3 ways to restrict access to your Cloud Data Fusion instance and pipelines
Deepinder Dhuria
Product Manager
Ankit Jain
Software Engineer
Cloud Data Fusion is a fully managed, cloud-native, enterprise data integration service for visually building and managing data pipelines that are secure. Restricting access is one of the key ways it delivers on its security goals. In this blog, we explain three different ways to manage access control in Cloud Data Fusion:
-
Instance-level access control using IAM
-
Namespace-level access control using role-based access control (RBAC)
-
Isolating access using namespace service accounts
These techniques all rely on a few key concepts:
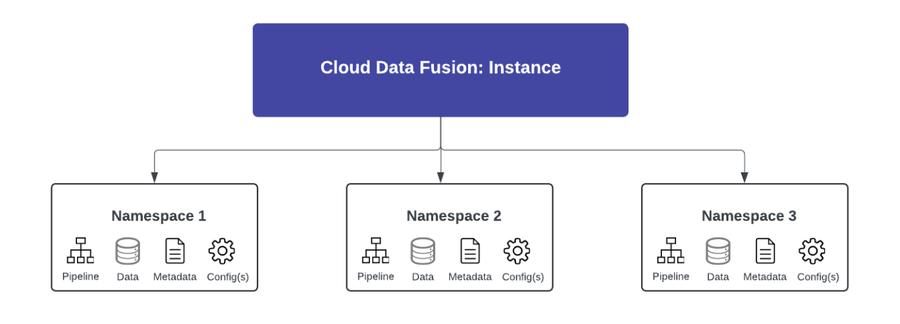
Namespaces
A namespace is a logical grouping of applications, data, and the associated metadata in a Cloud Data Fusion instance. You can think of namespaces as a partitioning of the instance.
Service accounts
A service account is essentially a special Google account designed for applications or services. Applications running on Google Cloud resources use the service account to authenticate themselves when interacting with Google Cloud APIs and services.
Cloud Data Fusion has two service accounts:
-
Design service account: typically called the Cloud Data Fusion API service agent, the design service account is used to access customer resources during pipeline design phase (e.g., preview, wrangler, and pipeline validation).
-
Execution service account: called compute engine service account and used by Dataproc to execute the pipeline.
Now, let’s take a closer look at the three levels at which you can control access In Cloud Data Fusion.
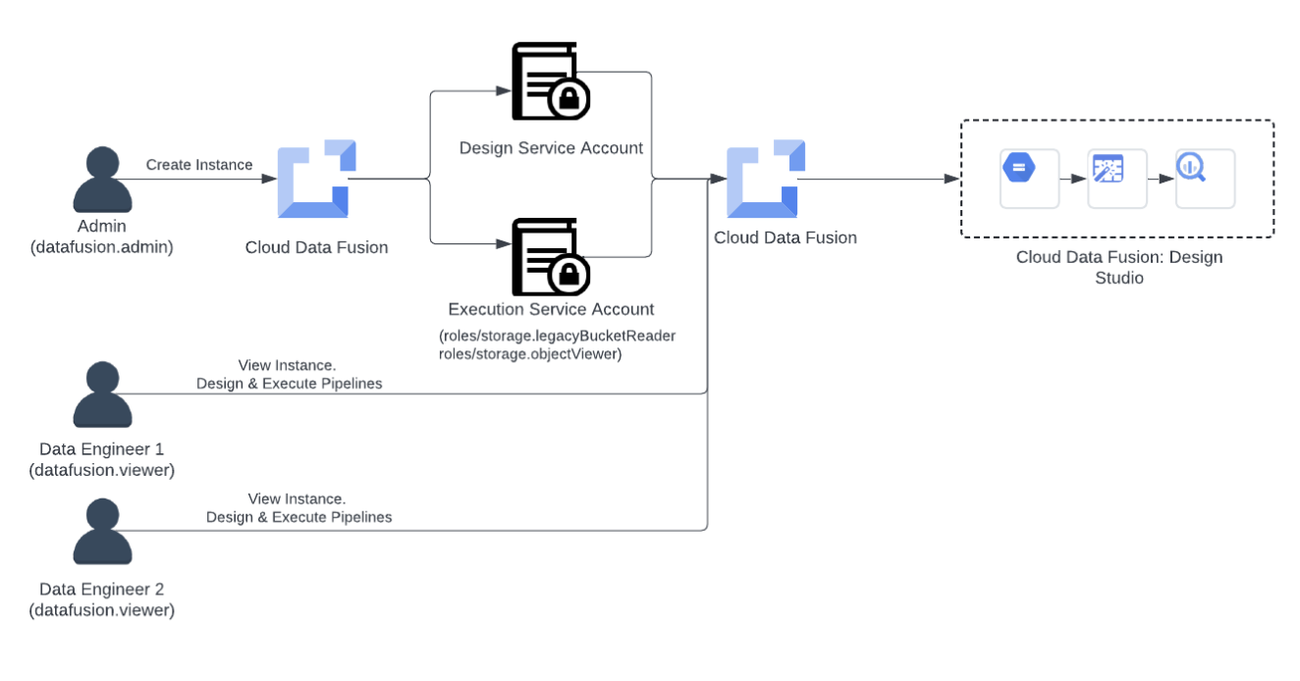
Scenario 1: Instance-level access control using IAM
Cloud Data Fusion integrates with Google Cloud services with Identity and Access Management (IAM). It has two predefined roles: admin and viewer. As a practice of the IAM principle of least privilege, the admin role should only be assigned to users who need to manage (create and delete) the instances. The viewer role should be assigned to users who only need to access the instances, not manage them.
Consider a scenario where Acme Inc. uses Cloud Data Fusion to run pipelines for its finance department. Acme Inc. wants to start with a simple access control structure and leverages IAM for managing the access as below:
Assigning IAM roles to users:
-
Acme Inc. identifies admin and data engineers in the finance department.
-
The admin is assigned “role/datafusion.admin” role so that admin can create, edit or delete a Cloud Data Fusion instance.
-
Admin then assigns “role/datafusion.viewer” role to data engineers so that they can view the instance and design and execute pipelines.
-
Data engineers get full access to Cloud Data Fusion Studio but they cannot edit or delete or upgrade Cloud Data Fusion instance
Assigning IAM roles to service accounts:
-
Data engineers at Acme Inc. want to design a pipeline to ingest data from Cloud Storage and load it into BigQuery.
-
The admin assigns followings roles to Cloud Data Fusion’s execution service account to give permission to ingest data from Cloud Storage and BigQuery:
-
roles/storage.legacyBucketReader
-
roles/storage.objectViewer
-
roles/bigquery.jobUser
-
After assigning these, a data engineer can ingest data without any restrictions from these services
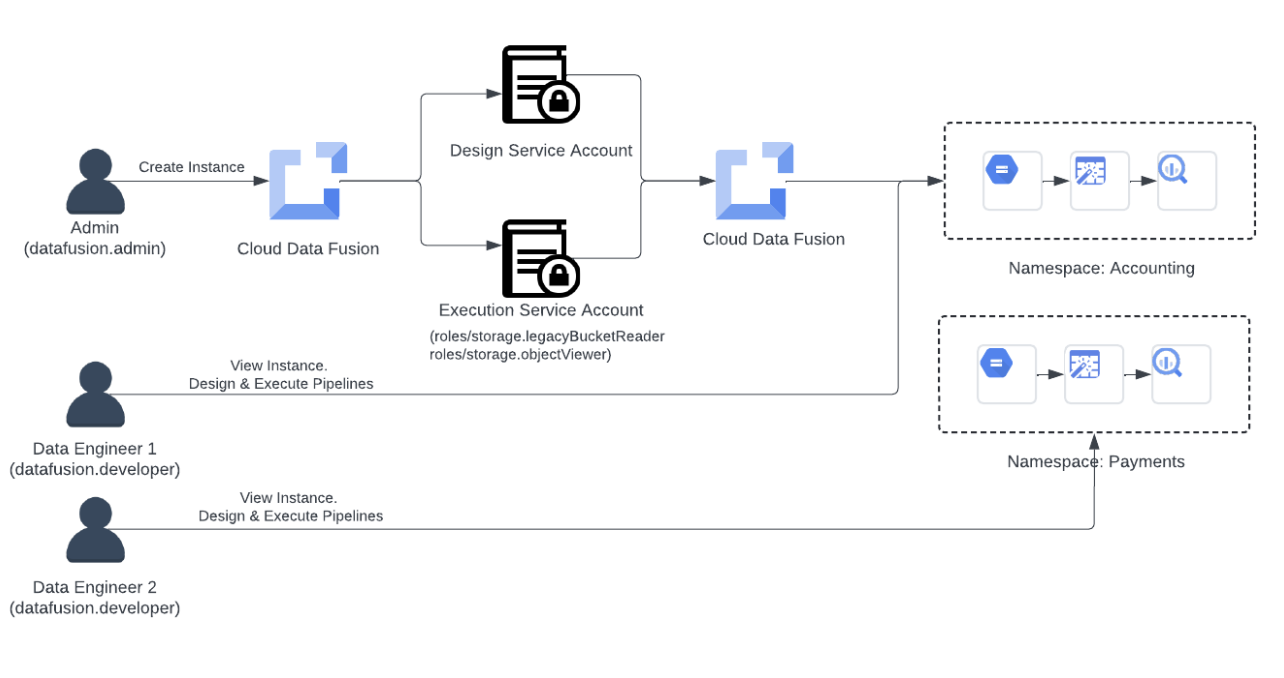
Scenario 2: Namespace-level access control using RBAC
With RBAC, Cloud Data Fusion allows you to manage fine-grained user permissions within your data pipelines, helping you manage who has access to its resources, what they can do with them, and what areas they can access within an instance. RBAC provides the following roles that can be assigned to a user at a namespace level:
-
datafusion.viewer: View pipelines
-
datafusion.operator: Run deployed pipelines
-
datafusion.developer: Design, preview and deploy pipelines
-
datafusion.editor: Full access to all resources
It also allows custom role creation.
Now Acme Inc. wants to split the usage of Cloud Data Fusion to the finance department’s accounting and payments teams. Acme Inc. creates two namespaces, one each for accounting and payments, and wants to ensure that only the accounting team’s data engineers have access to run pipelines in that namespace. Acme Inc. leverages RBAC as below:
Assigning roles to the user (or principal) at the namespace level:
-
The Cloud Data Fusion admin at Acme Inc. identifies a data engineer (DE1) in the accounting department.
-
In the permission section of Cloud Data Fusion console, the admin assigns the “Accounting” namespace to DE1.
-
Admin assigns datafusion.developer role to DE1 so that he/she can design, preview and deploy pipelines in “Accounting” namespace.
-
Similarly, the admin assigns “Payment” namespace to Data Engineer (DE2) in the payments department and assigns datafusion.developer role to DE2.
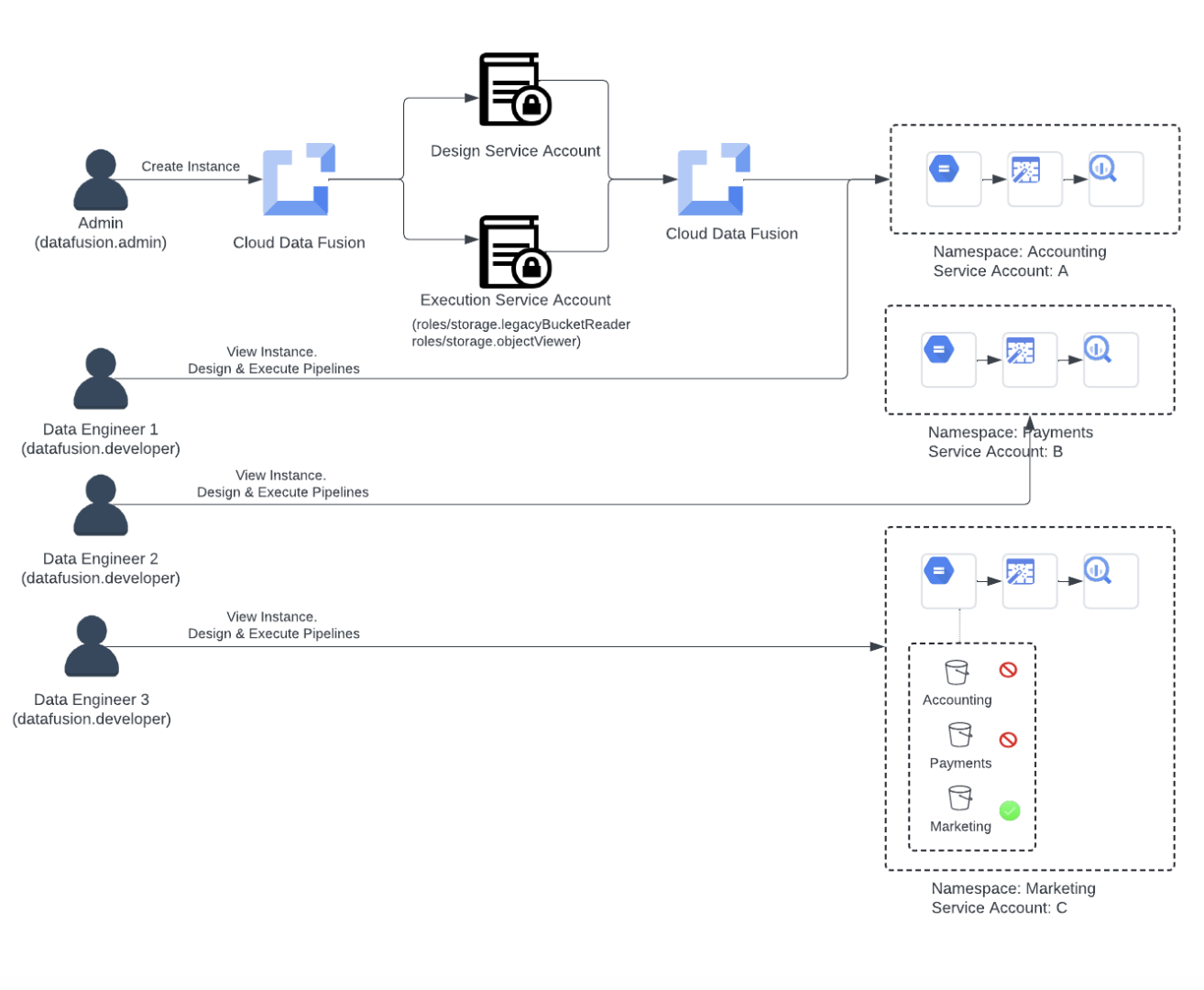
Scenario 3: Isolate access using namespace service accounts
With namespace-level service accounts, you can further isolate access to Google Cloud resources within each namespace. Namespace service accounts only isolate pipeline design-time operations like wrangler, pipeline preview, connections, etc.
Consider the Acme Inc. example. They want to expand the usage of Cloud Data Fusion to the marketing department. Acme Inc. creates a namespace for “Marketing” to ensure that while data engineers in the “Marketing” department have access to run pipelines in that namespace, they aren’t able to view any data of other departments when they design pipelines. Acme Inc. leverages namespace service accounts as below:
Assigning roles to the user (or principal) at the namespace level:
-
Acme Inc.’s Cloud Data Fusion admin identifies a data engineer (DE3) in the “Marketing” department
-
In the permission section of Cloud Data Fusion console, the admin assigns “Marketing” namespace to DE3.
-
Admin assigns datafusion.developer role to DE3 so that he/she can design, preview and deploy pipelines in “Marketing” namespace
-
DE3 has the same use case as other departments and wants to design a pipeline to ingest data from Cloud Storage and load it into BigQuery.
-
DE3 can see other department’s storage buckets when creating a new connection in its namespace.
Assigning service account at the namespace level:
-
The admin configures and assigns service account to each “Accounting”, “Payments” and “Marketing” namespace
-
Admin goes to Cloud Storage and assigns “roles/storage.objectUser” role to “Accounting”, “Payments” and “Marketing” service account principals
-
Data Engineer (DE3) goes to create a Cloud Storage connection in Cloud Data Fusion and opens up a storage bucket list. Data Engineers can see the list of buckets but can only access “Marketing” departments storage buckets.
Avoid unauthorized access and data modification
For ETL workloads, Cloud Data Fusion offers robust capabilities to minimize risks associated with unauthorized access or unintentional data modification. By carefully designing roles and strategically leveraging namespaces, you can create a tailored and secure data environment that aligns with your organization's requirements. For more information read further here.

