Reduce costs and improve job run times with Dataproc autoscaling enhancements
Sagar Narla
Deependra Patel
Senior Software Engineer
Dataproc is a fully managed and highly scalable service for running Apache Hadoop, Apache Spark, and 30+ open source tools and frameworks. Google Cloud customers use Dataproc autoscaling to dynamically scale clusters to meet workload needs and reduce costs. In July 2023, Dataproc released several autoscaling improvements that enhance:
- Responsiveness - improved autoscaling operation speed
- Performance - reduced autoscaling operation duration
- Reliability - fewer autoscaling cluster error occurrences
- Observability - logged descriptive autoscaler recommendations
To demonstrate the potential impact of these enhancements, we ran a test that executed the same set of Spark jobs on two clusters — one cluster with all the autoscaling enhancements, and another without any of the enhancements. The new Dataproc autoscaling enhancements, in our tests, reduced cluster VM costs by up to 40%* and reduced cumulative job runtime by 10%.
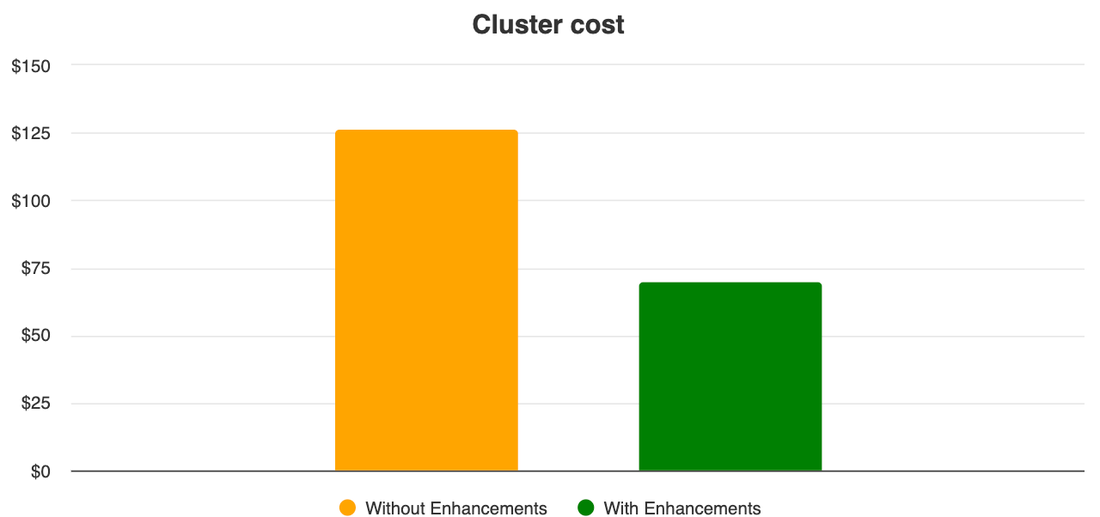
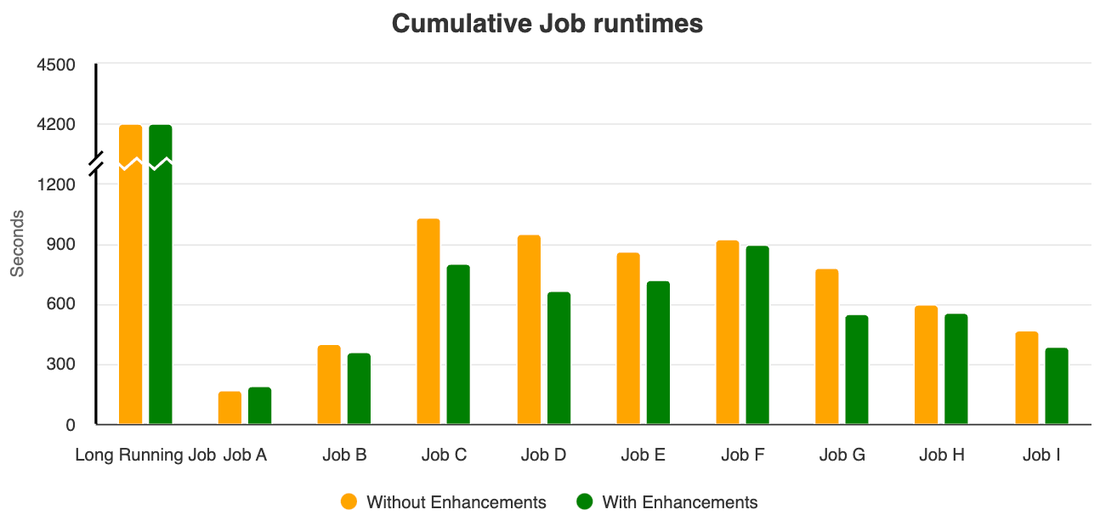
Most of the enhancements are available in image versions later than 2.0.66 and 2.1.18.
In the following sections, we will highlight the impact on cost or runtime for each of the enhancement categories.
Improving job performance with responsive upscaling
The Dataproc autoscaler continuously monitors YARN memory and CPU metrics to make scale-up and scale-down decisions. During the graceful decommissioning scale-down phase, autoscaler continues to monitor cluster metrics, and evaluates the autoscaling policy to decide if a scale-up is needed to meet job demands. For example, job completions can trigger a cluster scale-down. If there is then a surge in new job submissions, the autoscaler cancels the scale-down and triggers a scale-up operation. This improved upscaling prevents graceful decommissioning from blocking scale-up operations, making the cluster more responsive to workload needs.
The following Cloud Monitoring charts for the test clusters illustrate the effects of responsive upscaling. For the cluster without enhancements, the autoscaler does not respond to changes in YARN-pending memory. By contrast, for the cluster with enhancements, the autoscaler cancels the scale-down and scales up the cluster to meet demand as shown by the YARN-pending memory line. The vertical dotted line indicates when the scale-up operation is triggered.
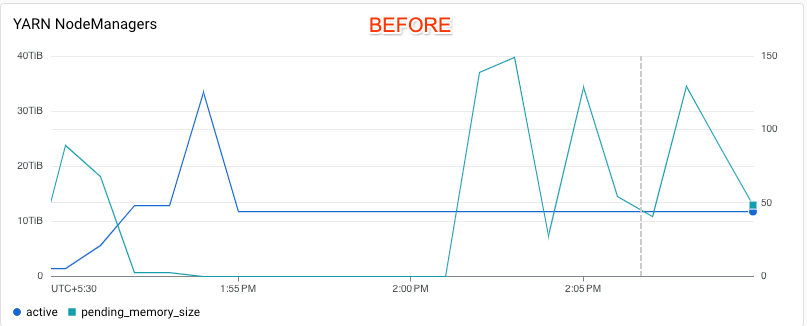
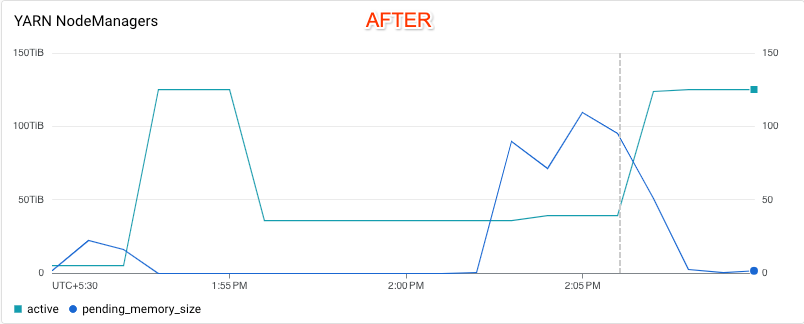
See When does autoscaling cancel a scale-down operation? for more information.
Increasing visibility into autoscaler operations
Enhancements to the autoscaler logs also indicate the evaluations that highlight the decision to cancel the scale-down operation in favor of a scale-up.
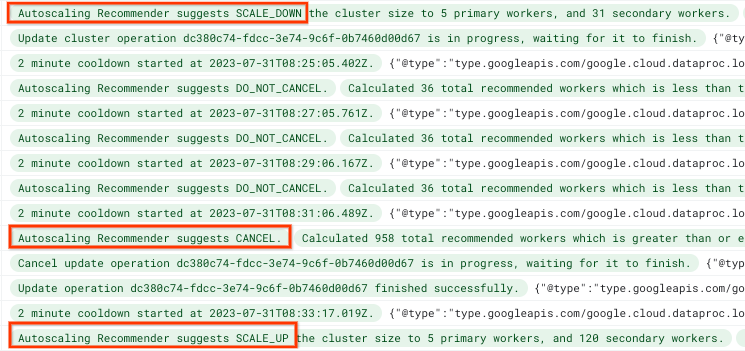
Reducing Dataproc cluster costs and scale-down times
Intelligent worker selection for faster scale-down
Dataproc now monitors multiple metrics to determine which workers to scale down. For each worker in the cluster, the selection criteria considers:
- Number of running YARN containers
- Number of running YARN application masters
- Total Spark shuffle data
Selecting idle workers based on the above metrics reduces the scale-down times.
Faster and more reliable scale-down for Spark with shuffle data migration and shuffle-aware decommissioning
Running executors and the presence of shuffle data on a worker slated to be decommissioned slows the scale-down operation. To speed up decommissioning, we introduced the following enhancements:
- Prevent active executors on decommissioning workers from accepting new tasks. This makes the executors complete sooner, allowing YARN to decommission the worker sooner.
- Immediately decommission workers that are not running any executors or hosting any shuffle data
- Migrate shuffle data off decommissioning workers to immediately decommission the worker
Going back to our two clusters, we see that in the ‘before’ scenario, the graceful decommissioning operation triggered lasts for an entire hour, the gracefulDecommissionTimeout in the autoscaling policy. In the ‘after’ scenario, it completes earlier even though jobs are still running on the cluster.
Before, the larger scale-down takes 61 minutes to complete :
After, the larger cluster scale-down is canceled in favor or scale up but a subsequent scale-down takes only 34 minutes to complete :
The YARN resource manager logs moving workers to DECOMMISSIONED state as soon as shuffle data migration completes:
This particular enhancement will be supported only in dataproc image versions 2.1.18+.
Prompt deletion of decommissioned workers
During scale-downs, Dataproc now monitors the decommissioning status of each worker and deletes a worker when it is decommissioned. Previously, Dataproc waited for all workers to be decommissioned before deleting the VMs. This enhancement results in cost savings when workers in a cluster with a long graceful decommissioning period are taking significantly longer than other workers to decommission.
Test setup
To demonstrate the benefits of the new autoscaling enhancements, we created two clusters with the same configuration:
n2d-standard-16master and worker machine types with 2 local SSDs attached, 5 primary workers, and between 0 and 120 autoscaling secondary workers.- Indentical default cluster configuration
- The same autoscaling policy:
Both clusters ran the same jobs:
- a long-running custom Spark job that consumes a fixed set of resources, in parallel with
- many short Spark jobs that simultaneously execute a few modified TPC-DS benchmark queries on a 1TB dataset with an idle time between runs to simulate bursts and idle behavior.
We created one cluster with a Dataproc image version of 2.1.3-debian11, without any of the autoscaling enhancements. The other cluster was created with a newer image version of 2.1.19-debian11 with all the enhancements.
The autoscaling enhancements are available by default on 2.0.66+ and 2.1.18+ image versions. You do not need to change cluster configurations or autoscaling policies to obtain the benefits of these enhancements. Spark shuffle data migration is only available in 2.1 image versions.
Conclusion
In this blog post, we highlighted the cost and job performance improvements resulting from Dataproc autoscaling enhancements, without the administrator needing to change the cluster configuration or autoscaling policy. To get started with Dataproc check out the Dataproc Quickstart and learn about Dataproc autoscaling.
* As of August 2023, at list prices, with the mentioned test setup


