From data chaos to data clarity: How Tamr's Data Products leverage Google generative AI
Dr. Ali Arsanjani
Director, Applied AI Engineering, Google
Alex Pagan
Cofounder and Principal Engineer, Tamr
Enterprises of all sizes recognize the value of having accurate, complete, and up-to-date views of their business and as a result have invested heavily in their data strategy and infrastructure. With the recent advances in generative AI, the urgency for high-quality data is only increasing. However, many organizations have found that as their data footprint grows, they cannot get the promised value from their data because the key people, companies, vendors, and products that comprise their business are represented differently across several or even hundreds of databases and operational systems. This is a surprisingly challenging issue that businesses have been trying — with underwhelming success — to solve for decades with rules and governance-based master data management efforts, including via traditional MDM software or do-it-yourself and homegrown solutions.
The good news is that AI-powered answers are finally addressing this seemingly intractable problem in a way that rapidly delivers business value. Companies can now align data entities across multiple source systems in such a way as to generate the trustworthy golden records needed to improve analytics, accelerate growth, and increase efficiency. And they can do this in a matter of weeks, instead of months or years (or never). To understand more about this, it is important to investigate some details surrounding this problem and its solution.
The trouble with entity duplication
The first challenge of getting to trusted golden records is dealing with entity duplication. Even within the same system, there can be considerable duplication of customer records that precludes the delivery of trusted reports. This is what we at Tamr call the "hard problem," and it begins when an organization must identify which facets of their dataset contain the right information so they can decide whether two records represent the same entity. This process becomes exponentially more complex when disparate data sources must be resolved together. Differences in schema structure, and in particular information granularity often push data organizations to develop complex rules-based ETL pipelines in an attempt to structure data similarly, with follow-on rules for how to put records together into the same entity. Consider for example, a table with columns for all of first, middle, and last name and another that simply has a full name column… Deduping this data is error-prone, difficult to maintain, and even more difficult to tune given data drift.
To solve this hard problem, Tamr offers AI-powered Data Products that deliver accurate, enterprise-wide entity resolution and golden record creation at scale for key data domains like customers, contacts, and supplier data, amongst others. These turnkey, templated software solutions improve company-wide data using ML-based mastering models, data cleaning and standardization services, and enrichment with well-known reference datasets. By mapping the user’s input data onto a standard schema for a particular domain, Tamr’s Data Products can leverage domain-specific pipelines and ML models to deliver high-quality results to end-users. These solutions require little or no code configuration, and the entire process runs in a hosted SaaS environment.
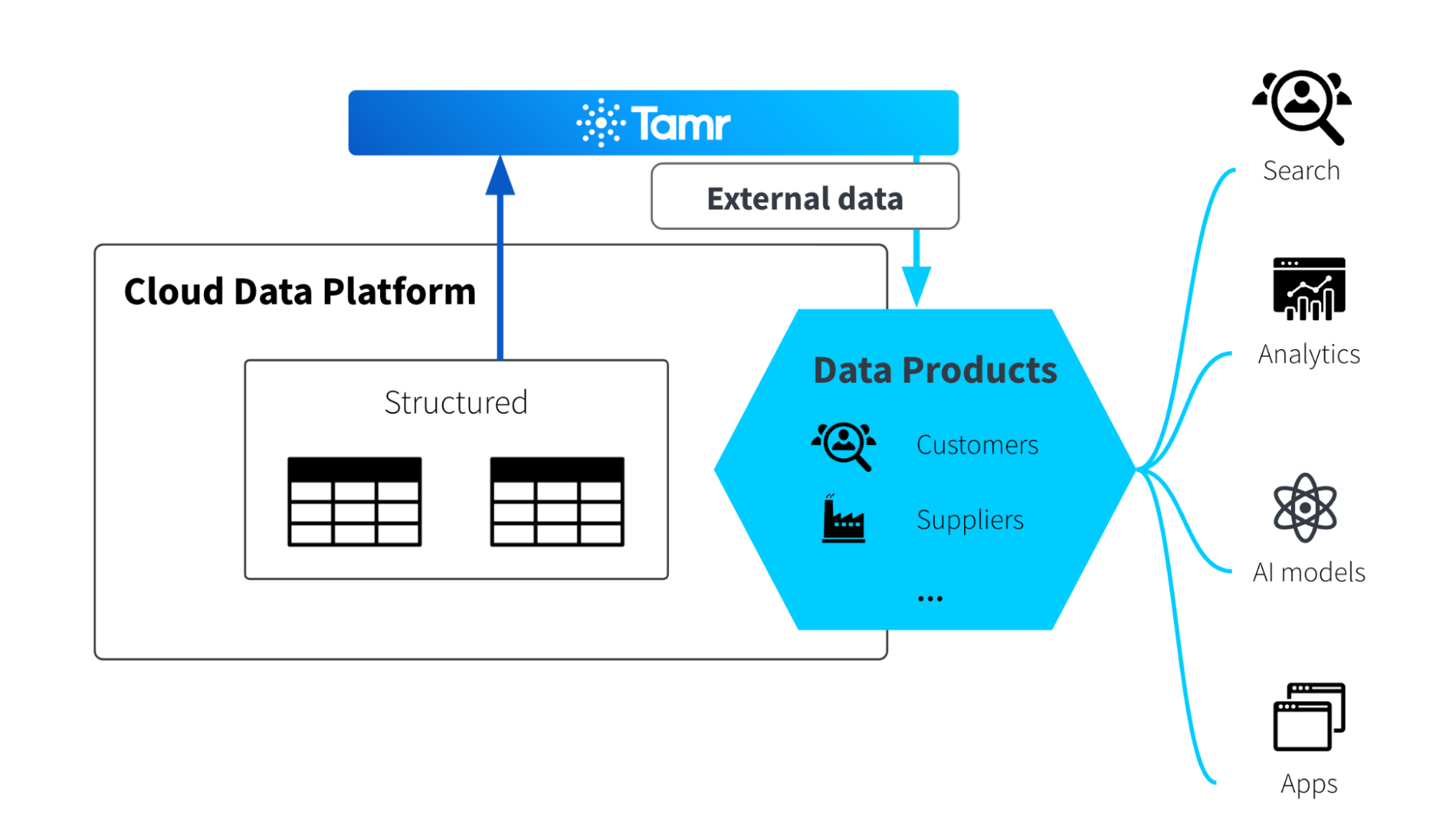
Enhancing data resolution with AI
While Tamr has been using ML to perform bottom-up data mastering (golden record creation) through consolidation of often conflicting and disparate schema formats and classification since 2013, we have enhanced our Data Products to leverage Google Vertex AI and state-of-the-art foundation models like Gemini to use the semantic information that is present in the source systems and to resolve those data items to real-world entities.
Google's Gemini is an advanced large language model that surpasses previous iterations in tasks such as coding, math, classification, translation, and natural language generation. Its success is attributed to improved scaling, dataset diversity, and the model’s architecture.
These capabilities make it even easier to get value from increasingly diverse and varied data sources. Using foundation models, Tamr’s Data Products leverage the semantic information that is present in the source systems to resolve data to real-world entities.
Additionally, with Gemini, it’s now possible to unlock the full potential of the source data without ETL or traditional ML model development. In short, Tamr’s Data Products can do more using Google’s generative AI while maintaining a simple, declarative experience for configuring and deploying Data Products to production:
Use cases
To show how Google’s generative AI capabilities are enhancing Tamr’s Data Products, let’s take the example of an e-commerce company that wants to better understand their sales trends.
This company wants to understand which kinds of products are most effective in different market segments, but their product catalog lacks reliable metadata to drive their analysis. Much of this information is encoded directly into product names. You can follow along with this example by downloading theLook eCommerce public dataset hosted in BigQuery.
Use case #1: Structured text extraction
While our e-commerce company could undertake an expensive manual labeling project to source the data required for their analysis, this approach is difficult to implement and maintain over time. Adding attributes to make strategic decisions implies significant marginal cost and effort. And as the product catalog evolves over time, the data must be kept up to date. The initial effort is never sufficient — maintaining high quality data is a continuous process.
Additionally, much of the information we need to start our project is already available in the product name data that exists in the catalog, for example:
These names contain important information that we can extract for analysis:
-
Brand and Product Line
-
Materials
-
Style and Fit
-
Pattern
-
Color
-
Unit Count
However the contents of the product names are represented inconsistently across different products and manufacturers. Similarly, the facets required for analysis can vary across end-users. A group focused on optimizing sales for a specific product vertical, e.g, Men’s Outerwear, may want much more detailed information on material and style than a group that is assessing how an entire geographical segment of customers is behaving in aggregate.
Tamr’s Data Products now leverage Gemini to automatically extract structured data from text fields, including product materials, dimensions, and other relevant properties. To access this information, the user of the Data Product just needs to identify which attribute contains the product description when aligning their schema to the data model used by a Data Product with AI Text Extraction enabled.
The Data Product is already configured with a declarative definition of the expected output schema and can be extended with few-shot examples to adapt the text extraction behavior to specific characteristics of the customer’s data.
Tamr’s use of Google generative AI allows our customers to leverage cutting-edge technology inside of their Data Products with no code or ML training required, resulting in a massive acceleration of time-to-value for business users who know their data, but struggle to coordinate effective ETL pipelines with their IT organization.
Finally, after executing the Data Product, the new attributes are available in the output for analysis and further curation downstream:
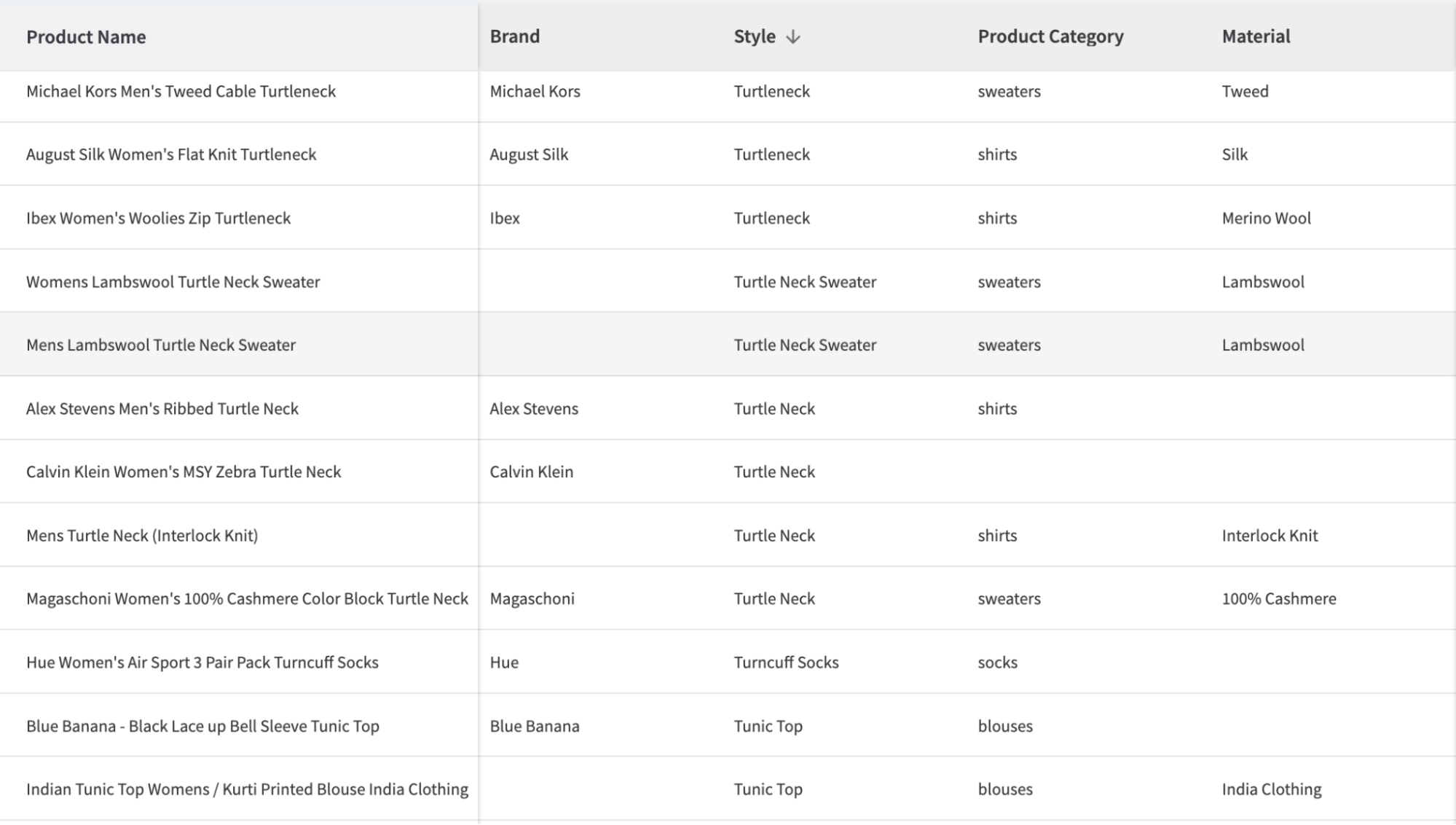
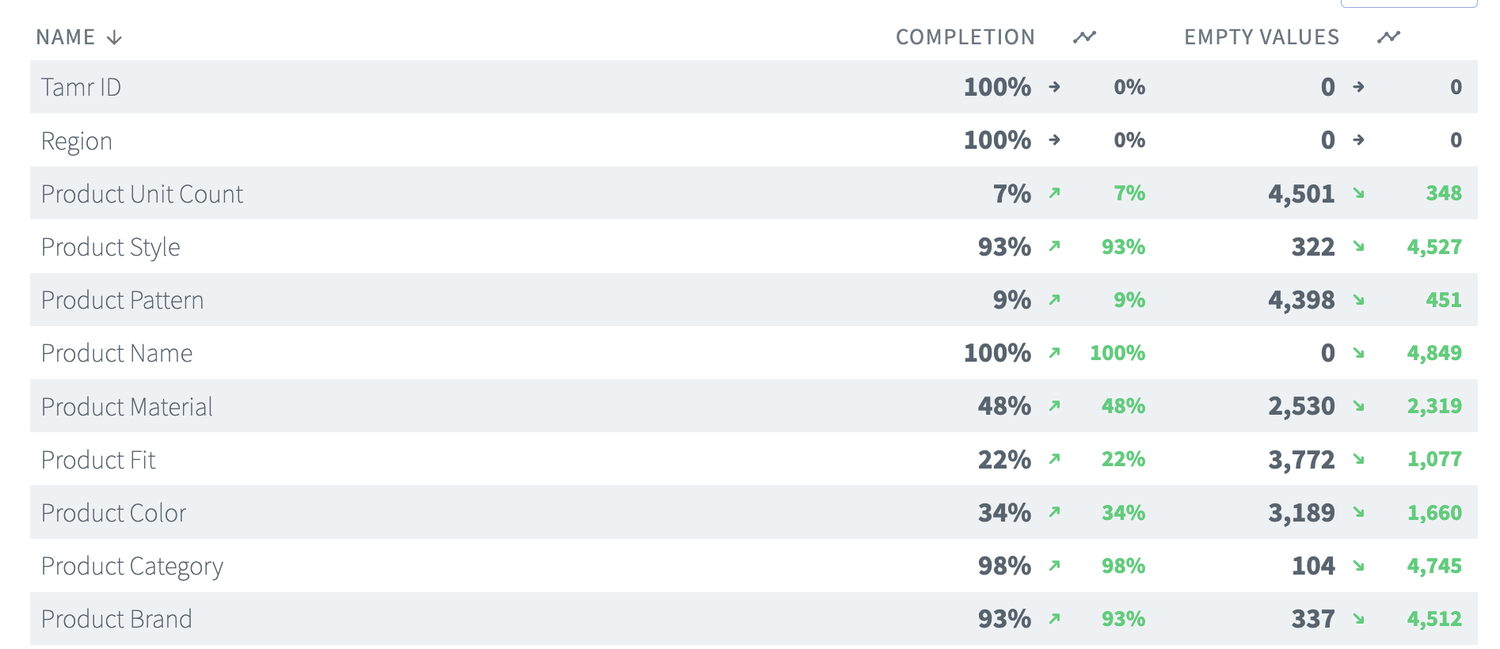
From just one input attribute, we now have significantly more structured data to work with:
Use case #2: Flexible classification
Sometimes the data required to make key decisions is not directly present at all in the source data, but can be inferred in the context of other attributes. Often this information is obvious to informed human users of the data, but difficult to backfill without broad organizational buy-in and a large data engineering project.
To return to our example above, the data in theLook eCommerce contains some information about product categories, but for our purposes we want to adjust the taxonomy to match the requirements of our analysis. Rather than manually relabeling all of the products to match our specific needs, Tamr’s Data Products allow users to simply declare what taxonomy they want to classify to and dynamically update labels by running the Data Product’s pipeline.
To enable this use-case, Tamr Data Products now leverage Gemini to perform classification tasks for a variety of domains. Foundation models are capable of effectively adapting to novel classification tasks with little or no additional training. Additionally, Gemini can solve tasks that require a high degree of reasoning ability.
Since we are using a pre-trained base model, once we have defined the taxonomy that we want to map products to, all we need to do is configure which field contains the product description information:
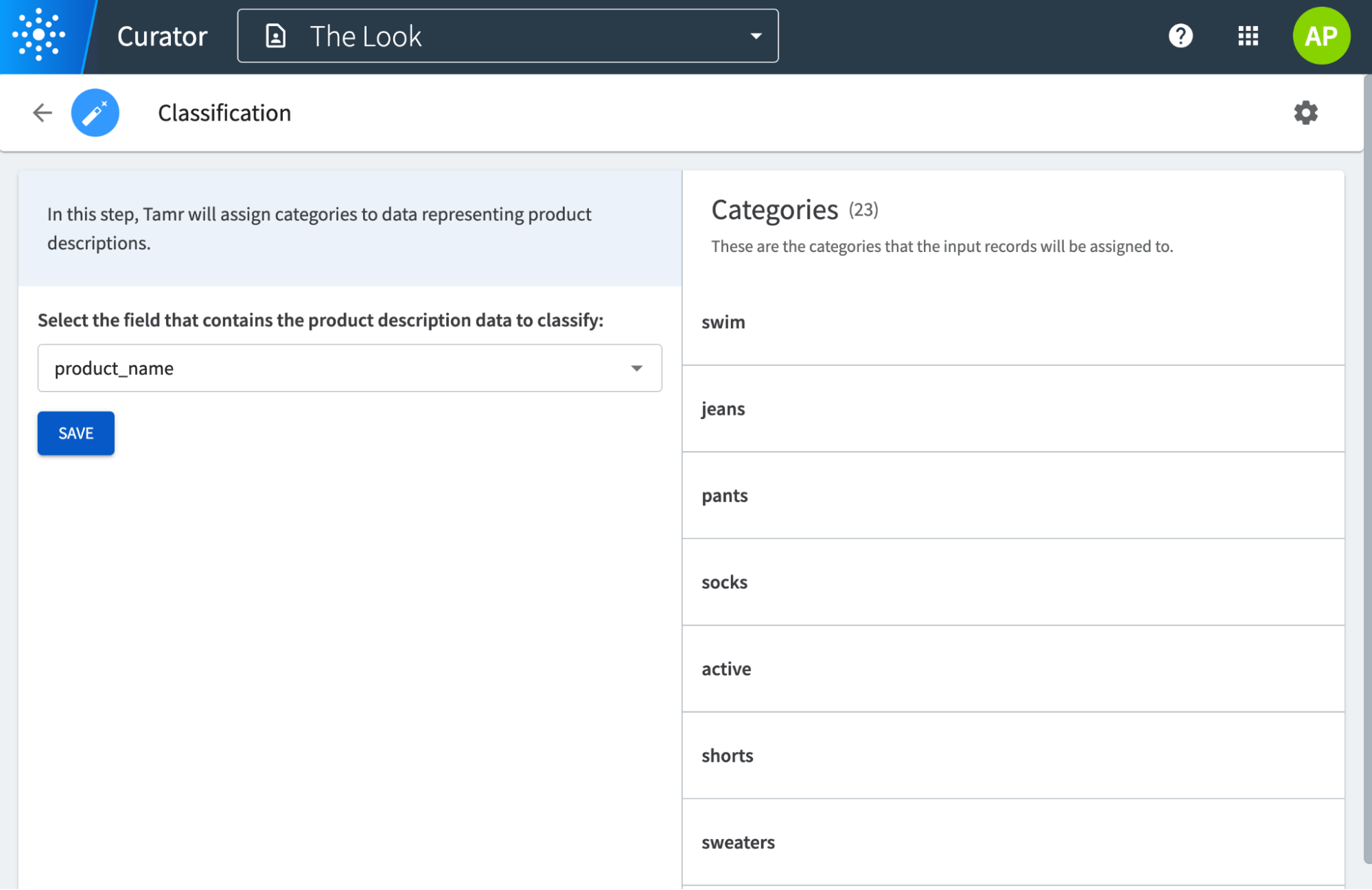
In addition to mapping data to a taxonomy for downstream analysis, Tamr’s Data Products can leverage Google’s foundation models to solve many other data problems:
-
Deciding whether a customer record represents a person or a business, which may have vastly different requirements downstream
-
Flagging records that contain invalid or filler values (e.g. ‘NONE’, ‘null’, ‘00000000’, etc.)
-
Flagging records for further review based on heuristics; e.g., all records representing a single person should have a consistent date of birth
Using Google generative AI in conjunction with traditional ML techniques allows Tamr to adapt to the long-tail of classification use-cases while maintaining a high degree of quality and a simple deployment model; the end user doesn’t need to be an expert in ML, feature engineering or the MLOps lifecycle, they can simply run a Data Product pipeline and consume high-quality output data downstream.
Likewise, as the capabilities of both Google’s generative AI models and Tamr’s Data Product Templates advance, we will be able to tackle complex and specific classification tasks in problem domains that would in the past require significant R&D investment to automate, like life sciences and high-tech manufacturing.
Solution
Tamr Cloud is a SaaS offering that is deployed on Google Cloud. As such, we already make extensive use of Google Cloud infrastructure for storing and processing data (in BigQuery, CloudSQL, Dataproc and BigTable) and for running our web services. Tamr’s integration with Google generative AI, we now use Vertex AI’s infrastructure to run model inference at scale.
Tamr’s Data Products perform structured text extraction and classification using the Gemini API, which is orchestrated by Tamr as part of a Data Product template’s pipeline. The Data Product abstracts away configuration details of how the foundation model is used, including how prompts should be constructed for a specific use case, and how the results of the model should be processed for downstream consumption. This allows users to focus on reviewing and using the results as part of an operational data pipeline.
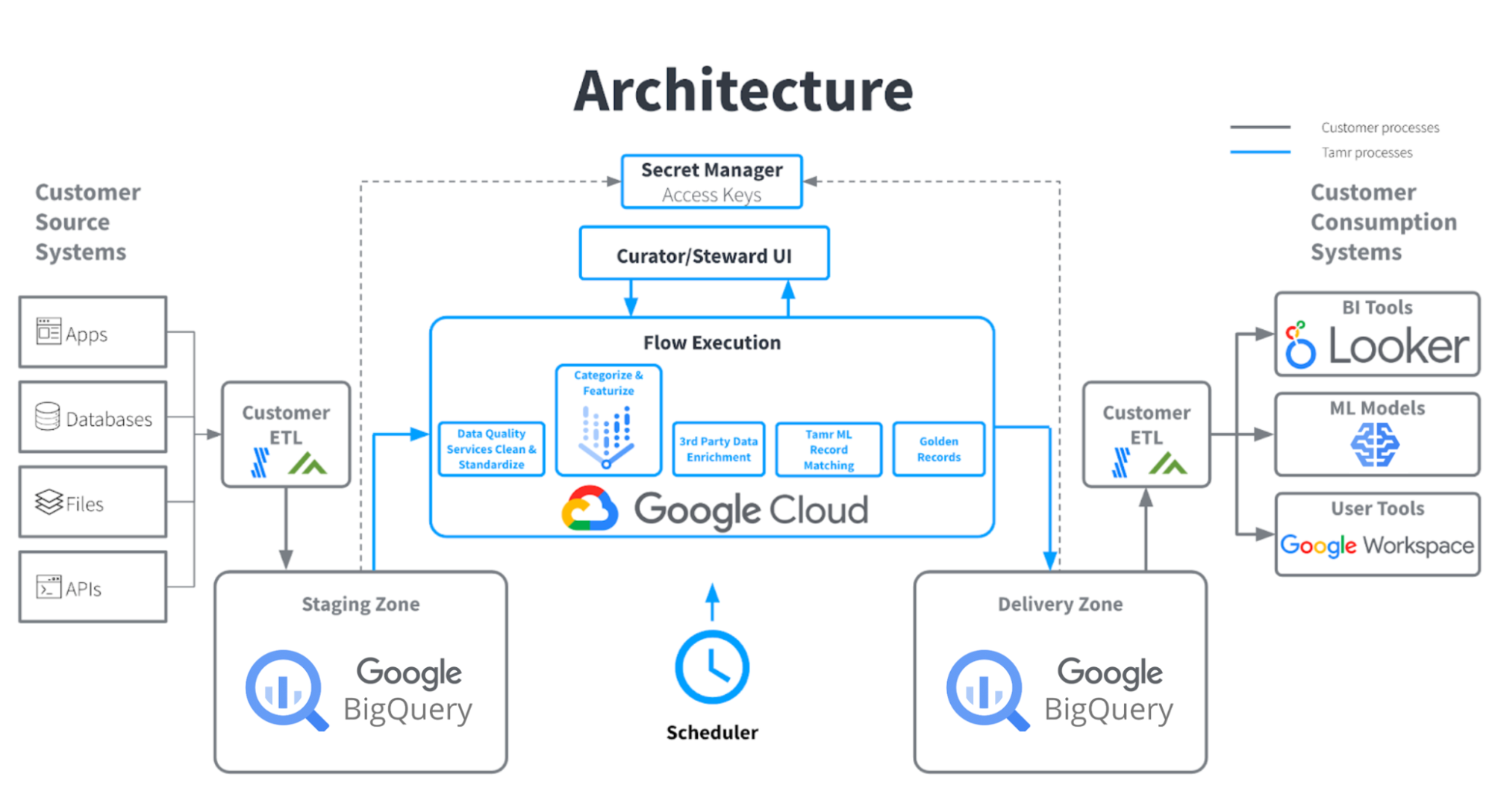
When the Data Product is run, Tamr’s Data Product Templates and enrichment framework handle:
-
Building appropriate prompts from the Data Product’s declarative configuration
-
Constructing and executing requests to model inference APIs using Vertex AI
-
Batching, caching, validating, and retry (when appropriate) of API requests
-
Post-processing of the API response to ensure that results respect invariants and conform to the expected schema
The resulting attributes produced by the text extraction and classification steps can then be used internally in the Data Product as features to cluster entities using Tamr’s ML record matching, or simply exported to downstream systems for consumption by end-users.
Considerations and tradeoffs
While the capabilities of AI models like those provided by Google gen AI are undoubtedly impressive, adopting any new technology requires careful consideration of how it will be used in practice.
For example, for some classification use-cases it may be computationally more efficient to run a traditional ML model like Gradient Boosted Trees for a particular task rather than a foundation model. However, training and modifying the model over time is a difficult operational task that requires significant ML sophistication. On the other hand, foundation models like Gemini are effective few-shot learners, and for many problems simply providing a small number of representative examples is sufficient to achieve good performance. In this case, the increased runtime of evaluating a data pipeline may be acceptable since the cost of modifying and adapting the pipeline to feedback is lower than with traditional methods.
Another important consideration is how much fine-grained control to provide to end-users. Because foundation models can use instructions written in natural language, one might assume that end users should always be able to directly augment prompts with their own modifications. However at this stage, devising prompts that perform well for a specific problem domain is a subtle and sometimes counterintuitive task.
Tamr’s Data Products enable users to leverage the power of generative AI without requiring them to become prompt engineers; instead, users state their intention declaratively with data-centric feedback, and then leverage prompts that have been carefully crafted by Tamr for a specific problem or data domain.
Like all ML-based solutions, foundation models still require review and feedback to verify their results. Tamr has always taken a human-guided approach to machine learning, and foundation models are no exception. In some cases, base models might not suffice for end users’ expectations. Fortunately, Google provides the ability to tune model behavior using reinforcement learning from human feedback (RLHF). This allows Tamr to improve the model's performance on specific tasks and data domains within the context of a Data Product.
Elevate data management with generative AI integration
The partnership between Google and Tamr represents a significant leap forward in data management and analytics. By combining Tamr's Data Products with Google's cutting-edge generative AI such as Gemini, businesses can overcome the challenges of resolving records from disparate data sources and transform their data easily.
Tamr's turnkey Data Products leverage ML-based mastering models, data cleaning, standardization services, and reference datasets, all while requiring minimal or no code configuration. This simplicity is further enhanced by the hosted SaaS environment, bringing ease of use for customers.
The integration of Google's generative AI brings unprecedented capabilities. It enables automatic structured data extraction from unstructured text fields and allows users to perform flexible classification tasks efficiently. With the semantic information harnessed from source systems, data can be accurately resolved to real-world entities without complex ETL pipelines or extensive ML model development.
Together, Google and Tamr provide better value by simplifying data management, accelerating time-to-value, and enhancing data-driven insights. Businesses can unlock the full potential of their data, streamline data processing, and make more informed decisions, all while maintaining data quality and integrity.
Google and Tamr's partnership brings data management and analytics to new heights, helping organizations succeed in an increasingly complex and competitive landscape that’s heavily reliant on data. Learn more about Google Cloud’s open and innovative generative AI partner ecosystem. To get started with Tamr, check out our Partner Advantage listing.

