Introducing Python 3, Python streaming support from Cloud Dataflow
Mehran Nazir
Product Manager, Google Cloud
Ankur Goenka
Software Engineer
Streaming analytics is becoming an essential part of data platforms, helping businesses collect and analyze data in real time. At Cloud Dataflow, we’ve noticed a few trends in the data engineering industry. First, Python is emerging as one of the most popular choices for data analysts, and second, a growing number of apps are powered by streaming analytics. With these trends in mind, we’re excited to announce the general availability of Python 3 and streaming support for the Python SDK.
Stack Overflow’s 2019 developer survey found that Python is the fastest growing major programming language, while a JetBrains survey observed that data analysis has become more popular than web development among Python users. In order to better serve this rapidly growing community, the developers of the Python language announced that Python 2 would be sunset in 2020. A consortium of open-source projects (including Apache Beam, the open-source SDK supported by Cloud Dataflow) followed suit by pledging to drop support for Python 2 no later than 2020.
Separately, streaming analytics is becoming the standard for data analytics and ML. The most innovative companies are augmenting their data-driven analytics, letting teams make better strategic decisions with event-driven analytics, which enhances operational agility. Streaming analytics lets you take advantage of use cases such as personalization, fraud detection, IoT applications, and countless more. At Google Cloud Platform (GCP), our fully managed, no-ops streaming analytics stack comes in the form of Cloud Pub/Sub for data ingestion and Cloud Dataflow for data processing. (This pair was recently named a leader in the Forrester Wave for Streaming Analytics, Q3 2019.)
We’re pleased to add support for Python 3 to help those of you still running in environments that will be imminently unsupported. This support means you can take advantage of the latest and greatest that Python has to offer. Python streaming will give data engineers the entire suite of streaming features that are offered by Cloud Dataflow, which include:
Update: The ability to update your streaming pipeline (such as to improve or fix bugs in your pipeline code, or handle changes in data format)
Drain: The ability to drain your data, which prevents data loss when finishing your streaming job
Autoscaling: Cloud Dataflow’s unique capability lets you choose the appropriate number of worker instances to complete your job and dynamically re-allocate more or fewer workers to account for changing traffic patterns
Streaming Engine: Our next-generation streaming architecture will allow for a reduction in worker resources and more responsive autoscaling
Getting started with Python 3 and Python streaming
Follow the instructions in the quickstart to get up and running with your first pipeline. When installing the Apache Beam SDK, make sure to install version 2.16 (or above).
Command Line: pip install apache-beam[gcp]

You can use the Apache Beam SDK with Python versions 3.5, 3.6, or 3.7 if you are keen to migrate from Python 2.x environments. After installation, you are ready to author your first streaming pipeline!
In keeping with big data tradition, let's look at a word count example, except we’ll analyze a stream of data. Here, you can see a snippet of code that consumes a stream of text data from Cloud Pub/Sub, defines a fixed window of 15 seconds, computes the count of distinct words within each 15-second window, and then writes the results to Cloud Pub/Sub:

Navigate to the Cloud Dataflow section in the Cloud Console to see the job graph and associated metrics:
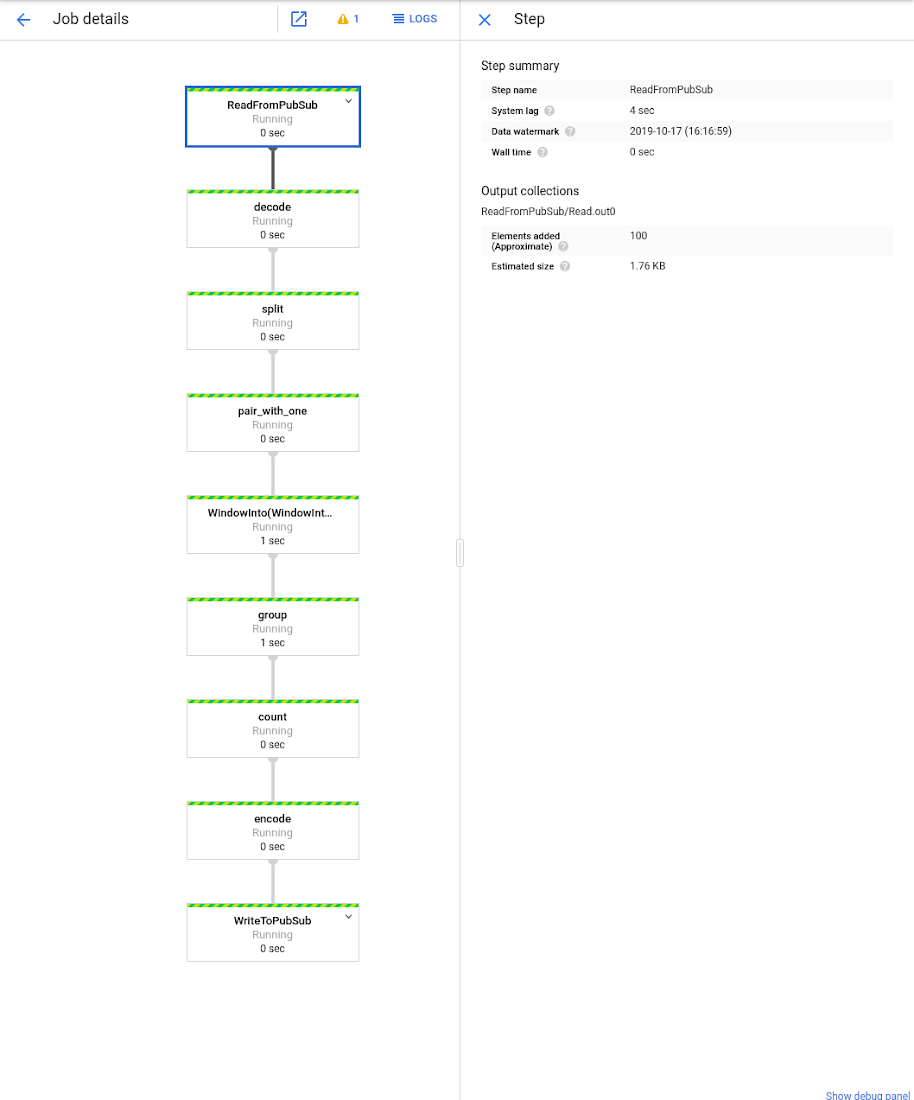
Take Python streaming on Cloud Dataflow for a spin. Learn more in this handy Python Quickstart.
