Streaming graph data with Confluent Cloud and Neo4j on Google Cloud
Ezhil Vendhan
Senior Cloud Partner Architect, Neo4j
Elena Cuevas
Manager, Cloud Partner Solutions Engineering, Confluent
There are many ways to classify data. Data can be characterized as batch and streaming. Similarly data can be characterized as tabular or connected. In this blog post, we’re going to explore an architecture focused on a particular kind of data — connected data which is streaming.
Neo4j is the leading graph database. It stores data as nodes and relationships between those nodes. This allows users to uncover insights from connections in their connected data. Neo4j offers Neo4j Aura, a managed service for Neo4j.
Apache Kafka is the de facto tool today for creating streaming data pipelines. Confluent offers Confluent Cloud, a managed service for Apache Kafka. In addition, Confluent provides the tools needed to bring together real-time data streams to connect the whole business. Its data streaming platform turns events into outcomes, enables intelligent, real-time apps, and empowers teams and systems to act on data instantly.
Both these products are available on Google Cloud, through Google Cloud Marketplace. Used together, Neo4j Aura and Confluent Cloud provide a streaming architecture that can extract value from connected data. Some examples include:
Retail: Confluent Cloud can stream real-time buying data to Neo4j Aura. With this connected data in Aura, graph algorithms can be leveraged to understand buying patterns. This allows for real time product recommendations, customer churn prediction. In supply chain management, use cases include finding alternate suppliers and demand forecasting.
Healthcare and Life Sciences: Streaming data into Neo4j Aura allows for real-time case prioritization and triaging of patients based on medical events and patterns. This architecture can capture patient journey data including medical events for individuals. This allows for cohort based analysis across events related to medical conditions patients experience, medical procedures they undergo and medication they take. This cohort journey can then be used to predict future outcomes or apply corrective actions.
Financial Services: Streaming transaction data with Confluent Cloud into Neo4j Aura allows for real time fraud detection. Previously unknown, benign-looking fraud-ring activities can be tracked in real-time and detected. This reduces the risk of financial losses and improves customer experience.
This post will take you through setting up a fully managed Kafka cluster running in Confluent Cloud and creating a streaming data pipeline that can ingest data into Neo4j Aura.
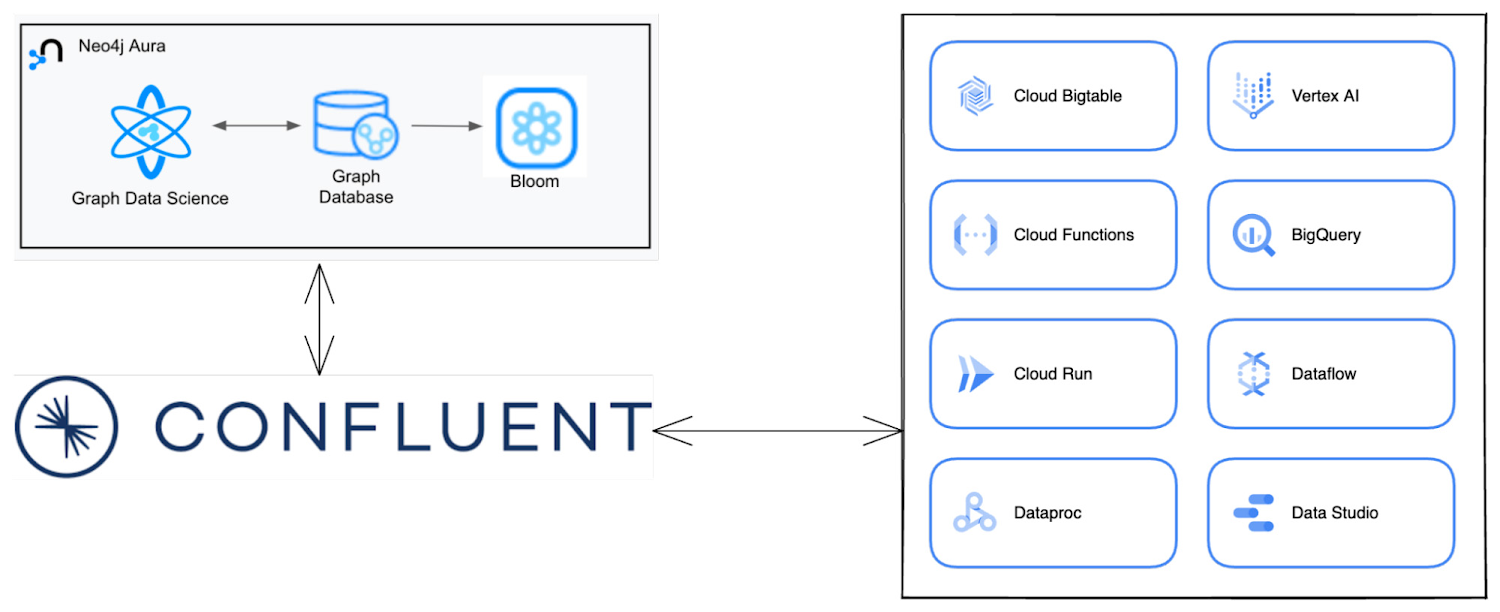
In this example we generate a message manually in Confluent Cloud. For production implementations, messages are typically generated by upstream systems. On Google Cloud this includes myriad Google services that Confluent Cloud can connect to such as Cloud Functions, BigTable and Cloud Run.
Pre-requisites
So let's start building this architecture. We’ll need to set up a few things:
Google Cloud Account: You can create one for free if you don’t have one. You also get $300 credits once you sign-up.
Confluent Cloud: The easiest way to start with Confluent Cloud is to deploy through Google Cloud Marketplace. The relevant listing is here.
Neo4j Aura: To get started with Neo4j Aura, just deploy it via Google Cloud Marketplace here.
A VM: We need a terminal to execute confluent CLI commands and run docker. You can create a VM using Google Compute Engine (GCE).
Creating a Kafka topic
To start we’re going to need to create a Kafka cluster in Confluent Cloud. Then we’ll create a Kafka topic in that cluster. The steps below can be done via the Confluent Cloud UI. However, let's do it via command line so that it is easier to automate the whole process.
First, open a bash terminal on your GCE VM. Then, let’s install the Confluent CLI tool.curl -sL --http1.1 https://cnfl.io/cli | sh -s -- latest
Login to your Confluent accountconfluent login --save
We have to create an environment and cluster to use. To create an environment:confluent environment create test
To list down the environments available, run:confluent environment list
This command will return a table of environment IDs and names. You will find the newly created `test` environment in the result. Let’s try to use its environment ID to create all the resources in the `test` environment. In my case, `env-3r2362` is the ID for the `test` environment. confluent environment use env-3r2362
Using this environment, let’s create a kafka cluster on the GCP `us-central1` region.confluent kafka cluster create test --cloud gcp --region us-central1
You can choose some other region from the list of supported regions:confluent kafka region list --cloud gcp
You can obtain the cluster ID by executing:confluent kafka cluster list
Now, let’s use the environment and cluster created above.confluent environment use testconfluent kafka cluster use lkc-2r1rz1
An API key/secret pair is required to create a topic on your cluster. You also need it to produce/consume messages in a topic. If you don’t have one, you can create it using:confluent api-key create --resource lkc-2r1rz1
Now, let’s create a topic to produce and consume in this cluster using:confluent kafka topic create my-users
With these steps, our Kafka cluster is ready to produce and consume messages.
Creating a Connector instance
The Neo4j Connector for Apache Kafka can be run self-managed on a container inside Google Kubernetes Engine. Let’s create a `docker-compose.yml` and run a Kafka connect instance locally.
In the docker-compose file, we are trying to create and orchestrate a Kafka Connect container. We use the `confluentinc/cp-kafka-connect-base` as the base image. The connector will be running and exposed on port 8083.
Upon container start, we are going to install a Neo4j Sink Connector package via confluent-hub. Once the package is installed, we should be good to create a Sink instance running within the container.
First, let’s set the environment variables that the base image expects.
In the following snippet, replace your Kafka URL and Port, which can be gotten from Confluent Cloud.
`<KAFKA_INSTANCE_URL>` with your Kafka URL
`<KAFKA_PORT>` with your Kafka Port.
We are creating topics specific to this connector for writing configuration, offset and status data. Since we are going to write JSON data, let’s use JsonConverter for `CONNECT_KEY_CONVERTER` and `CONNECT_VALUE_CONVERTER`.
Our Kafka cluster inside confluent is protected and has to be accessed via a Key and Secret.
Kafka API and Secret created during setup has to be used to replace `<KAFKA_API_KEY>` and `<KAFKA_API_SECRET>` inside CONNECT_SASL_JAAS_CONFIG and CONNECT_CONSUMER_SASL_JAAS_CONFIG variables.
With all the Connector variables set, let’s focus on installing and configuring the Neo4j Sink connector. We have to install the binary via Confluent-hubconfluent-hub install --no-prompt neo4j/kafka-connect-neo4j:5.0.2
Sometimes, the above command might fail if there is any bandwidth or connection issue. Let’s keep trying until the command succeeds.
Once the package is installed, we have to use the RESTful API that the connector provides to install and configure a Neo4j Sink instance. Before that let’s wait until the connector worker is running:
After the worker is up, we can use the REST API to create a new Neo4j Sink Connector instance that listens to our topic and writes the JSON data in Neo4j.
In the config below, we are listening to a topic named `test` "topics": "my-users" and ingest the data via this cypher command: "MERGE (p:Person{name: event.name, surname: event.surname})" defined in the "neo4j.topic.cypher.test" property. Here, we are using a simple command to create or update a new Person node defined in the test topic.
You might have to replace the <NEO4J_URL>, <NEO4J_PORT>, <NEO4J_USER>, <NEO4J_PASSWORD> placeholders with appropriate values.
Finally, let’s wait until this connector worker is up.
This is the complete docker-compose.yml. Ensure that you replace all the placeholders mentioned above:docker-compose up
Sending a message
Let’s write some messages via Confluent UI to test whether they get persisted on Neo4j. Go to your Confluent Cloud UI, click on your environment
You will now see the clusters within the environment. Click the cluster you created previously.
From the sidebar on the left, click on the `Topics` section and the `my-users` topic we created previously.
From the messages tab, you can start producing messages to this topic by clicking on the `Produce a new message to this topic` button.
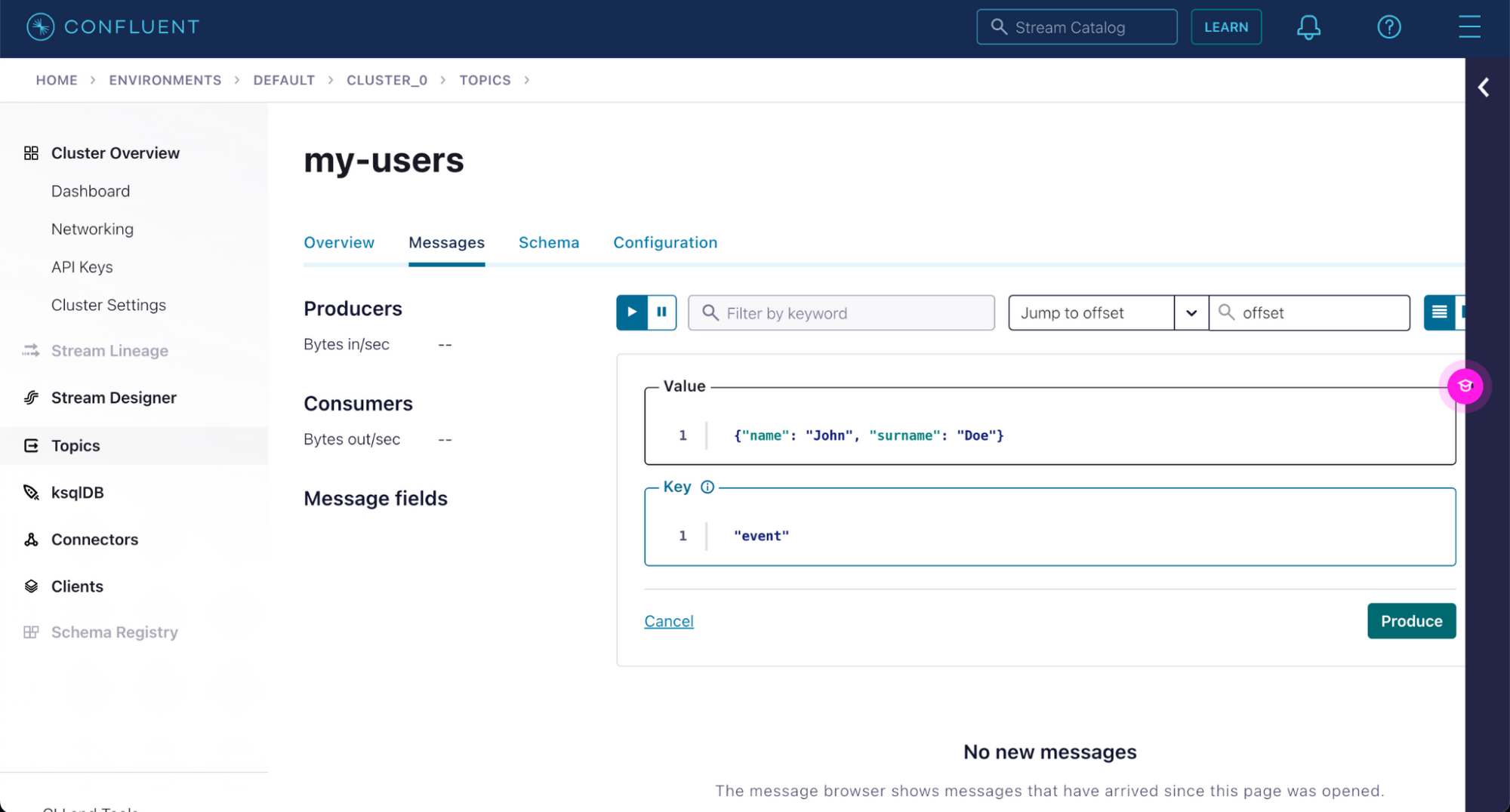
Click the `Produce` button once you are done.
Alternatively, you can also write messages to our `my-users` topic via the command line.
Confluent CLI provides a command to write and consume messages from topics. Before using this command ensure that you are using an api-key.confluent api-key use <API_KEY> --resource lkc-2r1rz1
confluent kafka topic produce my-users --parse-key --delimiter ":"
Using the last command, we can add messages containing key and value separated by a delimiter “:” in the topic."event":{"name": "John", "surname": "Doe"}
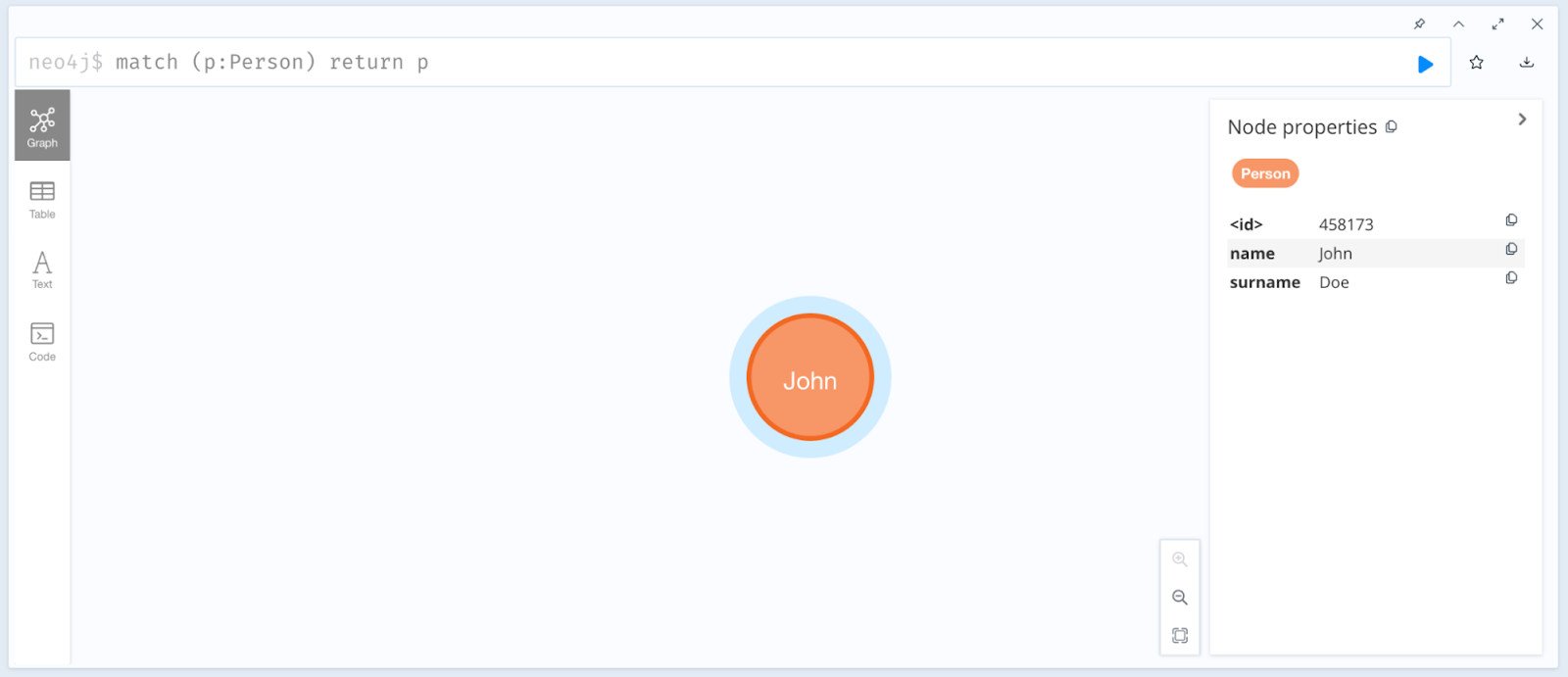
Go to your Neo4j Browser and check for the new Person node created with name ‘John’ and surname ‘Doe’.
Conclusion
In this blog post, we walked through setting up Confluent Cloud and Neo4j Aura on Google Cloud. We then used the Neo4j Connector for Apache Kafka to bridge between them. With that environment created, we tested sending a message through Confluent Cloud and capturing it in the Neo4j database. You can try this yourself with a Google Cloud account and the marketplace listings for Neo4j Aura and Confluent Cloud.
Confluent is a great data streaming platform to capture high volume of data in motion. Neo4j is a native graph platform that can sift through the connected data to deliver highly contextual insights in a low latency manner. In a highly connected world, real-time insights can add huge value to businesses. Customers across verticals are using Confluent Cloud and Neo4j to solve problems the moment they happen. Graph Data Science algorithms are leveraged to understand the seemingly random network, derive hidden insights, predict and prescribe the next course of action.
To know more about Neo4j and its use cases, reach out to ecosystem@neo4j.com.


