What’s new in Cloud Pub/Sub at Next ’24

Prateek Duble
Product Management Lead, Cloud Pub/Sub
Kamal Aboul-Hosn
Tech Lead, Cloud Pub/Sub
Organizations are increasingly adopting streaming technologies, and Google Cloud offers a comprehensive solution for streaming ingestion and analytics. Cloud Pub/Sub is Google Cloud’s simple, highly scalable and reliable global messaging service. It serves as the primary entry point for you to ingest your streaming data into Google Cloud and is natively integrated with BigQuery, Google Cloud’s unified, AI-ready data analytics platform. You can then use this data for downstream analytics, visualization, and AI applications. Today, we are excited to announce recent Pub/Sub innovations answering customer needs for simplified streaming data ingestion and analytics.
One-click Streaming Import (GA)
Multi-cloud workloads are becoming a reality for many organizations where customers would like to run certain workloads (e.g., operational) on one public cloud and want to run their analytical workloads on another. However, it can be a challenge to gain a holistic view of their business data. Through data consolidation in one public cloud, you can run analytics across their entire data footprint. For Google Cloud customers it is common to consolidate data in BigQuery, providing a source of truth for the organization.
To ingest streaming data from external sources such as AWS Kinesis Data Streams into Google Cloud, you need to configure, deploy, run, manage and scale a custom connector. You also need to monitor and maintain the connector to ensure the streaming ingestion pipeline is running as expected. Last week, we launched a no-code, one-click capability to ingest streaming data into Pub/Sub topics from external sources, starting with Kinesis Data Streams. The Import Topics capability is now generally available (GA) and offers multiple benefits:
-
Simplified data pipelines: You can streamline your cross-cloud streaming data ingestion pipelines by using the Import Topics capability. This removes the overhead of running and managing a custom connector.
-
Auto-scaling: Streaming pipelines created with managed import topics scale up and down based on the incoming throughput.
-
Out-of-the-box monitoring: Three new Pub/Sub metrics are now available out-of-the-box to monitor your import topics.
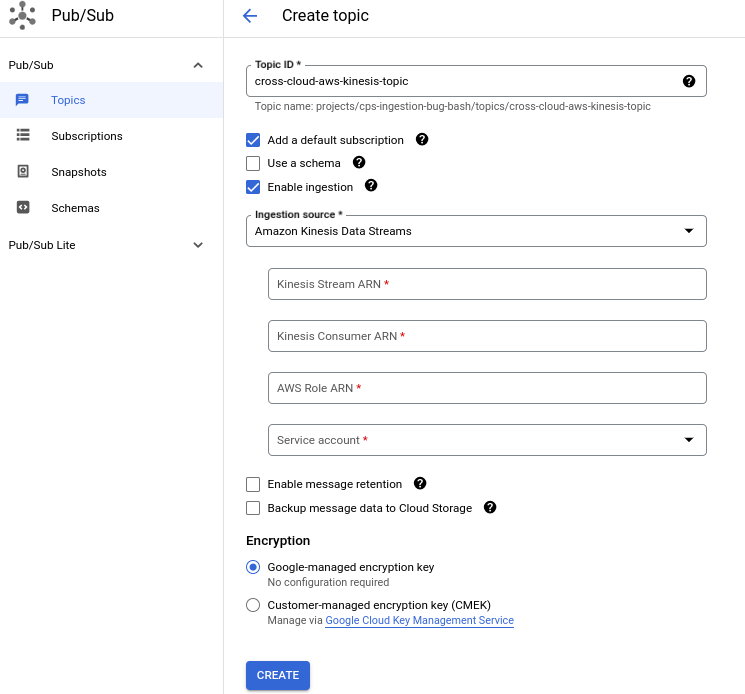
Import Topics will support Cloud Storage as another external source later in the year.
Streaming analytics with Pub/Sub Apache Flink connector (GA)
Apache Flink is an open-source stream processing framework with powerful stream and batch processing capabilities, with growing adoption across enterprises. Customers often use Apache Flink with messaging services to power streaming analytics use cases. We are pleased to announce that a new version of the Pub/Sub Flink Connector is now GA with active support from the Google Cloud Pub/Sub team. The connector is fully open source under an Apache 2.0 license and hosted on our GitHub repository. With just a few steps, the connector allows you to connect your existing Apache Flink deployment to Pub/Sub.
The connector allows you to publish an Apache Flink output into Pub/Sub topics or use Pub/Sub subscriptions as a source in Apache Flink applications. The new GA version of the connector comes with multiple enhancements. It now leverages the StreamingPull API to achieve maximum throughput and low latency. We also added support for automatic message lease extensions to enable setting longer checkpointing intervals. Finally, the connector supports the latest Apache Flink source streaming API.
Enhanced Export Subscriptions experience
Pub/Sub has two popular export subscriptions — BigQuery and Cloud Storage. BigQuery subscriptions can now be leveraged as a simple method to ingest streaming data into BigLake Managed Tables, BigQuery’s recently announced capability for building open-format lakehouses on Google Cloud. You can use this method to transform your streaming data into Parquet or Iceberg format files in your Cloud Storage buckets. We also launched a number of enhancements to these export subscriptions.
BigQuery subscriptions support a growing number of ways to move your structured data seamlessly. The biggest change is the ability to write JSON data into columns in BigQuery without defining a schema on the Pub/Sub topic. Previously, the only way to get data into columns was to define a schema on the topic and publish data that matched that schema. Now, with the use table schema feature, Pub/Sub can write JSON messages to the BigQuery table using its schema. Basic types are supported now and support for more advanced types like NUMERIC and DATETIME is coming soon.
Speaking of type support, BigQuery subscriptions now handle most Avro logical types. BigQuery subscriptions now support non-local timestamp types (compatible with the BigQuery TIMESTAMP type) and decimal types (compatible with the BigQuery NUMERIC and BIGNUMERIC types, coming soon). You can use these logical types to preserve the semantic meaning of fields across your pipelines.
Another highly requested feature coming soon to both BigQuery subscriptions and Cloud Storage subscriptions is the ability to specify a custom service account. Currently, only the per-project Pub/Sub service account can be used to write messages to your table or bucket. Therefore, when you grant access, you enable anyone who has permission to use this project-wide service account to write to the destination. You may prefer to limit access to a specific service account via this upcoming feature.
Cloud Storage subscriptions will be enhanced in the coming months with a new batching option allowing you to batch Cloud Storage files based on the number of Pub/Sub messages in each file. You will also be able to specify a custom datetime format in Cloud Storage filenames to support custom downstream data lake analysis pipelines. Finally, you’ll soon be able to use topic schema to write data to your Cloud Storage bucket.
Getting started
We’re excited to introduce a set of new capabilities to help you leverage your streaming data for a variety of use cases. You can now simplify your cross-cloud ingestion pipelines with Managed Import. You can also leverage Apache Flink with Pub/Sub for streaming analytics use cases. Finally, you can now use enhanced Export Subscriptions to seamlessly get data in either BigQuery or Cloud Storage. We are excited to see how you use these Pub/Sub features to solve your business challenges.
