Simple backup and replay of streaming events using Cloud Pub/Sub, Cloud Storage, and Cloud Dataflow
Sergei Sokolenko
Cloud Dataflow Product Manager
Google Cloud is announcing an easy way to backup and replay your streaming pipeline events directly from the Cloud Console via a new collection of simple import/export templates. If you are a developer interested in data stream processing, you’ll likely find this feature very handy.
For example, let’s assume you’ve built a streaming pipeline on Cloud Pub/Sub and Cloud Dataflow and deployed it into production. A few days later, after being notified by Cloud Error Reporting and inspecting logs, you realize that some of the events travelling through your Pub/Sub topics are malformed. You want to investigate this further, but don’t want to interrupt your main production pipeline. “Wouldn’t it be great if there were a simple way to siphon events into a Cloud Storage file that you can then inspect for errors?” you ask. Or perhaps there is nothing wrong with your events, but you just want to save a collection of them as a simple backup, and then replay these events in the future to debug a problem or run a reproducible test.
For several months now, Cloud Dataflow has offered a collection of simple import/export templates, inter-connecting data sources such as Pub/Sub, BigQuery, Datastore, Bigtable, files in text and Avro format, and many others. We are now bringing these import/export capabilities right to where the rest of your data lives: to Pub/Sub topics, GCS folders and files, etc.
Here’s how it works:
Saving streaming events into text files
Find the Pub/Sub topic that you want to backup to a text file, via the Pub/Sub console.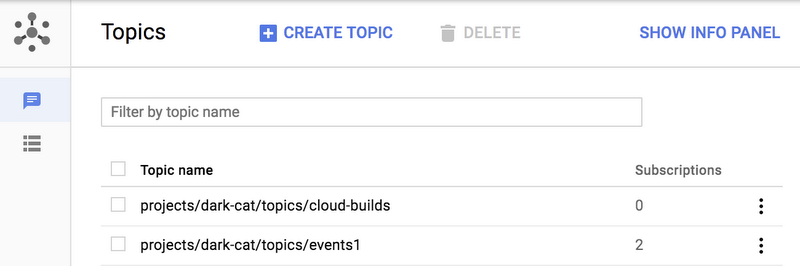
After confirming that you want to run a Dataflow export job, you will see a simple page where the name of the Pub/Sub topic is already pre-selected and where you can enter the destination Cloud Storage folder. We selected gs://PROJECT_ID/teleport/output/ as our output location and gs://PROJECT_ID/teleport/tmp as our temporary location, and also set a prefix for output file names to “events”.
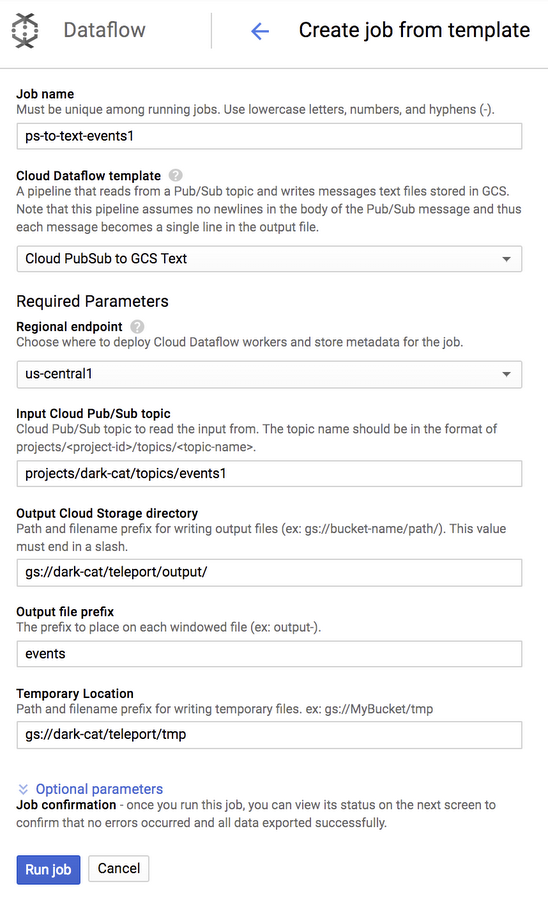
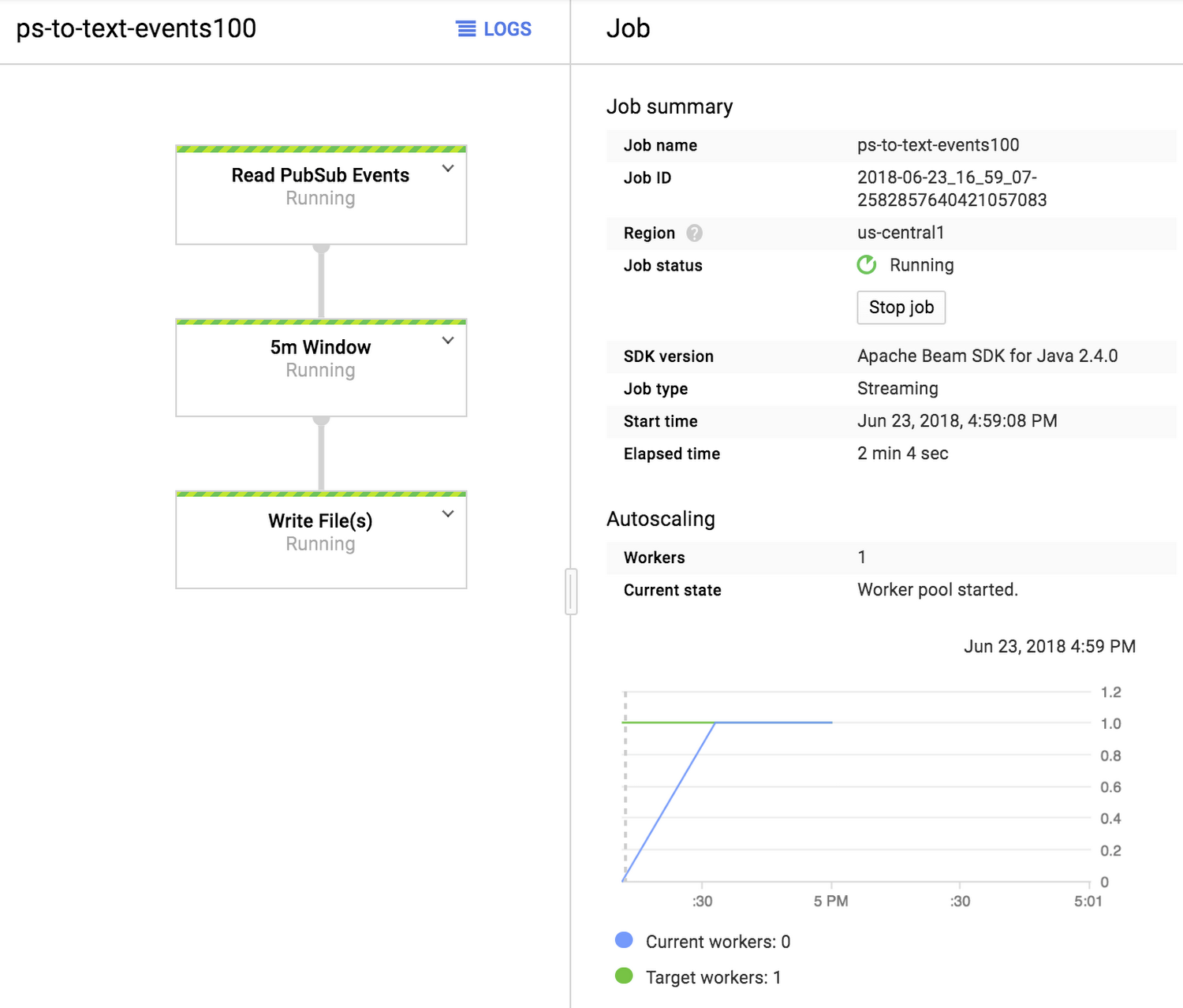
Clicking “Run Job” will start a continuous export job (a streaming pipeline) that will capture all events that pass through the Pub/Sub topic and save them into text files at 5 minute intervals.
Let’s look at the output folder. After navigating to the Cloud Storage browser, we see several output files that were created by our pipeline.
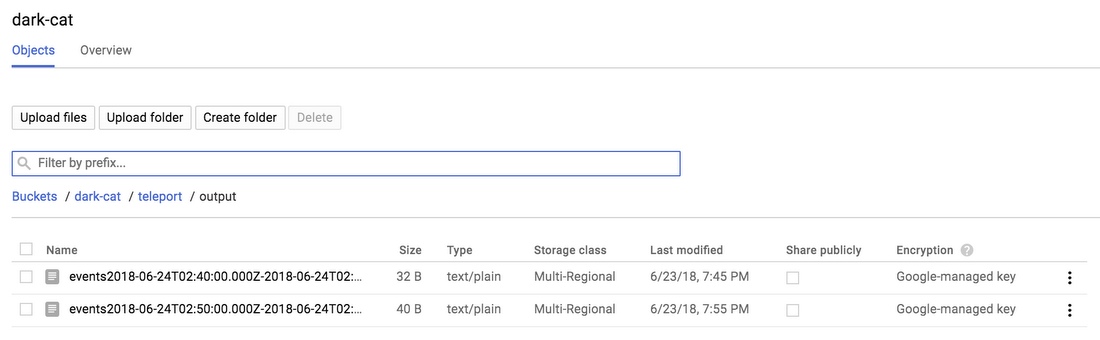
We can now inspect their contents, learn more about the events that pass through our Pub/Sub topic, and, we can also replay these events.
Replaying events
To replay saved events, click on the options menu in the Cloud Storage browser near the file that you want to replay.
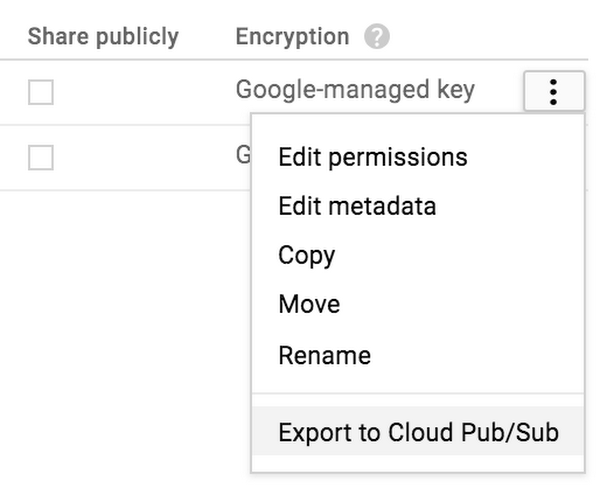
You can also replay entire folders, too. The “Export to Pub/Sub” menu is available for both folder and file objects in the Cloud Storage browser.
When you select the “Export to Cloud Pub/Sub” menu, a very similar Dataflow page will be presented to you where you can confirm the selected file and enter the destination Pub/Sub topic.
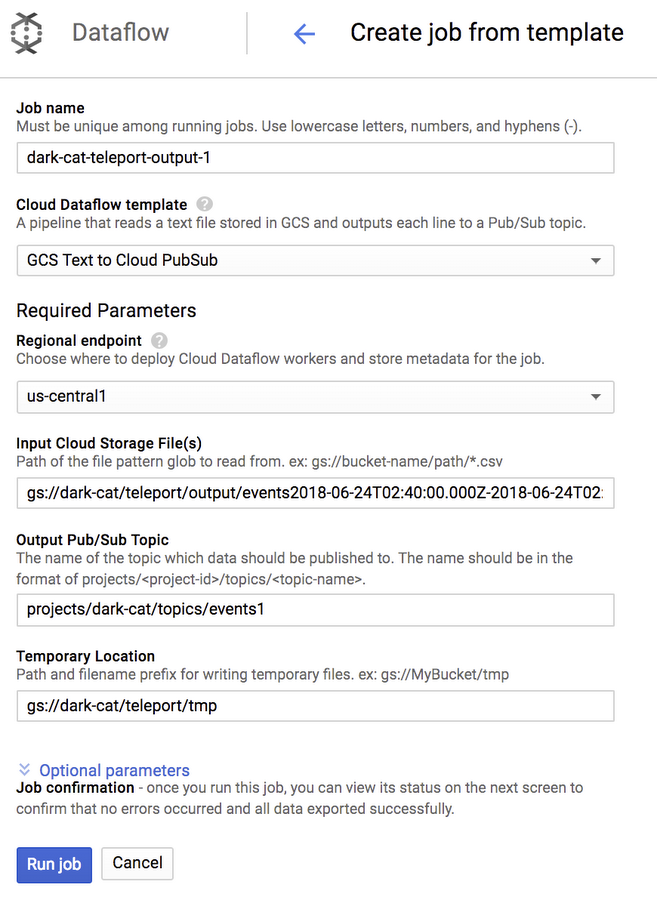
When you click on “Run job”, a very simple batch import job will be created that will parse the file you specified and send a Pub/Sub message for each record it found in that file. If you selected a folder when exporting, all files in that folder will be processed that way.
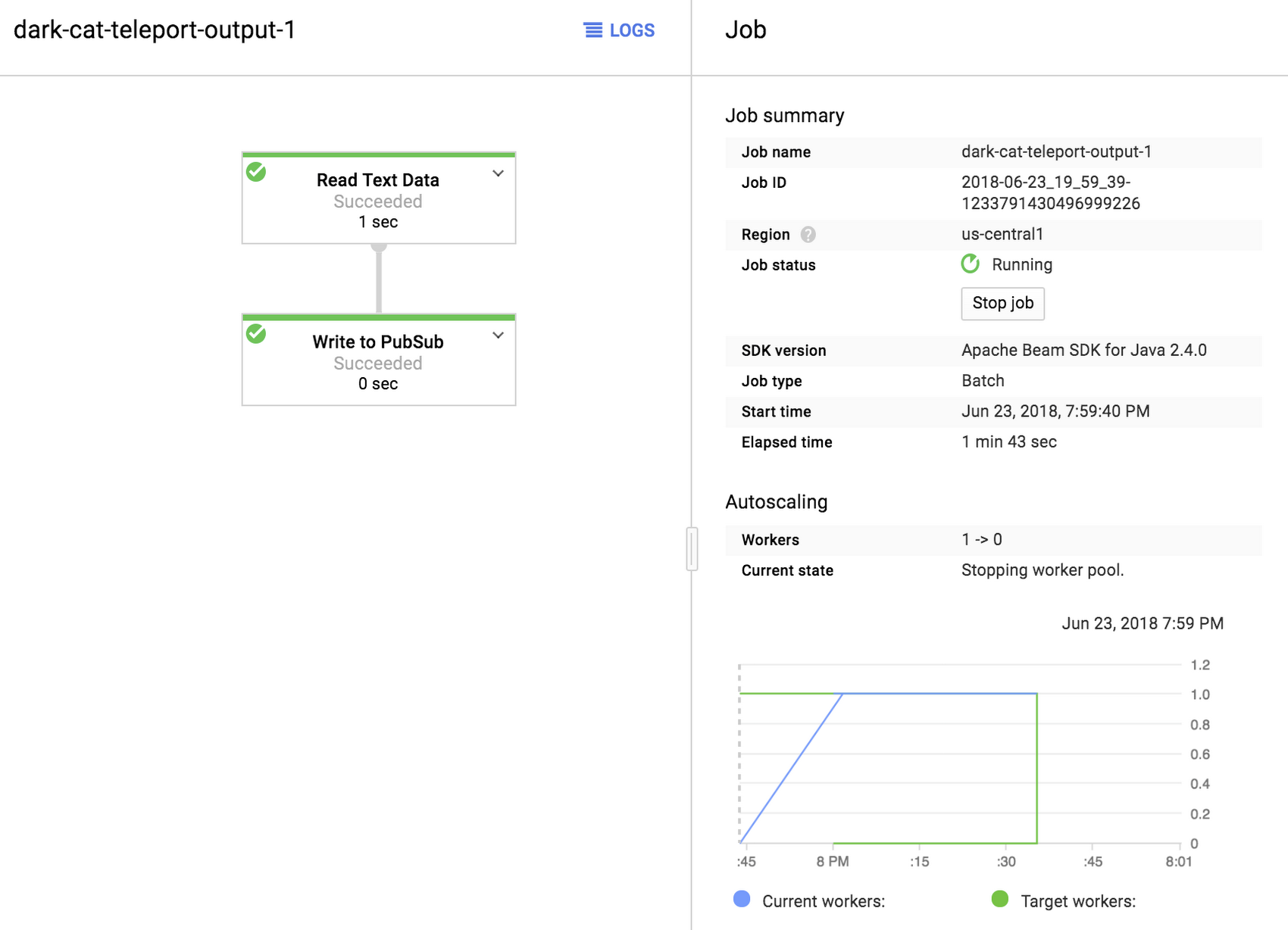
This is how you backup and replay streaming events in Cloud Pub/Sub using a very simple import/export functionality in Cloud Dataflow.
Next steps
We hope you’ve found this quick explainer useful to help you test Cloud Pub/Sub scenarios, and simulate results in Dataflow based on these backed up and replayed datasets. For some additional, related topics, feel free to check out the following tutorials:

