Running format transformations with Cloud Dataflow and Apache Beam
Frank Natividad
Developer Platform Engineer
Karthi Thyagarajan
Senior Staff Solutions Architect
Conversions between tabular data file formats (AVRO ⇔ CSV and AVRO ⇔ Parquet, for example) is a common necessity for data scientists and engineers. These conversions are so frequent, in fact, that users often forget how cumbersome it can become when you have to transform terabytes or petabytes of data. Today, Apache Hive (often on Tez) is a common tool for transforming large amounts of data from one format to another. While Hive has gotten much faster and easier to use, spinning up a Hadoop cluster to perform these transformations certainly still involves a lot of moving parts: cluster creation, cluster sizing, and choice of Hive engine, just to name a few.
Well, now there’s another, serverless way to transform files from one format to another—using Apache Beam on Cloud Dataflow and Cloud Storage.
We wrote an example to illustrate how to convert between CSV and AVRO formats. Doing a transformation using this approach is as simple as specifying the appropriate input parameters to the Dataflow job:
AVRO to CSV:
CSV to AVRO:
There’s no need to provision a cluster and no need to guess at the number of machines to incorporate into the cluster: Cloud Dataflow’s autoscaling feature adjusts the instance count appropriately. Of course, you can still control the number of instances if you want to override autoscaling. Since Dataflow scales horizontally, this sample can perform format conversions on petabytes of input files. Once the job has been kicked off, you can keep track of progress on the Dataflow console:
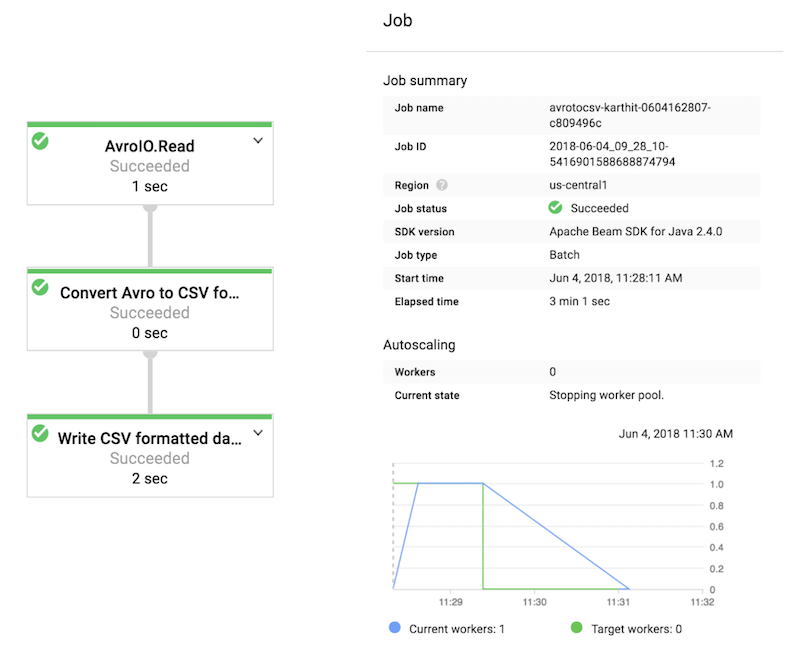
Output from the job is stored in the Cloud Storage location specified. For a large dataset, the job may generate a large number of files and this sample lets you configure the size of output files. This particular sample converts between AVRO and CSV formats, and it lets you specify the schema in the form of a JSON file, as depicted in the command snippet above.
The AVRO schema is used for ordering of fields without a header in the CSV formatted files. Data types are also determined by the AVRO schema and used to convert CSV String data to their respective data type. The example currently doesn't support byte data stored in CSV and will log the error to Stackdriver Logging. You can read more about logging on Dataflow documentation for pipeline logging.
While this sample focuses on converting between AVRO and CSV, the general approach described here can be used for other format conversions as well. ParquetIO support is in the works, and we encourage you to contribute additional transforms to Apache Beam, for instance, ORC.
To learn more about Cloud Dataflow and Apache Beam, check out the documentation and templates below:


