Tencent: Building analytics culture for better game development
Mathieu Ruiz
Lead Game Data Analyst, Funcom
Hao Liang
Manager, Data Platform, Tencent
Tencent is a leading internet and technology company headquartered in Shenzhen, China. Our mission is “value for users, tech for good.” We are also the company behind world-famous games like Level Infinite, PubG Mobile, Honor of Kings, GTFO, and Assassin’s Creed Jade. In February 2020, we acquired Funcom, a gaming company that recently celebrated its 30th anniversary, with a critically acclaimed portfolio that includes games like The Longest Journey, Anarchy Online, and Metal Hellsinger.
The acquisition of Funcom brought together the best of tech and the gaming industry, and with that, we decided to build an analytics culture at Funcom, supported by Google Cloud. We’ll share the challenges we faced as well as the solutions that were implemented in the process.
To demonstrate, we’ll use the online multiplayer survivor game, Conan Exiles, as an example. Developed by Funcom and released in 2017, this game constantly updates and releases new content, and was transitioned into a live service game model in 2022. As such, we needed data to support our business decisions.
An architecture for scalability and growth
Funcom’s architecture was developed to support the internal development team with live operations and to monitor the game servers’ health. The entire architecture was made of on-premises virtual machines and open-source frameworks, which limited our use cases and scalability. The legacy technology stack was not built with a data-driven approach in mind from a live service game model standpoint.
Based on interest from both developers and executives at Funcom, we decided to collaborate with Google Cloud to develop a new architecture. With only a few months to go before the release of the first season of Conan Exiles, the Google Cloud team provided us with a fully operational data warehouse that could be used to build dashboards and provide insights to key stakeholders, including executives, marketing, and live operations. The diagram below illustrates the architecture that we used:
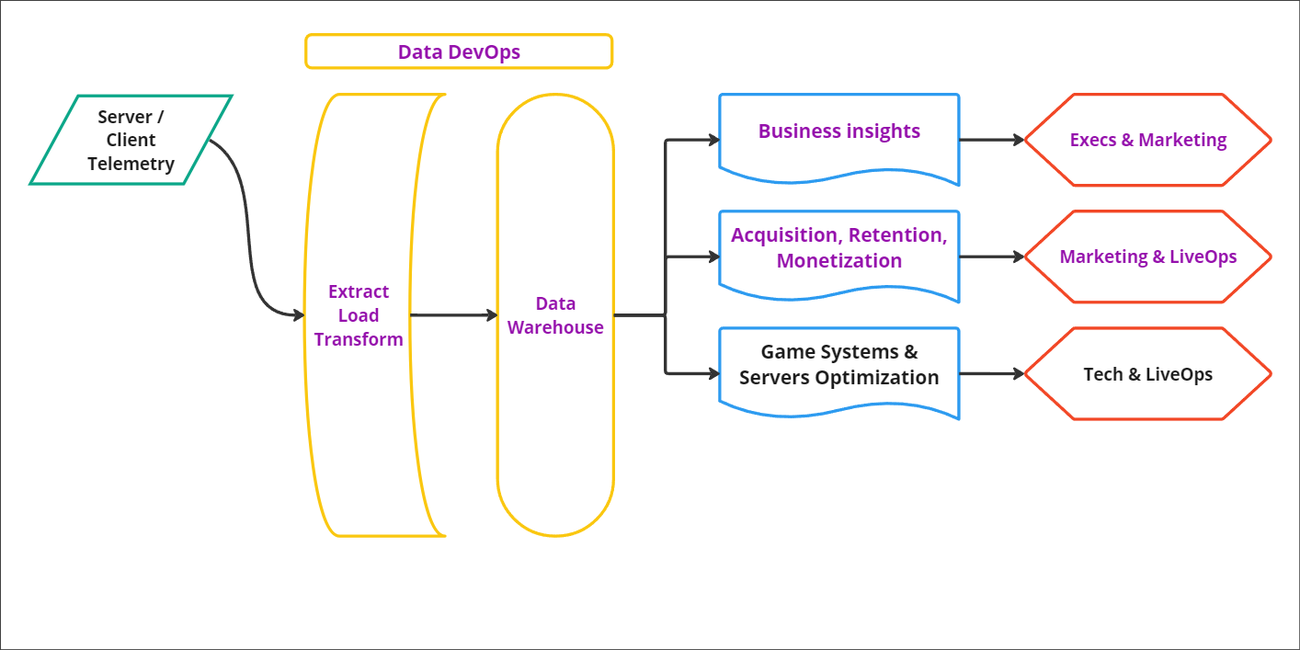
We built our new technology stack according to a few key criteria: ease of integration, diverse use case coverage, and optimizing the total cost of ownership (TCO).
Building this data platform was like putting together puzzle pieces. We replaced our legacy data infrastructure using key products like Cloud Storage and BigQuery, which acted as a data lake and query engine. As a result, we were able to build a robust data pipeline and a well-established data platform foundation in less than two months, enabling access to a host of new game data that was previously unseen, such as in-game player activity playtests. This includes marketing data, such as social listening and community responses, performance data about CPU, graphic or memory usage, and even crash monitoring data.
A new foundation to connect gaming and marketing datasets
With the new architecture set up, we decided to explore other ways of using data to optimize cost performance and get better control of the data stack to connect marketing and sales datasets. For example, game leads need to understand how data can support in-game development, while our marketing teams should have easy access to in-game data to support marketing efforts.
To help, we automated the entire pipeline with always up-to-date KPI reports to monitor our marketing performance within Google Cloud. Additionally, the data team can provide recommendations based on in-depth insight analytics by connecting the data across player behavior, community, and marketing.
Moving forward with a revenue-generating tech stack
With Google Cloud, we’ve been able to redesign the raw data pipeline and data lake architecture without impacting our gaming data pipeline, day-to-day decision-making systems, or requiring additional engineering overhead. As a result, we are able to process twice as much game data on a daily basis, compared to our previous architecture. In addition, we have also decreased our overall monthly costs by 70% using BigQuery and Cloud Composer.
Moving forward, we’re looking to further expand this architecture with near real-time pipelines built with Pub/Sub. We are also planning to improve data quality monitoring and alerting, and standardizing our data structure, so that we can deploy newly developed features directly to beta and accelerate our time to market.

