Introducing Looker Incremental PDTs: benefits and use cases
Aleksandra Aleksic
Looker Product Managers, Google Cloud
Joel McKelvey
Looker Product Managers, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialWith the cost of cloud-based services making up an increasingly large part of companies’ budgets — and with businesses fueled by access to vital data resources — it makes sense that cost and performance optimization is top-of-mind for most data teams.
Transformation and aggregation of data can reduce the total amount of data queried. This improves performance and, for those on pay-for-use cloud billing plans, also keeps expenses low. As an analyst, you can utilize Looker’s persistent derived tables (PDTs) and the new incremental PDTs as tools in your performance-improving, cost-saving efforts.
Faster query responses and lower costs with PDTs
Persistent derived tables are the materialized results of a query, written to the Looker scratch schema in the connected database and rebuilt on a defined schedule. Commonly used to reduce database load and increase query performance, PDTs mean fewer rows of data are queried for subsequent responses. PDTs are also the underlying mechanism for Looker’s aggregate awareness, allowing Looker to intelligently query the smallest possible dataset for any query using computational algebra.

PDT use cases
PDTs are highly flexible and agile because they are built and controlled directly by data analysts. Changes can be implemented in moments, avoiding lengthy ticketing processes with data engineering teams. Analysts do not need to rely on data engineering for every iterative improvement to materialized transformation. Plus, implementing PDTs can be accomplished with only a few lines of Looker’s modeling language (LookML). If necessary, PDTs can be optimized for your specific database dialect using customized persistence and performance strategies, too.
One common use case for PDTs is data transformation or in-warehouse data post-ETL processes. Data teams use PDTs to normalize data, as well as for data cleansing and quality improvements. Because PDTs are rebuilt on a defined persistence schedule, the data in these persistent tables remains fresh and relevant, never stale.
Incremental PDTs: the faster and more efficient option
Data teams who have implemented PDTs have found them to be extremely powerful. But there were some use cases for which PDTs were not well suited — data teams using prior versions of Looker PDTs found that the scheduled rebuilding to ensure data freshness was cumbersome when data tables were especially large (PDT rebuilds were themselves resource intensive) or when data was changed or appended frequently (PDT rebuilds were necessarily frequent). You can now use incremental PDTs to overcome these challenges and make PDTs useful as datasets get larger and less mutable.
How are incremental PDTs different?
Standard PDTs remain extremely valuable for small datasets, or for data that is frequently changing. But, as data sets get bigger and less mutable, PDTs can start taking a long time to build and become expensive to compute, particularly because it becomes necessary to frequently rebuild standard PDTs from scratch. This is where incremental PDTs come in. They allow you to append fresh data to the PDT without a complete rebuild, skirting the need for an expensive rebuild of the table in its entirety. This can save considerable time and further drive down costs. In fact, companies who have helped test the feature have reported that their queries return data 10x-20x faster.
How to use incremental PDTs
Implementing incremental PDTs requires a single simple parameter (increment_key) in LookML. Incremental PDTs are supported in a range of database dialects, but be sure to check our list of supported dialects before beginning implementation. Incremental PDTs are supported for all types of PDTs: Native (LookML), SQL-based, and aggregate tables.

You can even account for late arriving data by using an increment offset (via the optional increment_offset parameter), which offers the flexibility to rebuild defined portions of the table independently. This helps ensure tables are not missing any data or compromising data accuracy.
When to use incremental PDTs
Identifying candidate queries for incremental PDTs can be as simple as finding PDTs with long build times in the “PDT Overview” section of the System Activity Database Performance Dashboard. This pre-curated dashboard is a good starting point to identify PDTs that take longer periods to build or build slowly.
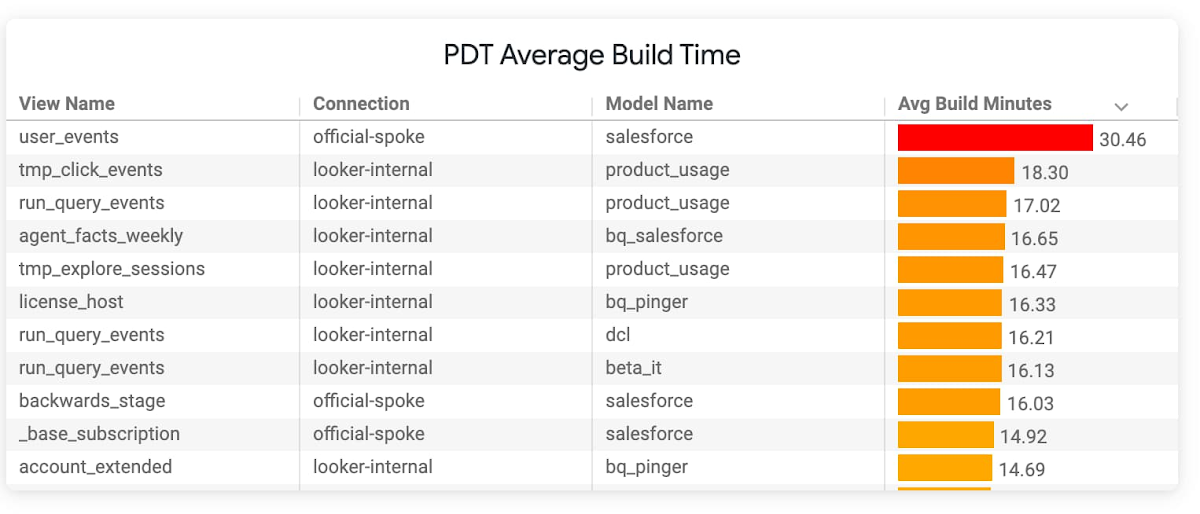
To use a table with incremental PDTs, they do need to be persisted (a consistent source for data) and must have a timestamp column. Tables with immutable rows, such as those resembling event streams, are excellent candidates for incremental PDTs. A common use case for incremental PDTs is event streams and other data types where the bulk of the data remains unchanged but new data is appended frequently to the source table.
For more example incremental PDT use cases and for details on how to test the behavior of incremental PDTs in Looker development mode, please refer to the incremental PDT documentation.
Learn more about Looker PDTs
Some resources to help you with performance and cost efficiency and PDTs include:
- Implementing Incremental PDTs with Kai Banks (video)
- Incremental PDTs (Looker Docs)
- The Power of Looker Transformations with Aleks Aleksic (video, JOIN 2020)
- Identifying and Building PDTs for Performance Optimization by Mike DeAngelo (Looker Help)
- Derived Tables in Looker (Looker Docs)
- Optimizing Queries for Aggregate Awareness (video, JOIN 2020)
- Aggregate Awareness Tutorial by Sean Higgins (Looker Help)
- Aggregate Awareness (Looker Docs)
Want to know more about Looker and how to create fast, efficient, powerful analytics for your organization? You can request a Looker demo to learn how Looker uses an in-database architecture to get the most out of your database investment.



