Tokopedia’s journey to creating a Customer Data Platform (CDP) on Google Cloud Platform
Kent Stanley
Data Engineering Lead , Tokopedia
Founded in 2009, Tokopedia is an ecommerce platform that enables millions of Indonesian to transact online. As the company grows, there is an urgent need to better understand customer’s behavior in order to improve the customer’s experience across the platform. Now, Tokopedia has more than 100 million Monthly Active Users and the demography and preferences of all these users are different. A way to meet their needs is through personalization.
Normally, a user needs to browse through thousands of products in order to find the item they are looking for. By creating product recommendations that are relevant to each user, we shorten their search journey and hopefully increase conversion early on in the journey. In order to build personalization, the Data Engineering Team’s Customer Data Platform (CDP) helped to gain access to user’s attributes. These attributes developed by the Data Engineering team come in handy for different use cases across functions and teams.
Previously, two main challenges were observed:
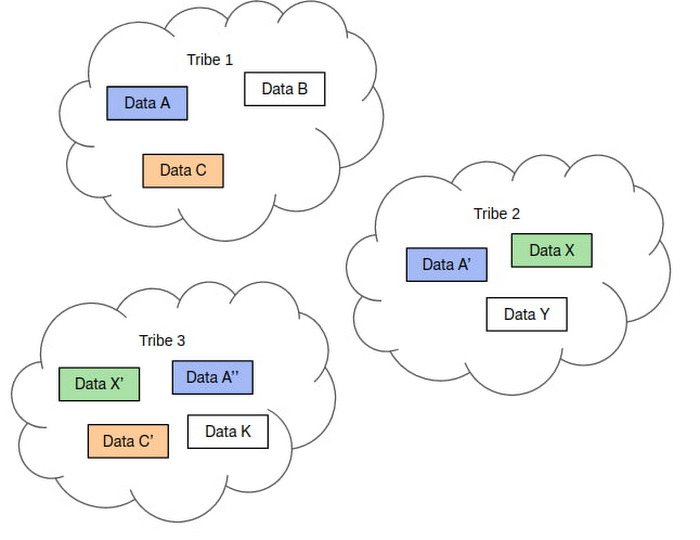
The need for speed and answers caused an increase in data silos. As the needs for personalization increased across the company, different teams have been building their own personalization features. However, the limited time and the need to simplify communication across teams have resulted in the decision for each team to create their own data pipeline. This caused a few redundancies due to the development of similar data across different teams and these redundancies caused slower development time for new personalized feature, even though some of the attributes have been previously build in a different module.
Inconsistent data definitions. As each team created their own data pipeline, there are many cases where each team had a different definition of a user's attributes. On several occasions, this caused misunderstandings during meetings and unsynchronized user journeys due to different teams applying different attribute values to the same user. For example, team A evaluated user_id 001 as a woman in their 20s. Meanwhile, team B, having a different set of attributes and definitions evaluated user_id 001 as a woman in their 30s. These differences in definition and attributes can lead to different conclusions and results, consequently giving different personalizations. As a result, customers might be facing inconsistent experience during their journey in Tokopedia and have a bad experience during their activity. Imagine that you’re being displayed by one set type of content that is related with college necessities and then in a different module you’re being given a a content that is related to mom and baby.
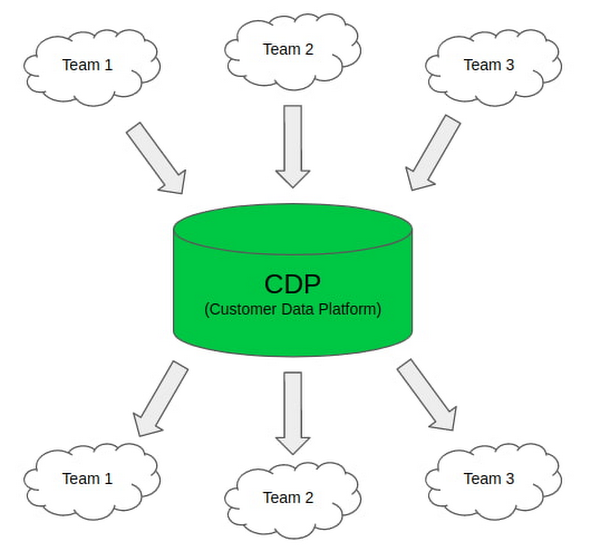
Currently, with CDP, different teams do not have to constantly rebuild the infrastructure. The same attributes will only need to be processed once, and can be used by different teams across the company. This optimizes the development time, cost, and effort. Another advantage of having CDP is the single definition of attributes across services and teams. Since different teams will be looking at the same attributes inside the CDP, this will reduce the chances of misunderstanding and strengthen synchronization between teams. This will give customers consistent experience across the Tokopedia platform and enable them to display relevant contents.
Moreover, there are several key factors required in building the CDP platform in Tokopedia. The journey is as follows:
1. Define and Make a List of Attributes
During this phase, we work with the Product and Analyst teams to define all of the user’s attributes required to build the CDP. Our product team interviewed several stakeholders to understand different perspectives regarding user attributes. As a result, an initial attributes list was made to include gender, age group, location, etc. This process is done repetitively in order to have the best understanding of the user's attributes.
2. Platform Design
After doing comprehensive reviews, we decided to build our CDP platform using several GCP tech stacks.
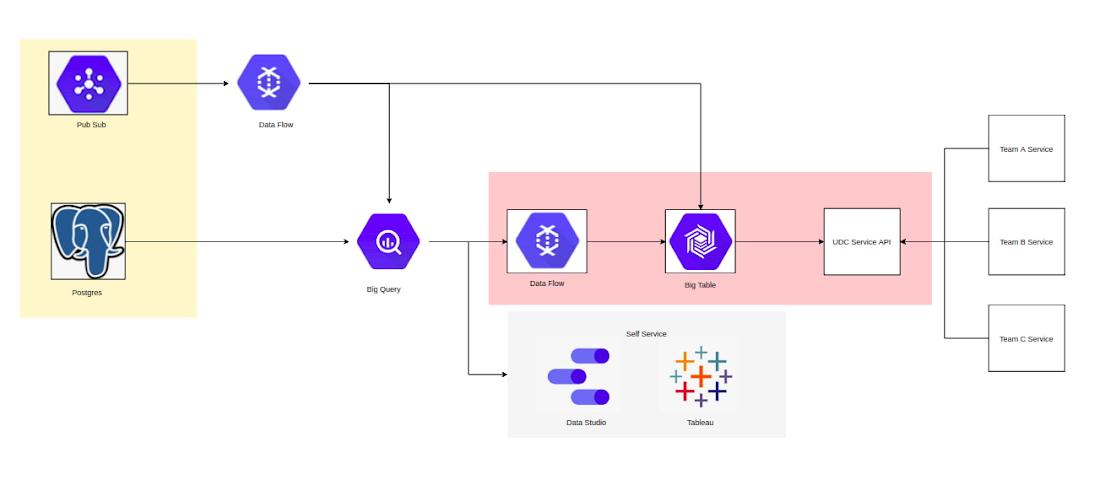
Bigquery was chosen as the analytics backend of our CDP self-service. Meanwhile, Google Cloud BigTable was selected as the backend, where our services will interact to enable the personalization. In developing the storage for Big Table, the design of the scheme is very important. The frequency and categorization will affect how we design the column qualifier while the CDP attribute will affect how we design the row key.
We also opted to create a caching mechanism to reduce the load to big tables for similar read activity. We build the cache system using redis with certain Time to Live (TTL) to ensure an optimized performance. In addition, we also applied a Role Based Access Control (RBAC) mechanism on the CDP API to ensure access control of different services towards attributes in the CDP.
3. Monitoring and alerting
Another important point in building a CDP is developing the correct monitoring and alerting system to maintain stability on our platform. A soft and hard threshold on each metric is established and monitored. Once this threshold is reached, some alerts will be sent through the communication channel. Based on the current architecture, there are several parts in which we need to enable monitoring and alerting.
Data Pipeline
One of the things that we will need to monitor is resource consumption during computation and data pipeline from data sources to the CDP storages, as we operate using Bigquery and Dataflow for Data Computation and Data Pipeline. In Bigquery, we need to monitor the slot utilization that is used to compute some data aggregation or manipulation to produce the attribute.
Data Quality
When building the CDP, high quality data was important in order for it to be a trusted platform. Several metrics that are important in terms of data quality are Data Completeness, Data Validity, Data Anomaly and Data Consistency. Therefore, several monitoring needs to be enabled to ensure these metrics.
Storage and API Performance
Since CDP’s backend and API directly interact with several front facing features, we have to ensure the availability of the CDP service. Since we’re using Big Table as the backend, the monitoring of CPU, Latency and RPS is required. This metric, by default, is provided in the Bigtable monitoring.
4. Discoverability across company
Many users have been inquiring on how they can browse attributes that our CDP offers. Initially, we started out by documenting our attributes and sharing it to our stakeholders. However, as the number of the attributes increased, it became increasingly harder for people to go through our documentation. This pushed us to start integrating the CDP terminology into our Data Catalog. In this case, our Data Catalog plays an important role in enabling users to browse attributes in CDP, including the definition of each attribute and how they can retrieve the data.
5. Implementation and adoption of the platform
Another key point for a successful CDP implementation is collaboration across teams on the front end services. There are several types of CDP implementation in Tokopedia: Personalization, Marketing Analytics, and Self Service Analytics.
Personalization
The most common usage of CDP would be in personalizing a user’s journey. One example of personalization is the search feature. The product team personalizes the user’s search result based on the user's address, so that the user will be able to find products that are in proximity to their location. After discussing the definition of user address, we created a CDP API contract with the Search team, so the development can run in parallel. As a result, today our users are able to have a better user experience based on their location.
Marketing Analytics
When we started building the CDP platform, we discussed with the Marketing team on their existing use cases. One of their goals was to personalize and optimize marketing efforts, such as sending out notifications to the right user based on the user's attributes to reduce unnecessary notification costs to unrelated users, and to enhance the overall user experience by avoiding spam notifications. Once we understood their needs, we looked at the ways in which CDP could cater to those needs. We discussed with the relevant team on how to integrate the segmentation engine and communication channel towards the CDP platform, the type of user attributes to use when sending marketing push/notifications, and how to integrate it with the segmentation engine and communication channel of the CDP platform.
Self-Service Analytics
CDP also often uses self-service analytics to enable quick insights on user demographics and behavior in certain segments. To build this self-serve analytics tool, our team consulted with the Product and Analyst teams to define the user demographics’ attributes that business/product users often select for insights. After understanding the attributes required, we discussed with the Business Intelligence team to enable the visualization for the end user. This allowed different teams to understand our users better and gain insights on how we can improve our platform.
CDP implementation has created a significant impact on different use cases and helped Tokopedia to be a more data-driven company. Through CDP, we are also able to strengthen one of our core DNA, which is Focus on Consumer. By sharing the CDP framework, we hope to bring value and help others to more easily create a thriving CDP platform.


