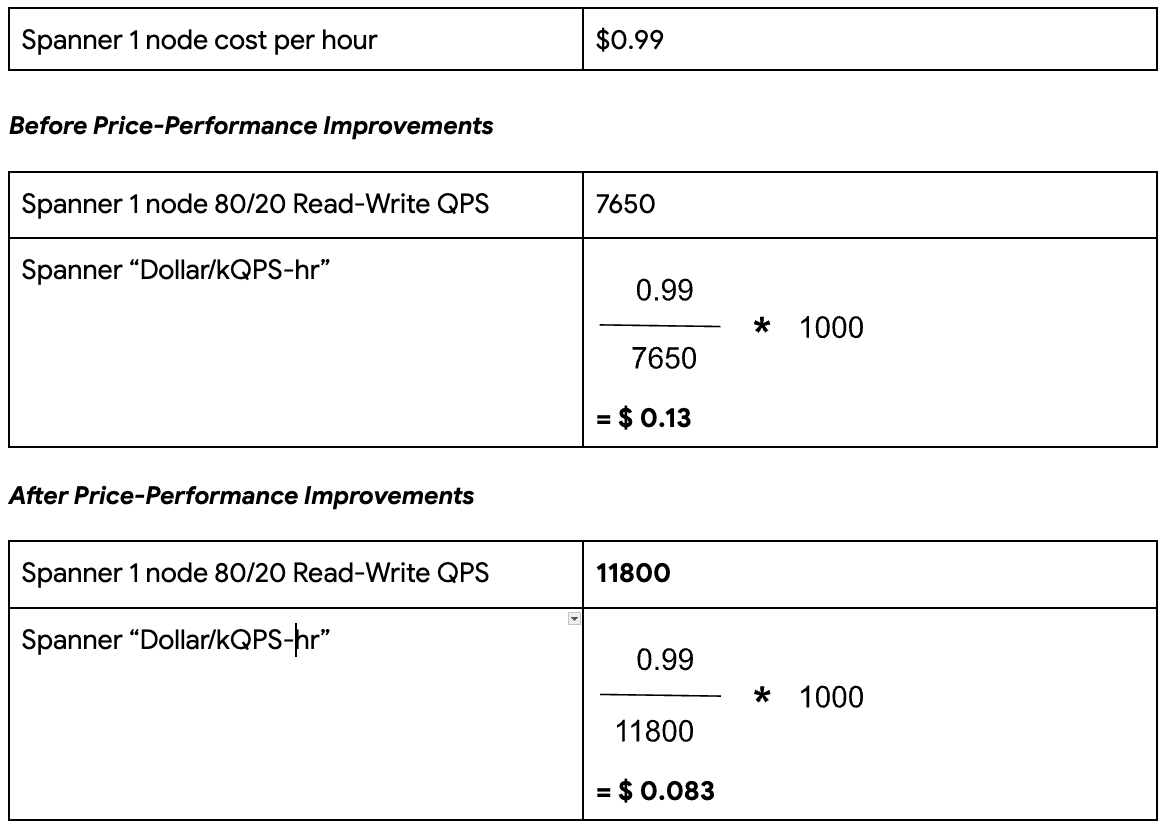
It now costs just 8.3 cents to sustain 1k 80/20 Read-Write QPS for one hour in Spanner at ~100% CPU utilization.
Your mileage may vary
Please note that benchmark results may vary slightly depending on regional configuration. For instance, in the recommended utilization benchmarks, CPU utilization may deviate slightly from the recommended 65% target due to the test's fixed QPS. However, this does not impact latency.
The 100% CPU utilization benchmarks represent the approximate theoretical limits of Spanner. In practice, the throughput can vary based on a number of factors such as system tasks, etc.
In conclusion
We recognize the importance of cost-efficiency and remain committed to performance improvements. We want customers to have access to a database that delivers strong performance, near-limitless scalability and high availability. Spanner’s recent performance improvements let customers realize cost savings through improved throughput. These improvements are available for all Spanner customers without needing to reprovision, incur downtime, or perform any user action.
Learn more about Spanner and how customers are using it today. Or try it yourself for free for 90 days, or for as little as $65 USD/month for a production-ready instance that grows with your business.
