A review of input streaming connectors for Apache Beam and Apache Spark

Julien Phalip
Solutions Architect, Google Cloud
Leonid Kuligin
Strategic Cloud Engineer, Google Cloud
In this post, you’ll learn about the current state of support for input streaming connectors in Apache Beam. For more context, you’ll also learn about the corresponding state of support in Apache Spark, another popular open-source data processing framework.
Google Cloud Platform (GCP) offers several fully-managed solutions to run your Beam and Spark workloads in a simple and cost-efficient way. In particular, Cloud Dataflow simplifies the deployment of Beam pipelines by offering a serverless solution that scales horizontally with virtually limitless capacity. Also, Cloud Dataproc offers easily resizable clusters with customizable machine types, and frequently updated open-source versions of Spark, Hadoop, Pig, and Hive.
With batch processing, you might load data from any source, including a database system. Even if there are no specific SDKs available for those database systems, you can often resort to using a JDBC driver. With streaming, implementing a proper data pipeline is arguably more challenging as generally fewer source types are available. For that reason, this article particularly focuses on the streaming use case.
Connectors for Java
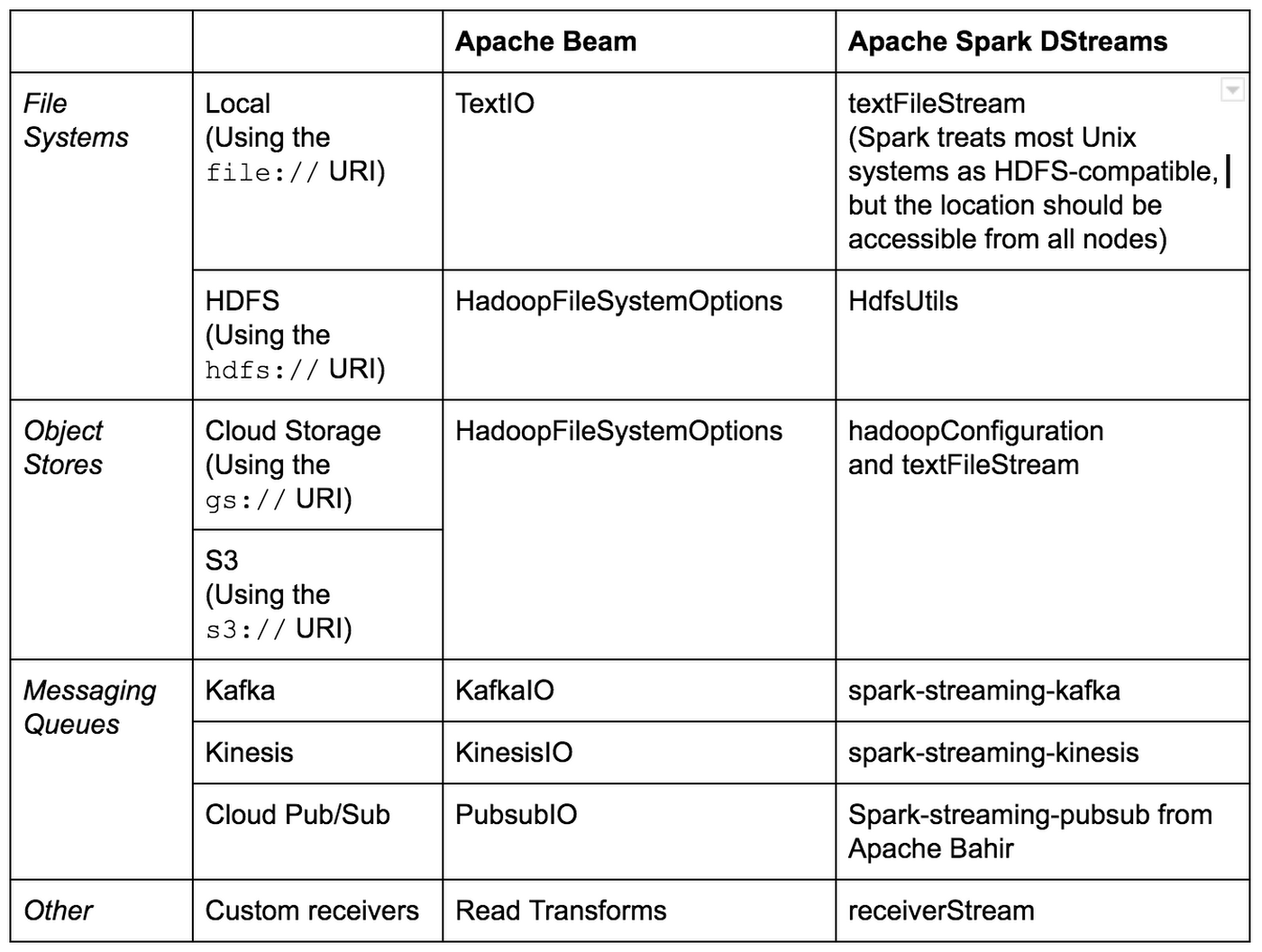
Beam has an official Java SDK and has several execution engines, called runners. In most cases it is fairly easy to transfer existing Beam pipelines written in Java or Scala to a Spark environment by using the Spark Runner.
Spark is written in Scala and has a Java API. Spark’s source code compiles to Java bytecode and the binaries are run by a Java Virtual Machine. Scala code is interoperable with Java and therefore has native compatibility with Java libraries (and vice versa).
Spark offers two approaches to streaming: Discretized Streaming (or DStreams) and Structured Streaming. DStreams are a basic abstraction that represents a continuous series of Resilient Distributed Datasets (or RDDs). Structured Streaming was introduced more recently (the alpha release came with Spark 2.1.0) and is based on a model where live data is continuously appended to a table structure.
Spark Structured Streaming only supports file sources (local filesystems and HDFS-compatible systems like Cloud Storage) and Kafka as streaming inputs. Spark maintains built-in connectors for DStreams aimed at third-party services, such as Kafka or Flume, while other connectors are available through linking external dependencies, as shown in the table below.
Below are the main streaming input connectors for available for Beam and Spark DStreams in Java:
Connectors for Python
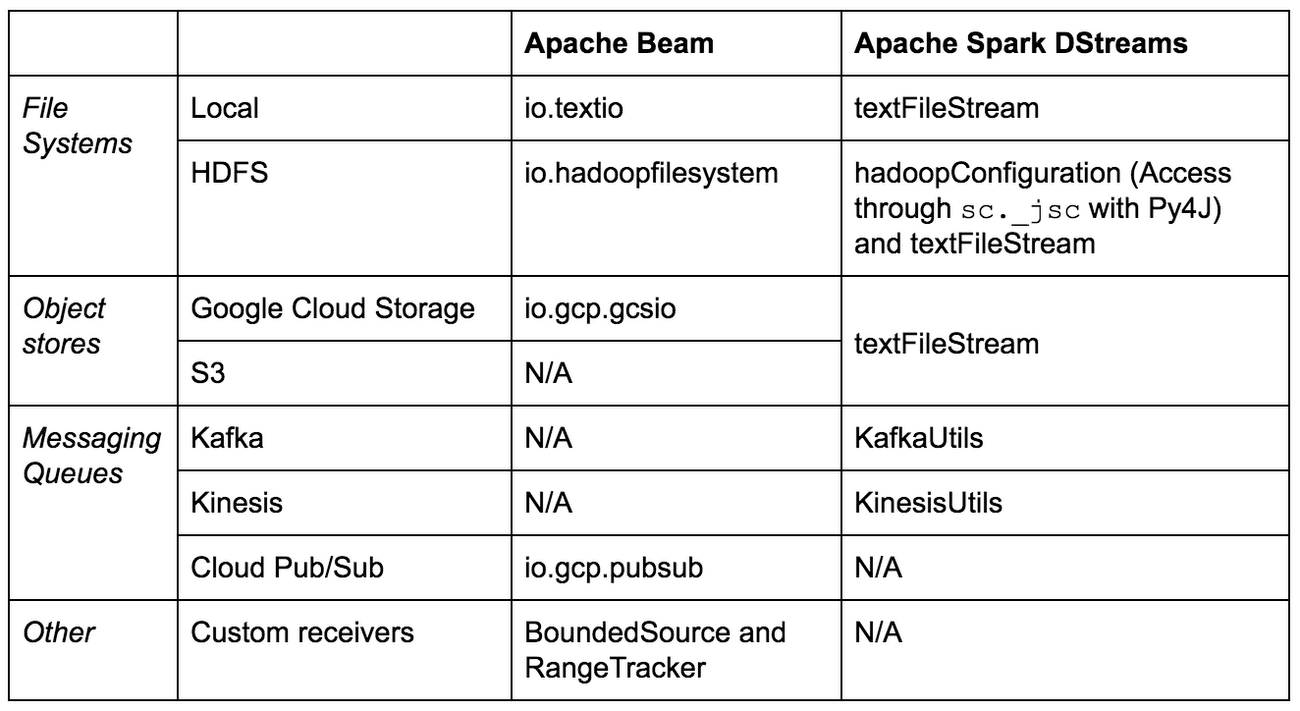
Beam has an official Python SDK that currently supports a subset of the streaming features available in the Java SDK. Active development is underway to bridge the gap between the featuresets in the two SDKs. Currently for Python, the Direct Runner and Dataflow Runner are supported, and several streaming options were introduced in beta in version 2.5.0.
Spark also has a Python SDK called PySpark. As mentioned earlier, Scala code compiles to a bytecode that is executed by the JVM. PySpark uses Py4J, a library that enables Python programs to interact with the JVM and therefore access Java libraries, interact with Java objects, and register callbacks from Java. This allows PySpark to access native Spark objects like RDDs. Spark Structured Streaming only supports for file sources (local filesystems and HDFS-compatible systems including AWS S3 and Google Cloud Storage) and Kafka as streaming inputs.
Below are the main streaming input connectors for available for Beam and Spark DStreams in Python:
Connectors for other languages
Scala
Since Scala code is interoperable with Java and therefore has native compatibility with Java libraries (and vice versa), you can use the same Java connectors described above in your Scala programs. Apache Beam also has a Scala SDK open-sourced by Spotify.
Go
A Go SDK for Apache Beam is under active development. It is currently experimental and is not recommended for production.
R
Apache Beam does not have an official R SDK. Spark Structured Streaming is supported by an R SDK, but only for file sources as a streaming input.
Next steps
We hope this article inspired you to try new and interesting ways of connecting streaming sources to your Beam pipelines!
Check out the following links for further information:
- See a full list of all built-in and in-progress I/O Transforms for Apache Beam.
- Learn about some Apache Beam mobile gaming pipeline examples.
- See this guide on using Apache Spark DStreams with Cloud Dataproc and Cloud Pub/Sub
- See this guide on using BigDL for deep learning with Apache Spark and Google Cloud Dataproc
Learn about some utilities that simplify using Apache Spark on Google Cloud.


