Smooth sailing: The resource hierarchy for adopting Google Cloud BigQuery across Twitter
Gary Steelman
Staff Software Engineer, Twitter
Saurabh Deochake
Senior Site Reliability Engineer, Twitter
Editor’s note: As part of an on-premises data warehousing migration to BigQuery, Twitter and Google Cloud teams created a Google Cloud resource hierarchy architecture that provides one-to-one mapping of the Hadoop Distributed File System (HDFS) to BigQuery. Designed for scalability and security, this architecture is set up to enable smoother adoption of BigQuery by mirroring the HDFS/Google Cloud Storage (GCS) data layout structure and access controls and enables scalable compute adoption. The authors would like to thank Vrushali Channapattan (former Twitter teammate) and Vrishali Shah from Google, for contributions to this blog.
Making data warehousing more widely available across Twitter
Before detailing how Twitter’s resource hierarchy helped enable the seamless adoption of BigQuery across Twitter, it is helpful to know why Twitter chose Google Cloud and BigQuery, and how the data warehouse was set up before the migration. In 2018, the infrastructure Twitter used for data warehousing included tools that required a programming background and had performance issues at scale. Data was siloed and access methods were inconsistent.
In 2019, Twitter embarked on a mission to democratize data processing and analysis for their employees to empower them to analyze and visualize data while increasing the development velocity for the machine learning experimentation. Twitter decided to migrate to a cloud-first, scalable data warehouse to improve data insights and enhance productivity. It needed to be both simple and powerful so that Twitter employees across the enterprise, no matter their technical skills, could access and analyze data for business intelligence and insights. The Twitter Data Platform team selected BigQuery based on the areas of ease-of-use, performance, data governance, and system operability. In 2019, the migration of the on-premises data warehousing infrastructure to BigQuery began and BigQuery became generally available at Twitter in April 2021.
Twitter employees run millions of queries a month on almost an exabyte of data stored across tens of thousands of BigQuery tables. Moreover, Twitter’s internal data processing jobs process over an exabyte of uncompressed data.
To enable that kind of scale after the migration, while ensuring a smooth transition, the Twitter Data Platform and Google Cloud teams had several requirements. The most critical was one-to-one mapping of the on-premises resource hierarchy to BigQuery. Another requirement was that the BigQuery setup mirror Twitter’s identity and access management (IAM) structure to protect the customer data that Twitter employees analyze. With these requirements in mind, the teams went to work.
Structuring the storage project hierarchy for one-to-one mapping
In Twitter’s BigQuery structure, there are two separate types of projects: storage and compute. Storage projects are designed to store only data. On the other hand, any data processing job operating on the data stored in the storage projects, must run inside compute projects. This section describes the resource hierarchy for storage projects.
The following diagram shows the BigQuery resource hierarchy for the one-to-one mapping of on-premises HDFS datasets to BigQuery tables or views. Because this hierarchy is in place, HDFS and GCS data can be moved smoothly to BigQuery and accessed in a familiar way by Twitter employees.
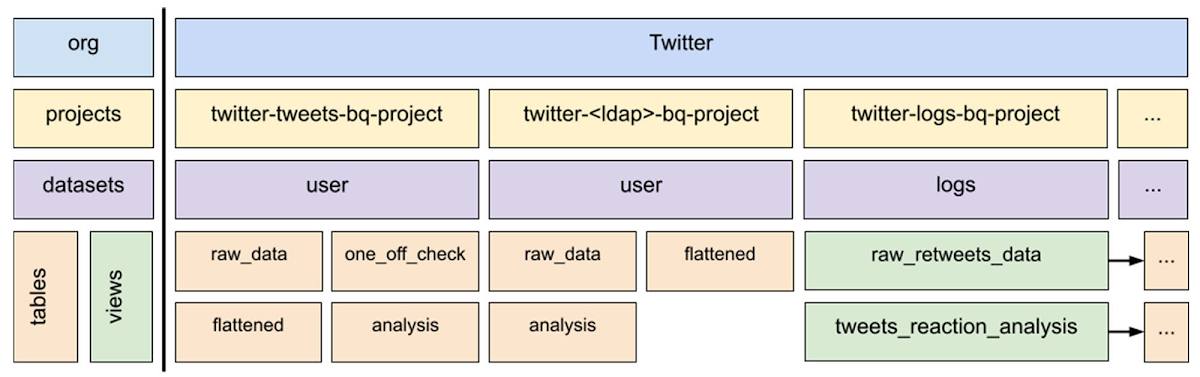
With this architecture, users can easily identify where their datasets are, access those datasets, and have the right permissions as if they were still on-premises. Let’s take a closer look at these components in the hierarchy and then see how they work together.
Drilling down on the storage project hierarchy to understand the mapping
The Twitter nomenclature for projects in BigQuery enables one-to-one dataset mapping by clearly identifying each type of dataset. The two types are user and log:
- User type includes datasets that users create, and it is further divided into human and non-human users or service accounts.
- Log datasets are all the different types of event logs that client applications, traffic front ends, and other Twitter applications generate.
In the diagram, the first user project, twitter-tweets-bq-project, is for non-human user datasets, and “tweets” is the identifier. The second project, twitter-<ldap>-bq-project, identifies a Twitter employee who generates data. The project, twitter-logs-bq-project, contains views that point to log datasets stored in the log storage projects (not pictured). This consolidated list of views provides easy discovery for event logs.
How does this mapping work for an actual dataset? Here’s an example. An on-premises dataset hypothetically called tweets.raw_data maps to the storage project twitter-tweets-bq-project where “tweets” is the non-human user or an LDAP service account. The dataset is always user, and it is automatically created. Then, the HDFS dataset on-premises at Twitter is loaded into a table with the same name in that BigQuery dataset, resulting in twitter-tweets-bq-project.user.raw_data being available in BigQuery. This is the case for both human and non-human owned datasets. For logs, related log datasets are collocated into the same storage project based on their name. Then a view is automatically created in twitter-logs-bq-project to ease discovery and access to the logs datasets.
This mapping flow is not a one-and-done proposition; the life cycles of the projects and corresponding datasets, including creation, modifications and updates, and deletions require ongoing management. To that end, Twitter uses a set of services including Terraform, an open-source system for automatic provisioning.
For compute projects, the automatic provisioning is different, as is the process for creating those projects.
Into the shadows: Creating compute projects and managing identity
Twitter takes a self-service approach to BigQuery compute projects. An internal system enables users to create projects directly from a UI. They can run their jobs, access and analyze data, create ML models, with minimal effort, which delivers insights faster and increases productivity. From the internal UI, users may choose a project name and some other project features, and click submit. That triggers actions in the backend.
First, the system automatically creates a corresponding on-premises LDAP group for that project and a Google group, linking both with mutual updates. That group automatically becomes the owning group for that project, and anyone who wants to access the project can request it from the group. A Google Cloud admin service system binds everything and provisions the project. It also makes API calls to Google Cloud to configure cloud resources according to Twitter’s security controls and standards.
The identity and access management (IAM) for BigQuery compute projects follows the AAA principles of authentication, authorization, and auditing. If Twitter employees want to access data in BigQuery, they can use their user accounts to log in. A system automatically publishes the keys for all the service accounts regularly and can be used to authenticate the corresponding users.
Using Google Cloud Databases in unison with BigQuery
Many BigQuery customers also use Google Cloud Databases like Cloud Bigtable to manage their datasets, and Twitter is no different. Twitter opted to use Cloud Bigtable due to its ability to process billions of events in real time. The Bigtable implementation has resulted in cost savings, higher aggregation accuracy and stable, low latency for real-time pipelines. Plus, Twitter no longer needs to maintain different real-time event aggregations in multiple data centers following their Bigtable implementation. In the future, Twitter plans to make Bigtable datasets resilient to region failures. You can learn more about Twitter’s use of Bigtable here.
Reading the map: Lessons learned along the migration path
Twitter’s migration to BigQuery was an ambitious and rewarding undertaking that enriched the knowledge and capabilities of both teams. Working successfully with Google Cloud has enabled Twitter to enhance the productivity of its engineering teams. Building on this relationship and Google Cloud's technologies will allow Twitter to learn more from their data, move faster and serve more relevant content to the people who use their service every day. As Twitter continues to scale, Google Cloud and Twitter will partner on more industry-leading technology innovation in the data and machine learning space.
For its part, the Google Cloud team learned to apply a different lens to its ideas of project parameters, database size, and support. For example, the Google Cloud team significantly increased the GCP projects limit in a VPC-Service Control perimeter. It also improved the UI usability and performance to enable the accessing of more than 1000 datasets in one project. These changes to BigQuery and collaboration with other Google Cloud project and engineering teams to enable cross-project service account support will continue to benefit Twitter in undertaking new projects.
This successful partnership with Google Cloud allowed Twitter to democratize big data analytics by enabling BigQuery to thousands of internal monthly active users (MAUs). Twitter has also improved development velocity by unlocking faster big data processing as well as machine learning experimentation on Google Cloud.


