Streaming data into BigQuery using Storage Write API

Shanmugam (Shan) Kulandaivel
Product Manager, Streaming Analytics, Google Cloud
Sergei Lilichenko
Solutions Architect, Google Cloud
BigQuery is a serverless, highly scalable, and cost-effective data warehouse that customers love. Similarly, Dataflow is a serverless, horizontally and vertically scaling platform for large scale data processing. Many users use both these products in conjunction to get timely analytics from the immense volume of data a modern enterprise generates. To make sure that users have a great experience using BigQuery and Dataflow together, we are constantly working on making new integrations that make it easier to use, scale and optimize. For example, recently we launched support for auto sharding for BigQueryIO connector, which improves the throughput of streaming pipelines on average by 3x.
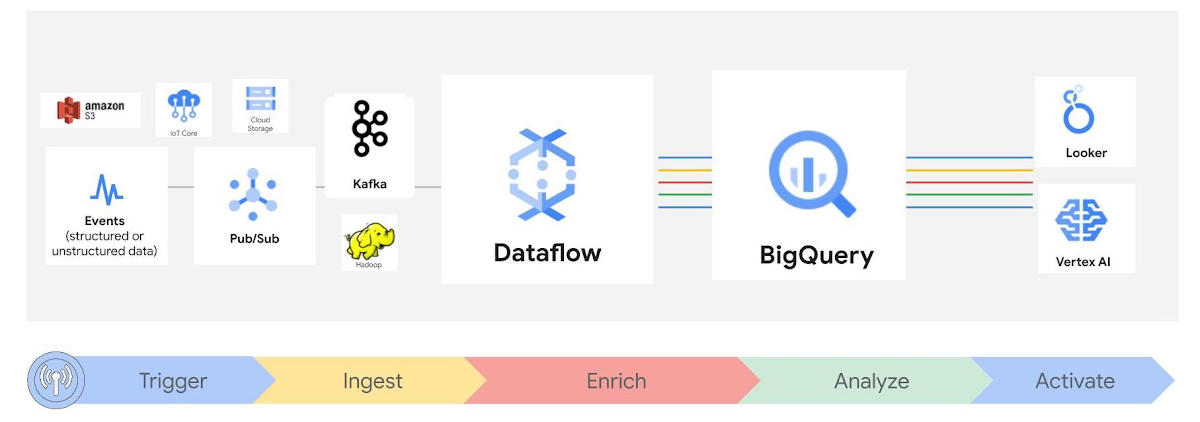
Today, we are happy to launch another such integration that brings the best of BigQuery to Dataflow users. The BigQuery team recently launched the new BigQuery Storage Write API into general availability. The BigQuery Storage Write API is a unified data-ingestion API for BigQuery. For Dataflow users, this means you can combine streaming ingestion and batch loading into a single high-performance API. You can use the Storage Write API to stream records into BigQuery that become available for querying as they are written, or to batch process a large number of records and commit them in a single atomic operation. The new API offers higher throughput than its predecessor, table.insertAll() API, and significantly lowers streaming ingestion cost, including up to 2TB free usage per month.
The new API is available via a Java client library, a Python client library or you can use it from any language which supports gRPC.
We are now making support for the Storage Write API in Dataflow available by providing two additional methods to the BigQueryIO connector. You have a choice of using a method with exactly-once semantics of inserting data into BigQuery or a lower latency and potentially cheaper method with at-least-once semantics.
Using BigQuery Storage Write API with exactly-once semantics
The following section shows how with a few small changes you can update your existing Java pipelines and take advantage of the Storage Write API’s strong transactional semantics.
1. Update your pipeline to the Beam SDK version that supports the Write API (we recommend using version 2.36.0 or newer) and is supported by Dataflow.
2. To use the new API, set the new method, STORAGE_WRITE_API, when creating the BigQueryIO’s Write transform. A typical code will look like this:
3. If your pipeline needs to create the table (in case it doesn’t exist and you specified the create disposition as CREATE_IF_NEEDED) you will need to provide the table schema. It will be also used by the API to validate data and convert it to the efficient binary protocol buffer message before calling the backend. The new API will be using this schema to do data validation before it’s submitted to the backend.
4. Finally, for the streaming pipelines two additional parameters need to be set - number of streams and triggering frequency.
Number of streams defines the parallelism of the BigQueryIO’s Write transform and roughly corresponds to the number of Storage Write API’s streams which will be used by the pipeline. You can set it explicitly on the transform via the withNumStorageWriteApiStreams method or provide the “numStorageWriteApiStreams” option to the pipeline as defined in BigQueryOptions class.
Triggering frequency will determine how soon the data will be visible for querying in BigQuery. You can explicitly set it via the withTriggeringFrequency method or specify the number of seconds by setting the “storageWriteApiTriggeringFrequencySec” option.
The combination of these two parameters affect the size of the batches of rows the BigqueryIO creates before calling the Storage Write API. Setting the frequency too high can result in smaller batches which can affect the performance.
We recommend that you test your pipeline on a representative volume before running it in production (good idea for all pipelines!) and find optimal values for the two parameters we mentioned above. As a starting point here’s some guidance: a single stream should be able to handle throughput of at least 1Mb per second. Creating exclusive streams used by this method is an expensive operation for the BigQuery service; use only as many streams as needed for your use case. Triggering frequency in single-digit seconds is a good choice for most pipelines.
In the future we will enable auto sharding support to determine and adjust these parameters at the run time.
Using BigQuery Storage Write API with at-least-once semantics
For the use cases where potential duplicate records in the target table are acceptable you can use the STORAGE_WRITE_API method’s cousin, the STORAGE_API_AT_LEAST_ONCE method. Because this method doesn’t persist the records to be written to BigQuery into its shuffle storage (needed to provide the exactly-once semantics of the STORAGE_WRITE_API method) it will be cheaper and will result in lower latency for most pipelines. It is also simpler to use - it doesn’t need the two additional parameters we mentioned earlier.
Before running large scale pipelines which will require a substantial number of streams (thousands), review the Storage Write API quotas. These quotas are related to the number of open gRPC connections to the BigQuery service. In BigQueryIO implementation the number of connections varies based on the method. For the STORAGE_WRITE_API method it is roughly the number of streams; for the STORAGE_API_AT_LEAST_ONCE method it can be up to the maximum number of workers in the pipeline. Notice that the maximum number of connections for ingestion into tables located in multi-regional BigQuery locations (“us” and “eu”) is higher than for regional locations.
Next steps
BigQuery Storage Write API and Dataflow support for it are now available for all users with Beam SDK 2.36.0 (or newer).



