Get up to 100x query performance improvement with BigQuery history-based optimizations
Peter Freiling
Software Engineer, Google
Andrei Romanenko
Software Engineer, Google
When looking for insights, users leave no stone unturned, peppering the data warehouse with a variety of queries to find the answers to their questions. Some of those queries consume a lot of computational resources — and many of those queries closely resemble one another. To further speed up query execution, we developed BigQuery history-based optimizations, a new query optimization technique that learns from previously completed executions of similar queries to identify and apply additional improvements to the query execution. They can make queries run faster and/or consume fewer resources, improving various performance metrics including elapsed time, slot time, and processed bytes.
With the benefit of concrete, historical data from previous executions of similar queries, history-based optimizations can confidently target high-reward optimizations that are well suited for a specific workload.
During the public preview of history-based optimizations, we saw instances where query performance on customer workloads improved up to 100x, and today, history-based optimizations are generally available.
In this blog post, we detail the underlying technology behind history-based optimizations, the benefits they provide, and how to get started.
It just works
We designed history-based optimizations to deliver improvements without user intervention. The infrastructure is self-tuning and self-correcting, with no special configurations or actions needed from you.
When you run a query, BigQuery analyzes the statistical data after each query execution to identify workload-specific optimizations that can apply to the next execution of a similar query. This happens in the background with no impact to user workloads. After the next execution validates that the optimization is beneficial, more optimizations can be identified and applied, resulting in an iterative and incremental improvement to query performance.

History-based optimizations are resilient to the rare event when an optimization does not significantly improve (or even worsens) query performance, and will self-correct to avoid using that specific optimization for any future execution of that query. There’s no need for you to intervene!
Query matching
BigQuery uses an intelligent query-matching algorithm to maximize the number of queries that can share identified optimizations, while minimizing the risk in applying them to significantly different queries.
Trivial query changes, like modifying comment strings or whitespace, reuse all previously identified optimizations. Such changes do not have any impact on query execution.
Nontrivial changes, like modifying the values of constants or query parameters, may reuse some previously identified optimizations and ignore others, depending on whether BigQuery is confident that it will provide benefit to the modified query.
If there are significant changes to the query, such as querying a different source table or columns, BigQuery ignores all previously identified optimizations. This is because the statistical data used to identify the optimization is likely no longer applicable to the modified query.
History-based optimizations are currently scoped to a specific Google Cloud project.
Optimization types
At this time, history-based optimizations support four optimization types that complement existing optimization methods.
Join pushdown
Join pushdown aims to reduce data processed by executing highly selective joins first.
When a query finishes execution, BigQuery may identify highly selective joins, where the output (number of rows) of the join is significantly smaller than its input. If such a join is executed after other operations that are not as selective, such as other joins or aggregations, BigQuery may choose to run the selective join earlier. This effectively “pushes down” the “join” in the execution order as shown in Figure 1. This can reduce the amount of data that needs to be processed by the rest of the query, which reduces resources consumed and improves overall query-execution time.
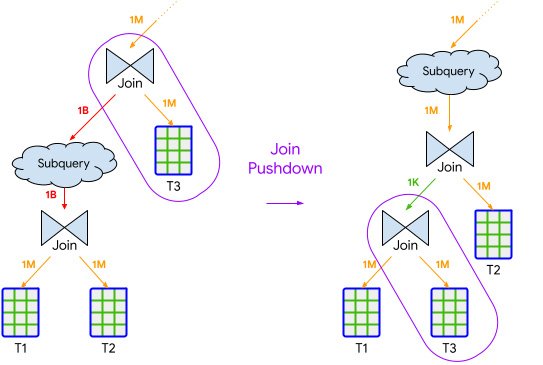
Figure 1. Example of a join pushdown history-based optimization, “pushing” the selective join with table T3 “down” in execution order to reduce intermediate row counts.
While BigQuery already performs optimizations for some queries without the benefit of statistics from prior executions, history-based join pushdown leverages additional insights into data distribution to further improve performance and apply it to more queries.
Semijoin reduction
Semijoin reduction aims to reduce the amount of data that BigQuery scans by inserting selective semijoin operations throughout the query.
BigQuery may identify a highly selective join (similar to join pushdown) in a query with several parallel paths of execution that are eventually joined together. In some cases, BigQuery can insert new “semijoin” operations based on the selective join that “reduces” the amount of data scanned and processed by those parallel execution paths, as shown in Figure 2. Though this is logically modeled as a semijoin, it is usually performed through other internal optimizations such as partition pruning.
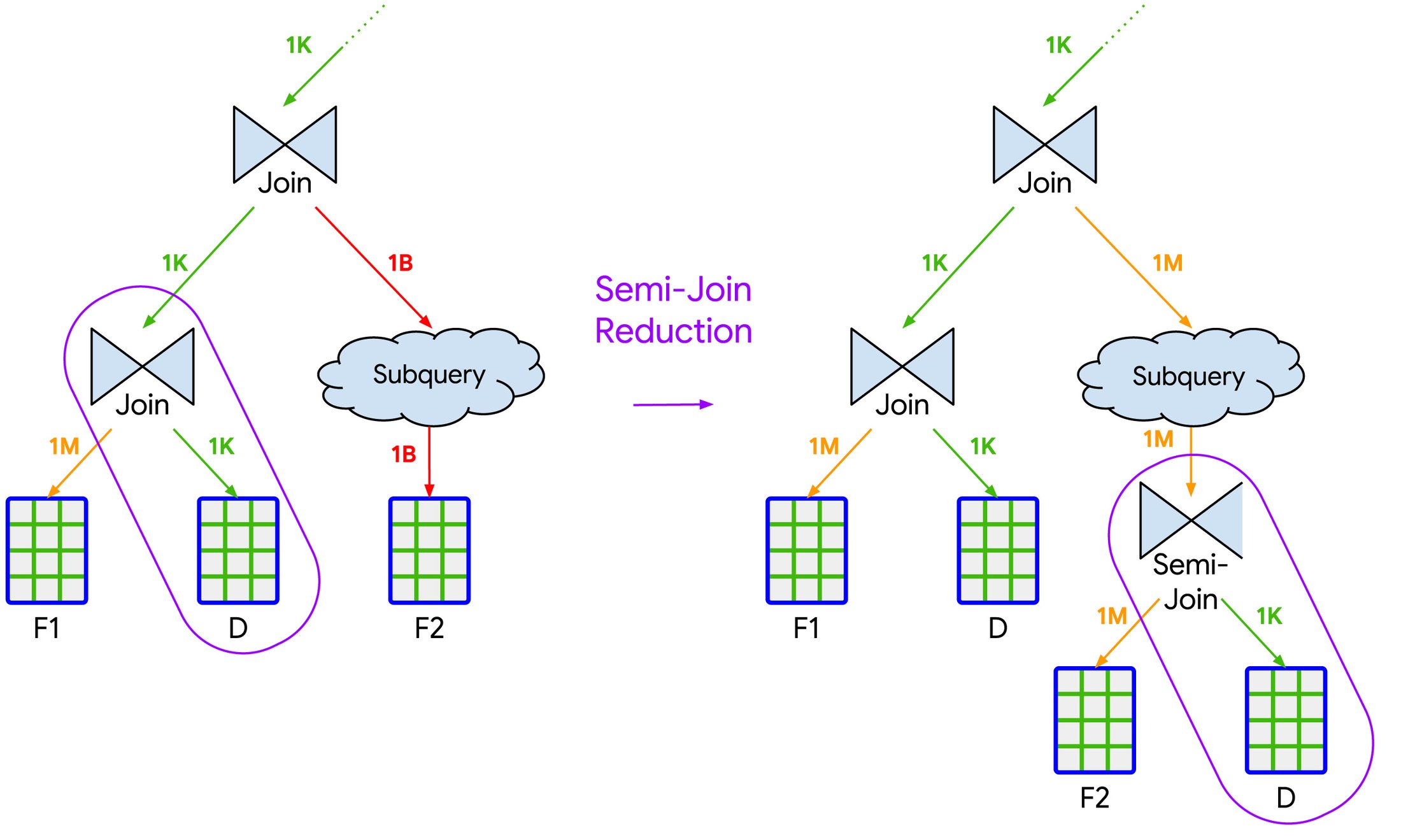
Figure 2. Example of a semijoin reduction history-based optimization, using a selective join to insert a new semijoin into the query to reduce the number of rows processed from the second fact table, F2.
Join commutation
Join commutation aims to reduce resources consumed by swapping the left and right sides of a join operation.
When executing a join operation, the two sides of the join can be processed differently, for example, BigQuery may choose one side of the join to build a hash table, which is then probed as it scans the other side of the join. Since the two sides of a join can be “commutative” (the order does not change the outcome), in some cases, BigQuery may identify that it may be more efficient to swap these two sides, reducing the resources consumed in executing that join operation.
Parallelism adjustment
Parallelism adjustment aims to improve query latency by parallelizing the work more efficiently.
BigQuery uses a distributed parallel architecture to execute queries in stages. For each such stage, BigQuery chooses an initial level of parallelism to execute the work, but may dynamically adjust the parallelism level during execution in response to observed data patterns.
With history-based optimizations, BigQuery can now “adjust” the initial level of “parallelism”, given the known workload distribution of the previous executions of the query. This allows BigQuery to parallelize work more efficiently, reduce overhead, and achieve lower latency, especially for queries with large, compute-heavy stages.
Try it for yourself
History-based optimizations are now generally available. Over the coming months, they will be enabled for all customers by default, but you can enable them earlier for your project or organization. You can review what history-based optimizations were applied (if any) in INFORMATION_SCHEMA, as well as understand the impact of history-based optimizations on your jobs.
You can try out history-based optimizations with the following sample query:
-
Select or create a project that has not yet executed this demo query (or else you may only observe the already-optimized query).
-
Enable history-based optimizations for the selected project.
-
Disable retrieval of cached results.
-
Execute the following sample query, which uses a BigQuery public dataset, and take note of the elapsed time:
5. Execute the same demo query again, and compare the elapsed time to the first execution.
6. Optionally, you may check whether history-based optimizations were applied for each of the executions following instructions here, using the job IDs for each execution.
Looking ahead
History-based optimizations constitute a framework for ongoing investment in BigQuery’s optimization capabilities, not simply a static set of four new optimizations. This technology enables a new class of optimizations that would otherwise be infeasible to implement without having real statistical data (not just estimates) from prior executions of similar queries. Its self-learning and self-correcting capabilities serve as a safety mechanism for unforeseeable issues. As we continue to expand existing and future history-based optimizations, our goal is to make BigQuery smarter, autonomously adapting to changing workloads . You won’t have to do anything; queries will just run faster and at lower cost. Try it today following the instructions above and let us know what you think from the BigQuery console.


