Dataflow Pipelines, deploy and manage data pipelines at scale
Shan Kulandaivel
Senior Product Manager, Dataflow
Manav Garg
Software Engineer, Dataflow
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialWe see data engineers use Dataflow for a wide variety of their data processing needs, ranging from ingesting data into their data warehouses and data lakes to processing data for machine learning use cases to implementing sophisticated streaming analytics applications. While the use cases and what customers do varies, there is one common need that all of these users have: the need to create, monitor and manage dozens, if not hundreds of, Dataflow jobs. As a result, users have asked us for a scalable way to schedule, observe and troubleshoot Dataflow jobs.
We are excited to announce a new capability - Dataflow Pipelines - into Preview that address the problem of managing Dataflow jobs at scale. Dataflow Pipelines introduces a new management abstraction - Pipelines - that map to the logical pipelines that users care about and provides a single pane of glass view for observation and management.
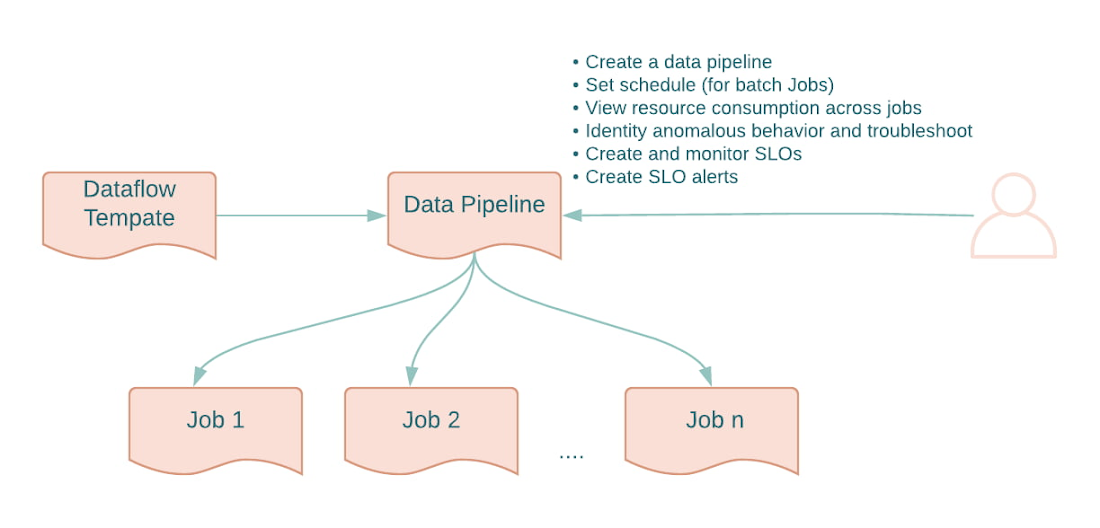
With Data Pipelines, data engineers can easily perform tasks such as the following.
Running jobs on a recurring schedule: With Data Pipelines, users can “schedule” recurrent batch jobs by just providing a schedule in cron format. The pipeline will then automatically create Dataflow jobs as per the schedule. The input file names can be parameterized for incremental batch pipeline processing. Dataflow uses Cloud Scheduler to schedule the jobs.
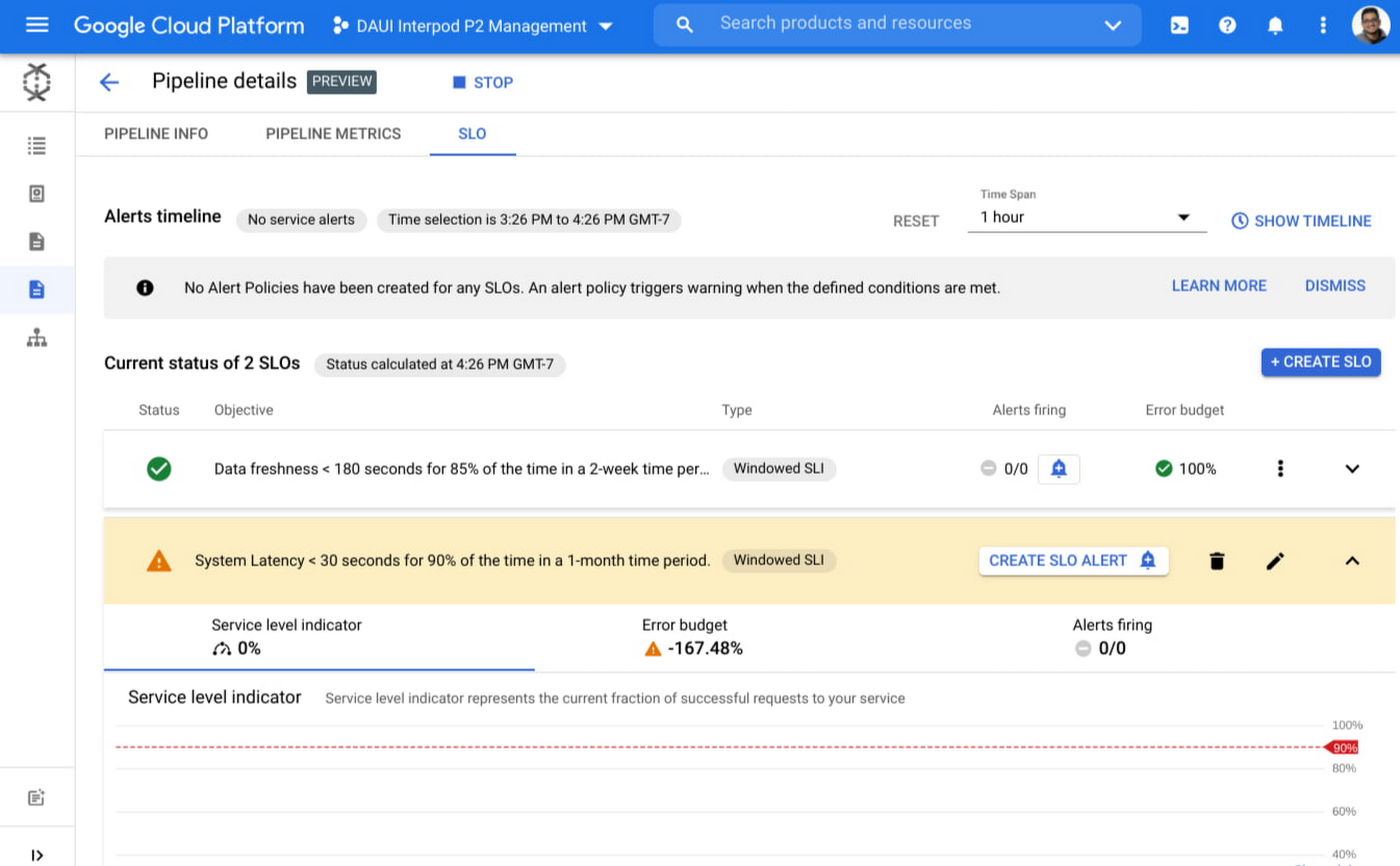
Creating and tracking SLO: One of the key monitoring goals is to ensure that data pipelines are delivering data that the downstream business teams need. In the past, it was not easy to define SLOs and set up alerts on those. With Data Pipelines, SLO configuration and alerting is natively supported and users can define them easily at Pipeline level.
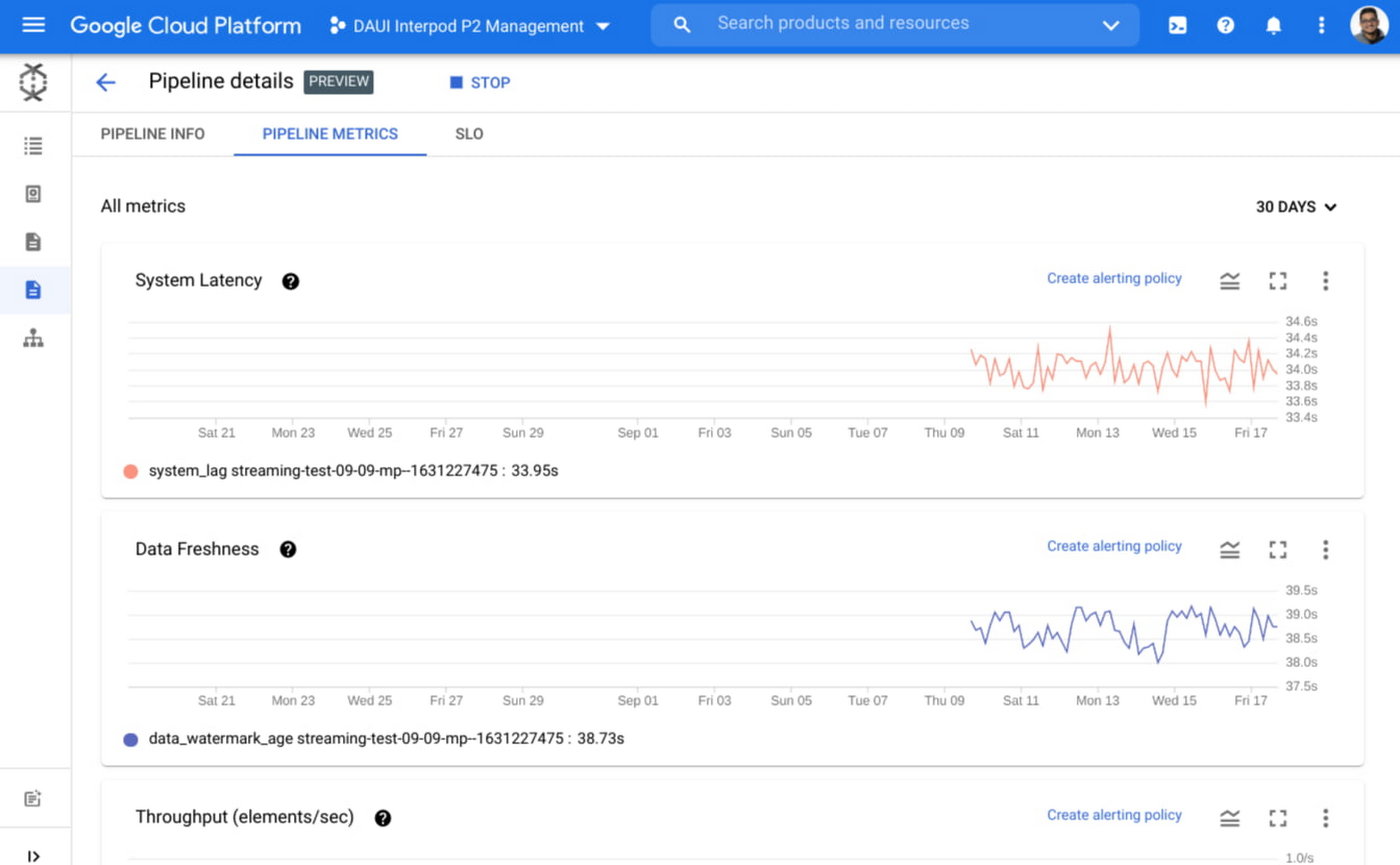
Health monitoring & Tracking: Data Pipelines makes it easy to monitor and reason about your pipelines by providing aggregated metrics on a project and at a pipeline level. These metrics (both batch and streaming) along with history of previous execution runs provide a detailed overview of the pipelines at a glance. In addition, the ability to easily identify problematic jobs and dive into the job level pages makes troubleshooting easier.
Here is a short video that provides an overview of Data Pipelines.

If you have any feedback or questions, please write to us at google-data-pipelines-feedback@googlegroups.com.


