Tips and tricks to get your Cloud Dataflow pipelines into production
Reza Rokni
Dataflow Product Manager
As data processing pipelines become foundational for enterprise applications, it’s mission-critical to make sure that your production data pipelines are up and running, and that any updates cause minimum disruption to your user base. When your data pipelines are stable, internal users and customers can trust them, which allows your business to operate with confidence. That extra confidence often leads to better user satisfaction and requests for more features and enhancements for the things your pipelines process.
We’ll describe here some of the best practices to take into consideration as you deploy, maintain and update your production Cloud Dataflow pipelines, which of course make use of the Apache Beam SDK.
We’ll start with some tips on building pipelines in Cloud Dataflow, then get into how to maintain and manage your pipelines.
Building easy-to-maintain data pipelines
The usual rules around good software development apply to your pipelines. Using composable transforms that encapsulate business logic creates pipelines that are easier to maintain, troubleshoot and develop with. Your SREs won't be happy with the development team if there is an issue at 2am and they are trying to unpick what's going on in that 50-stage pipeline built entirely with anonymous DoFns. Luckily, Apache Beam provides the fundamental building blocks to build easy-to-understand pipelines.
Using composable PTransforms to build pipelines
PTransforms are a great way to encapsulate your business logic and make your pipelines easier to maintain, monitor, and understand. (The PTransform style guide is a great resource.) Below are some extra hints and tips to follow:
Reuse transforms. Regardless of the size of your organization, you will often carry out many of the same transforms to a given dataset across many pipelines. Identify these transforms and create a library of them, treating them the same way you would a new API.
Ensure they have a clear owner (ideally the data engineering team closest to that dataset)
Ensure you have a clear way to understand and document how changes to those transforms will affect all pipelines that use them.
Ensure these core transforms have well-documented characteristics across various lifecycle events, such as update/cancel/drain. By understanding the characteristics in the individual transforms, it will be easier to understand how your pipelines will behave as a whole during these lifecycle events.
- Use display name. Always use the name field to assign a useful, at-a-glance name to the transform. This field value is reflected in the Cloud Dataflow monitoring UI and can be incredibly useful to anyone looking at the pipeline. It is often possible to identify performance issues without having to look at the code using only the monitoring UI and well-named transforms. The diagram below shows part of a pipeline with reasonable display names in the Cloud Dataflow UI—you can see it’s pretty easy to follow the pipeline flow, making troubleshooting easier.
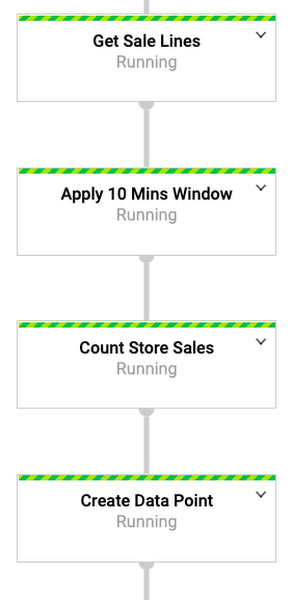
- Use the dead letter pattern. Ensure you have a consistent policy to deal with errors and issues across all of your transforms. Make heavy use of the dead letter pattern whenever possible. This pattern involves branching errors away from the main pipeline path into either a dead letter queue for manual intervention or a programmatic correction path.
- Remember versioning. Ensure that all transforms have versions and that all pipelines also have versions. If possible, keep this code in your source code repositories for a period that matches the retention policies for the data that flowed through these pipelines.
- Treat schema as code. Data schemas are heavily intertwined with any pipeline. Though it’s not always possible, try to keep your definitions of schemas as code in your source repository, distinct from your pipeline code. Ideally, the schema will be owned and maintained by the data owners, with your build systems triggering global searches when things break.
- Use idempotency. When possible, ensure that most, if not all, mutations external to the pipeline are idempotent. For example, an update of a data row in a database within a DoFn is idempotent. Cloud Dataflow provides for exactly-once processing within the pipeline, with transparent retries within workers. But if you are creating non-idempotent side effects outside of the pipeline, these calls can occur more than once. It’s important to clearly document transforms and pipeline that have this type of effect. It’s also important to understand how this may vary across different lifecycle choices like update, cancel and drain.
Testing your Cloud Dataflow pipelines
There’s plenty of detail on the Apache Beam site to help with the general testing of your transforms and pipelines.
Lifecycle testing
Your end-to-end data pipeline testing should include lifecycle testing, particularly analyzing and testing all the different update/drain/cancel options. That’s true even if you intend to only use update in your streaming pipelines. This lifecycle testing will help you understand the interactions the pipeline will have with all data sinks and and side effects you can’t avoid. For example, you can see how it affects your data sink when partial windows are computed and added during a drain operation.
You should also ensure you understand the interactions between the Cloud Dataflow lifecycle events and the lifecycle events of sources and sinks, like Cloud Pub/Sub. For example, you might see what interaction, if any, features like replayable or seekable would have with streaming unbounded sources.
This also helps to understand the interaction with your sinks and sources if they have to go through a failover or recovery situation. Of special importance here is the interaction of such events with watermarks. Sending data with historic timestamps into a streaming pipeline will often result in those elements being treated as late data. This may be semantically correct in the context of the pipeline, but not what you intend in a recovery situation.
Testing by cloning streaming production environments
One of the nice things about streaming data sources like Cloud Pub/Sub is that you can easily attach extra subscriptions to a topic. This comes at an extra cost, but for any major updates, you should consider cloning the production environment and running through the various lifecycle events. To clone the Cloud Pub/Sub stream, you can simply create a new subscription against the production topic.
You may also consider doing this activity on a regular cadence, such as after you have had a certain number of minor updates to your pipelines. The other option this brings is the ability to carry out A/B testing. This can be dependent on the pipeline and the update, but if the data you’re streaming can be split (for example, on entry to the topic) and the sinks can tolerate different versions of the transforms, then this gives you a great way to ensure everything goes smoothly in production.
Setting up monitoring and alerts
Apache Beam allows a user to define custom metrics, and with the Cloud Dataflow runner, these custom metrics can be integrated with Google Stackdriver. We recommend that in addition to the standard metrics, you build custom metrics into your pipeline that reflect your organization’s service-level objectives (SLOs). You can then apply alerts to these metrics at various thresholds to take remediation action before your SLOs are violated. For example, in a pipeline that processes application clickstreams, seeing lots of errors of a specific type could indicate a failed application deployment. Set these to show up as metrics and set up alerts in Stackdriver for them.
Following these good practices will help when you do have to debug a problematic pipeline. Check out the hints and tips outlined in the troubleshooting your pipeline Cloud Dataflow documentation for help with that process.
Pipeline deployment life cycles
Here’s what to consider when you’re establishing pipelines in Cloud Dataflow.
Initial deployment
When deploying a pipeline, you can give it a unique name. This name will be used by the monitoring tools when you go to the Cloud Dataflow page (or anywhere else names are visible, like in the gsutil commands). It is also has to be unique within the project. This is a great safety feature, as it prevents two copies of the same pipeline from accidentally being started. You can ensure this by always having the --name parameter set on all pipelines. Get into the habit of doing this with your test and dev pipelines as well.
Tips for improving for streaming pipeline lifecycle
There are some things you can do to build better data pipelines. Here are some tips.
Create backups of your pipelines
Some sources, like Cloud Pub/Sub and Apache Kafka, let you replay a stream from a specific point in processing time. Specific mechanisms vary: For example, Apache Kafka supports reads from a logical offset, while Cloud Pub/Sub uses explicitly taken snapshots or wall-clock times. Your application must take the specifics of the replay mechanism into account to ensure you replay all the data you need and do not introduce unexpected duplication. This feature (when available) lets you create a backup of the stream data for reuse if required. One example would be a rollout of a new pipeline that has a subtle bug not caught in unit testing, end-to-end testing, or at the A/B testing phase. The ability to replay the stream in those ideally rare situations allows the downstream data to be corrected without doing a painful one-off data correction exercise.
You can also use the Cloud Pub/Sub snapshot and seek features for this purpose.
Create multiple replica pipelines
This option is a pro tip from the Google SRE team. It is similar to the backup pipeline option. However, rather than creating the pipeline to be replayed in case of an issue, you spin up one or more pipelines to process the same data. If the primary pipeline update introduces an unexpected bug, then one of the replicas is used instead to read the production data.
Update a running pipeline
Update is a power feature of the Cloud Dataflow runner that allows you to update an existing pipeline in situ, with in-flight data processed within the new pipeline. This option is available in a lot of situations, though as you would expect, there are certain pipeline changes that will prevent the use of this feature. This is why it's important to understand the behavior of various transforms and sinks during different lifecycle events as part of your standard SRE procedures and protocols.
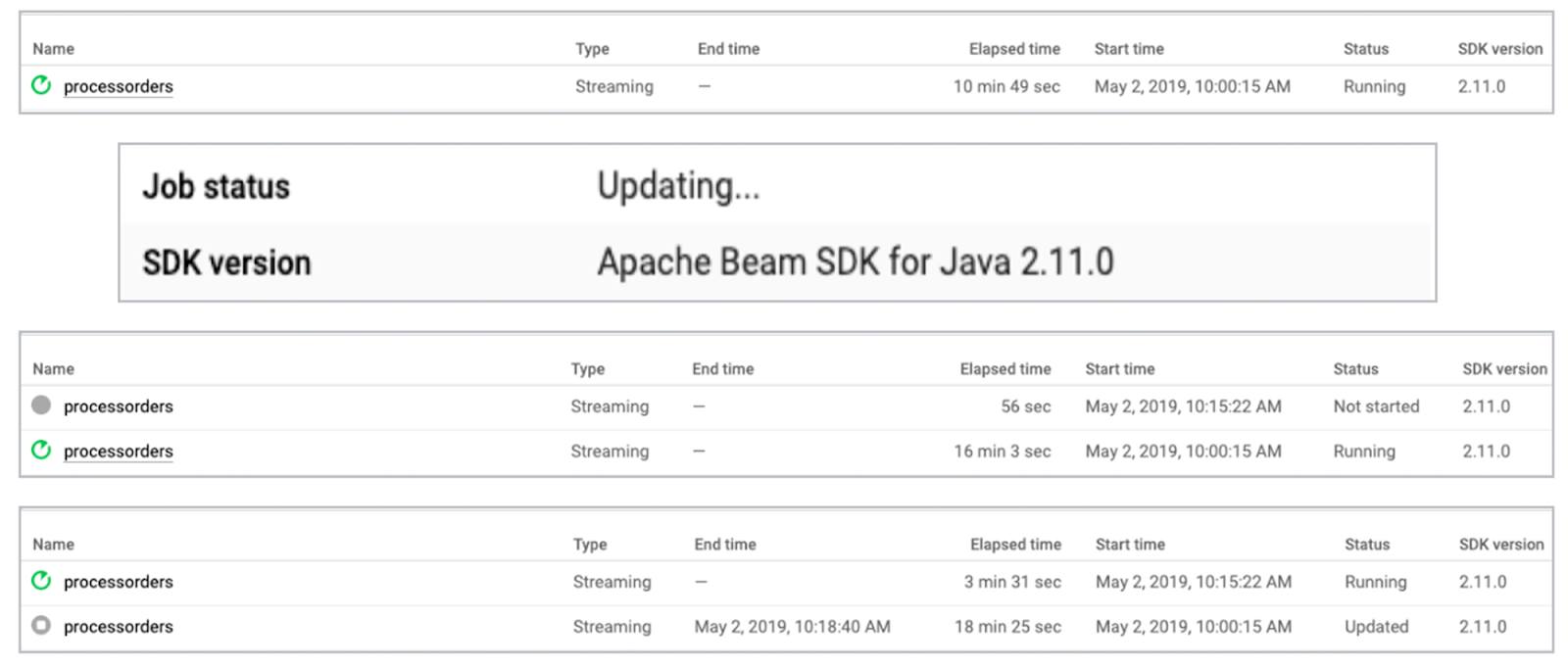
If it’s not possible to make the update, the compatibility check process will let you know during the update process. In that case, you should explore the Cloud Dataflow drain feature. The drain feature will stop pulling data from your sources and finish processing all data remaining in the pipeline. You may end up with incomplete window aggregations in your downstream sinks. This may not be an issue for your use case, but if it is you should have a protocol in place to ensure that when the new pipeline is started, the partial data is dealt with in a way that matches your business requirements.
Note that a drain operation is not immediate, as Cloud Dataflow needs to process all the source data that was read. In some cases, it might take several hours until the time windows are complete. However, the upside of drain is that all data that was read from sources and acknowledged will be processed by the pipeline.
If you want to terminate a pipeline immediately, you can use the cancel operation, which stops a pipeline almost immediately, but will result in all of the read and acknowledged data being dropped.
Learn more about updating a pipeline, and find out more about CI/CD pipelines with Cloud Dataflow.

