Improve the data science experience using scalable Python data processing
Brad Miro
Developer Advocate
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialPython has quickly solidified itself as one of the top languages for data scientists looking to prep, process, and analyze data for analytics and machine learning related use cases. Dask is a Python library for parallel computing with similar APIs to the most popular Python data science libraries such as Pandas, NumPy and scikit-learn. Dask’s parallel processing leads to greater efficiencies and lower latency for machine learning and data processing tasks. Today, we’re excited to announce Dask support for Dataproc, Google Cloud’s fully managed Apache Hadoop and Apache Spark service, via a new Dask initialization action. With this Dataproc initialization action we’ve made it even easier for data scientists to get Dask up and running on a Dataproc cluster.
Today, Dask is the most commonly used parallelism framework within the PyData and SciPy communities. Dask is designed to scale from parallelizing workloads on the CPUs in your laptop to thousands of nodes in a cloud cluster. In conjunction with the RAPIDS framework developed by NVIDIA, you can utilize the parallel processing power of both CPUs and NVIDIA GPUs.
Dask is built for the Python data science community
Dask is built on top of NumPy, Pandas, Scikit-Learn and other popular Python data science libraries. As such, the APIs are deliberately designed to help you seamlessly transition from these core libraries to the scalable Dask versions of each. The Dask documentation shows some excellent examples of how some of these libraries translate to Dask, which you can find here.
How Dask is used
Dask is being used by data science teams working on a wide range of problems, including high-performance computing, climate science, banking and imaging problems. Additionally, Dask is also well-suited for business intelligence problems. See here for a list of problems that teams have made progress using Dask.
Why use Dask on Dataproc
Dask provides a fast and easy way to run data transformation jobs on your big data. With Dask-Yarn, a Skein-based tool for running Dask applications on Yarn, the task scheduling is relegated to the YARN scheduler, freeing you from needing to manage another set of software on your cluster. Yarn takes care of allocating the resource management necessary to finish processing your jobs. Additionally, you get access to the full set of features offered by the Dataproc service, including Autoscaling, Jupyter component and component gateway for submitting jobs via a Jupyter Notebook.
Dask supports data loads from many different sources such as GCS and HDFS, and many different data types such as CSV, parquet and avro. These are supported by different projects such PyArrow, GCSFS, FastParquet, and FastAvro, all of which are included with Dataproc.
Additionally, you can also configure Dask on Dataproc to utilize Dask with its native scheduler, as opposed to Yarn.
Create a Dataproc cluster with Dask
You can create a Dataproc cluster by selecting a region with the Dask initialization action, Jupyter optional component and component gateway enabled with the following command.
You can alternatively create a cluster by changing the dask-runtime metadata parameter to standalone.
Interacting with your cluster
With Dask configured in your environment, you can now run Dask jobs by either using a notebook environment such as Jupyter or SSHing into the master node of your cluster and executing a Dask script.
SSH into your cluster’s master node with the following command.
You can then use the Python base environment to submit jobs. Copy the following into a Python file on your cluster, dask_job.py, which will create a YarnCluster object with which you can interact with your Dask cluster, add the ability for Dask to scale resources as needed, and sum an array.
Submit the job.
Your output should be a floating point number.
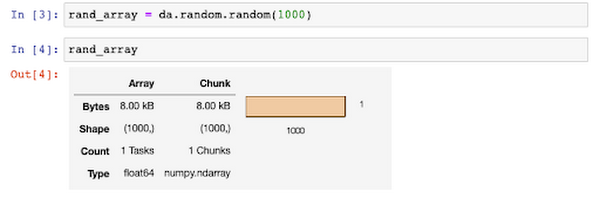
You can also use a notebook for executing your Dask jobs. Using a notebook comes with some extra added bonuses, such as viewing graphical representations of your data structures.
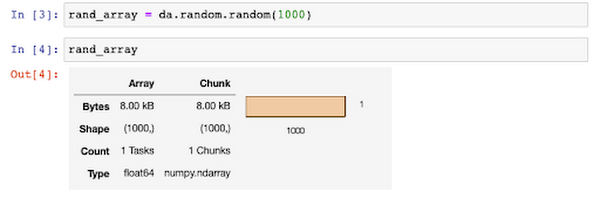
Additionally, Dask with Jupyter notebooks provide a graphical interface for managing resources on your Dask cluster, in addition to doing so via the API.
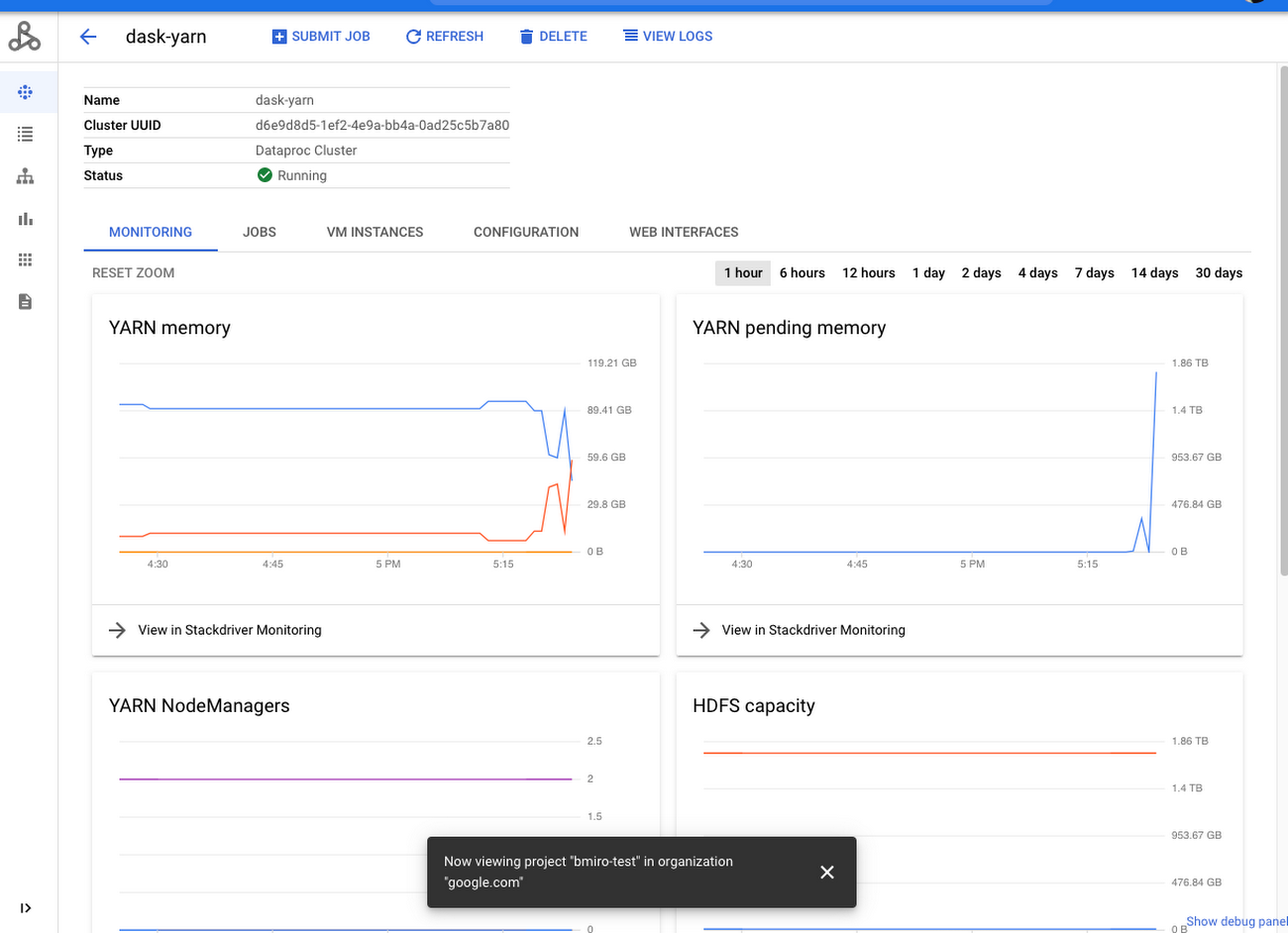
Monitoring Dask workloads
You can take advantage of multiple Web UIs for monitoring your Dask applications. With Dask-Yarn, you can take advantage of the Dataproc console’s cluster monitor to view metrics such as YARN memory and YARN pending memory.
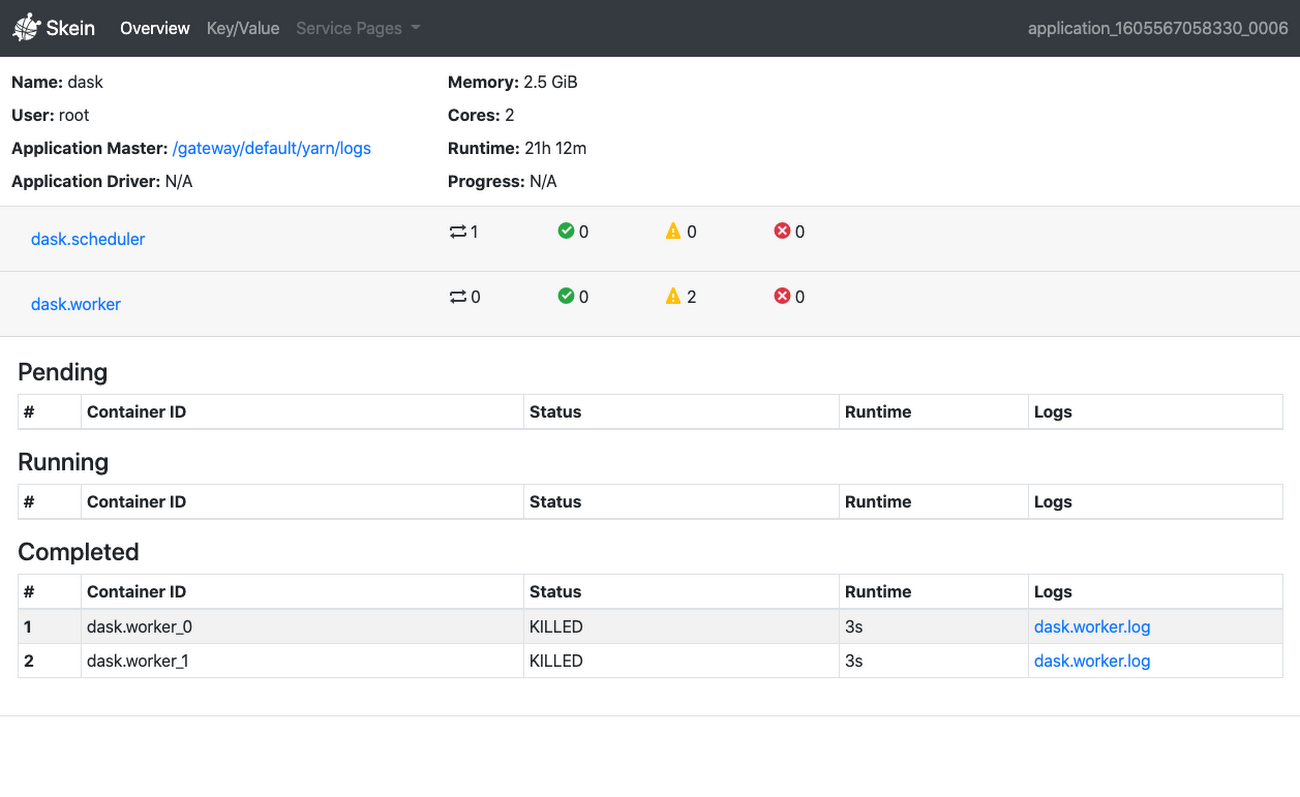
You can also access the Skein Web UI when using Dask-Yarn. You can find this as your application’s Application Master within the YARN ResourceManager, which you can access with component gateway.
If using Dask’s standalone scheduler, you can access the Dask Web UI via an SSH tunnel.
Combining Dask CPU parallelism with NVIDIA RAPIDS GPU parallelism
You can combine the CPU parallelism capabilities of Dask with the NVIDIA GPU parallelism capabilities of the RAPIDS open source data science framework, which Dataproc also supports. You can create a Dataproc cluster with Dask, RAPIDS, NVIDIA GPUs and the necessary drivers with the following command.
For more information about the RAPIDS and Dask ecosystem, including crossover libraries such as dask_cudf check out the RAPIDS documentation here.
Conclusion
Dask is an exciting framework that has seen tremendous growth over the past few years. We look forward to seeing what you’re able to accomplish with it on Dataproc! For more information on how to get started with Dask on Dataproc, check out this quickstart in the official Dask documentation. You can also get started using Dask on Dataproc with Google Cloud Platform’s $300 credit for new customers. .



