Introducing partitioning and clustering recommendations for optimizing BigQuery usage
Vinay Yerramilli
Product Manager, BigQuery
Sharon Fang
Product Manager
Do you have a lot of BigQuery tables? Do you find it hard to keep track of which ones are partitioned and clustered, and which ones could be? If so, we have good news. We're launching a partitioning and clustering recommender that will do the work for you! The recommender analyzes your organization's workloads and tables and identifies potential cost optimization opportunities.
"The BigQuery partitioning and clustering recommendations are awesome! They have helped our customers identify areas where they can reduce costs, improve performance, and optimize our BigQuery usage." Sky, one of Europe leading media and communications companies
How does the recommender work?
Partitioning divides a table into segments, while clustering sorts the table based on user-defined columns. Both methods can improve the performance of certain types of queries, such as queries that use filter clauses and queries that aggregate data.
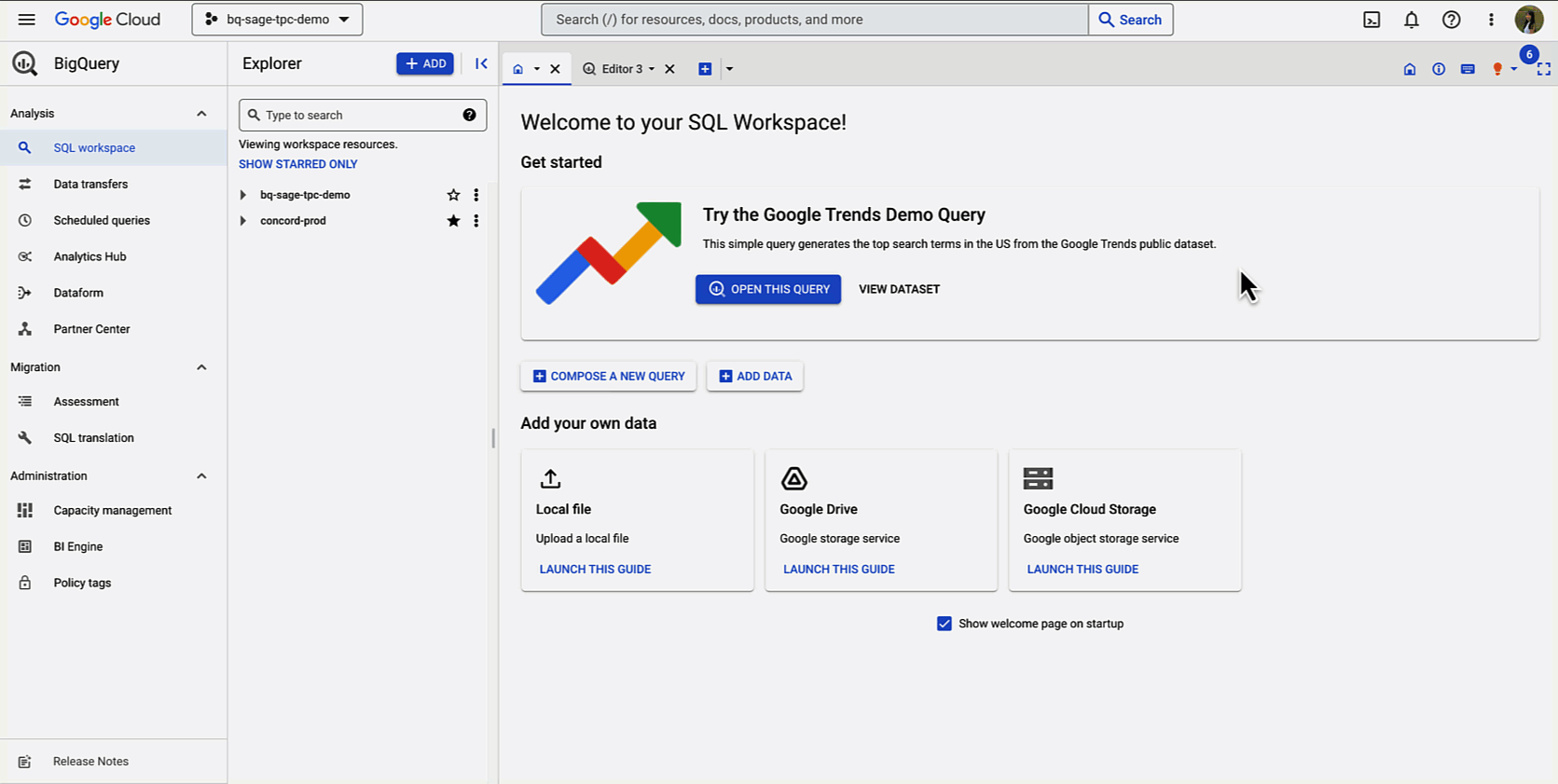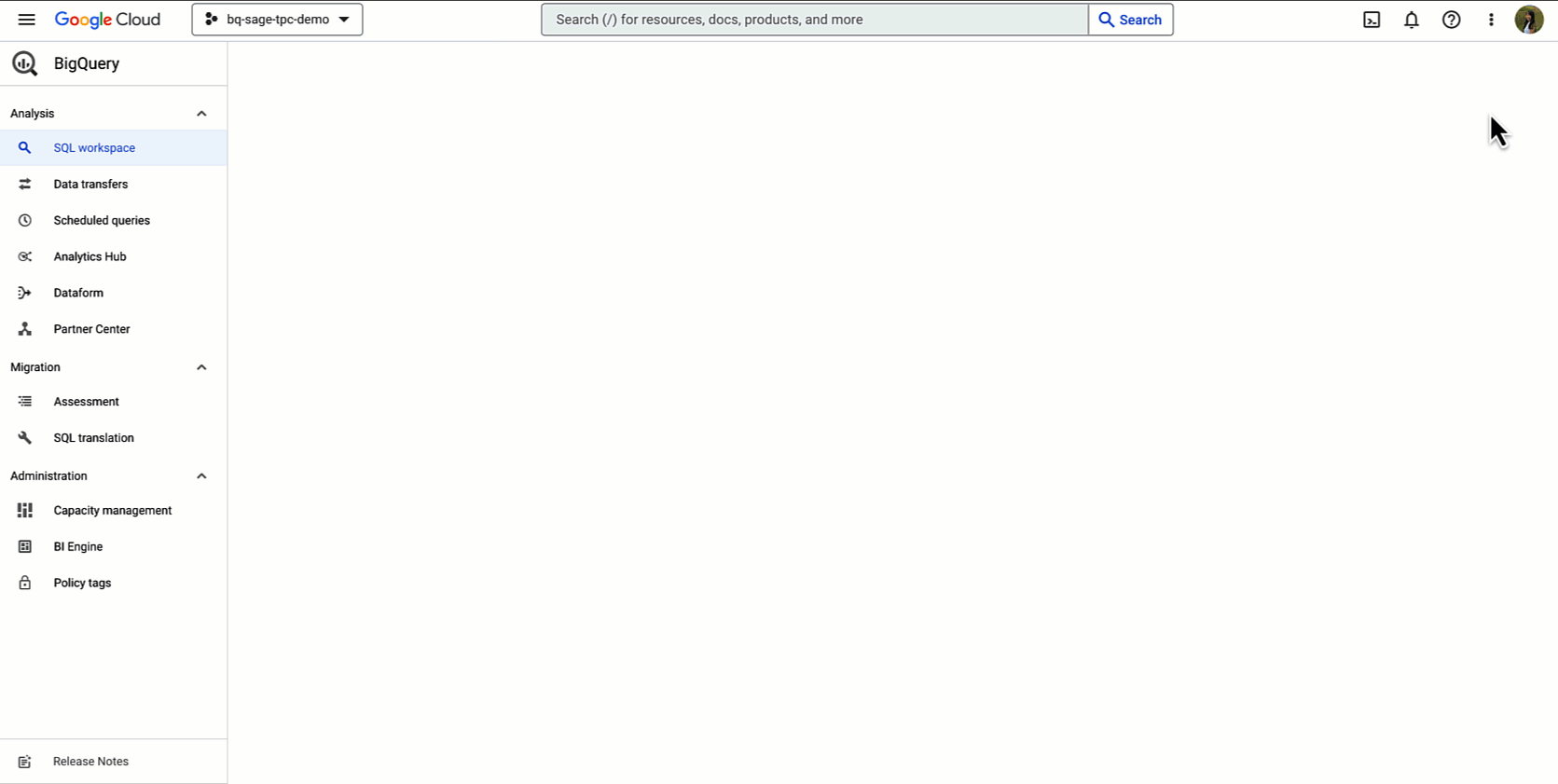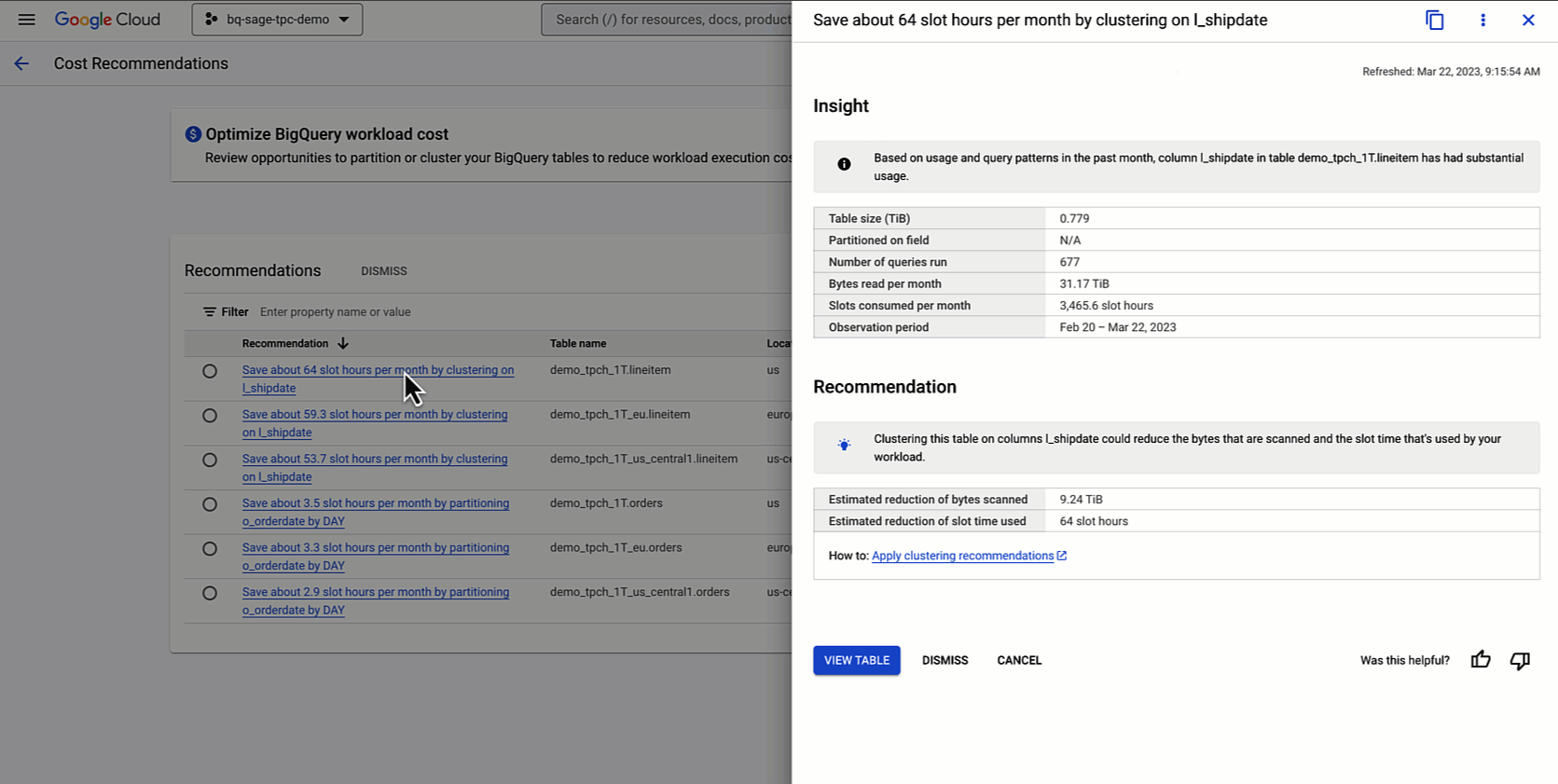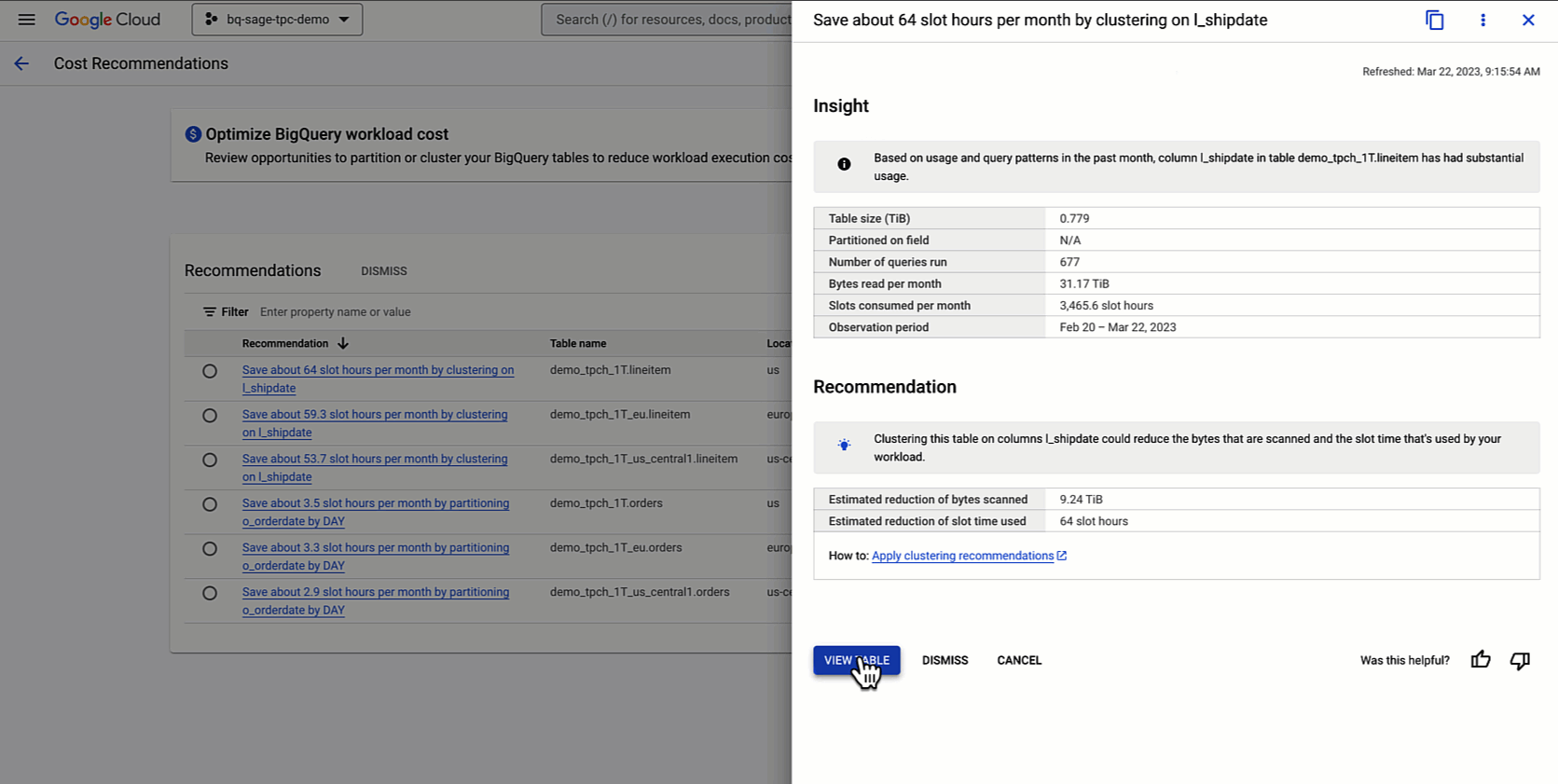
BigQuery’s partitioning and clustering recommender analyzes each project’s workload execution over the past 30 days to look for suboptimal scans of the table data. The recommender then uses machine learning to estimate the potential savings and generate final recommendations. The process has four key steps: Candidate Generation, Read Pattern Analyzer, Write Pattern Analyzer, and Generate Recommendations.
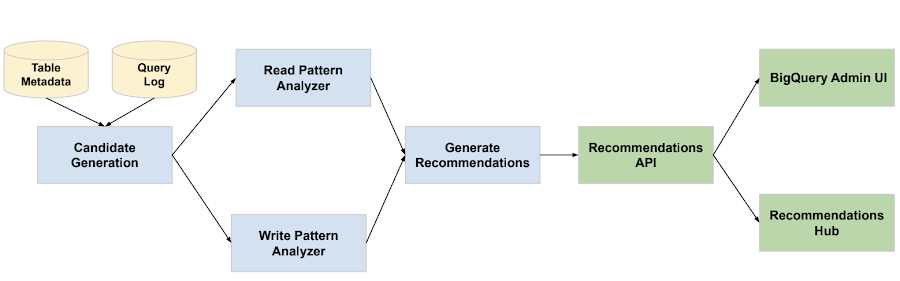
Candidate Generation is the first step in the process, where tables and columns are selected based on specific criteria. For Partitioning, tables larger than 100 Gb are chosen, and for Clustering tables larger than 10 Gb are chosen. The reason for filtering out the smaller tables is because the optimization benefit is smaller and less predictable. Then we identify columns that meet BigQuery's partitioning and clustering requirements.
In the Read Pattern Analyzer step, the recommender analyzes the logs of queries that filter on the selected columns to determine their potential for cost savings through partitioning or clustering. Several metrics, such as filter selectivity, potential file pruning, and runtime, are considered, and machine learning is used to estimate the potential slot time saved if partitioning or clustering is applied.
The Write Pattern Analyzer step is then used to estimate the cost that partitioning or clustering may introduce during write time. Write patterns and table schema are analyzed to determine the net savings from partitioning or clustering for each column.
Finally, in Generate Recommendations, the output from both the Read Pattern Analyzer and Write Pattern Analyzer is used to determine the net savings from partitioning or clustering for each column. If the net savings are positive and meaningful, the recommendations are uploaded to the Recommender API with proper IAM permissions.
Discovering BigQuery partitioning and clustering recommendations
You can access these recommendations via a few different channels:
- Via the lightbulb or idea icon in the top right of BigQuery’s UI page
- On our console via the Recommendation Hub
- Via our Recommender API
You can also export the recommendations to BigQuery using BigQuery Export.
To learn more about the recommender, please see the public documentation.
We hope you use BigQuery partitioning and clustering recommendations to optimize your BigQuery tables, and can’t wait to hear your feedback and thoughts about this feature. Please feel free to reach us at active-assist-feedback@google.com.

