How Distributed Shuffle improves scalability and performance in Cloud Dataflow pipelines
Sergei Sokolenko
Cloud Dataflow Product Manager
Many of our customers previously migrated from on-premises data processing environments, in which they had to operate large clusters of processing nodes and huge storage facilities for their data. Infrastructure management was a tax they incurred to pay for state-of-the-art data processing. Cloud Dataflow was among the first to pioneer serverless computing for batch and streaming big-data workloads. We asked ourselves: how can we further reduce operational overhead that gets in the way of focusing on the application logic? The resulting architecture that helped both batch and streaming Dataflow pipelines scale and perform better was based on separate compute and state storage layers. It also introduced a distributed shuffle layer between the two. With Dataflow Shuffle available for batch pipelines and Dataflow Streaming Engine available for streaming pipelines, we made this new, distributed shuffle architecture available for all of our customers.
Let's consider why shuffle is such a central component to get right in big-data processing. Imagine you have a set of key-value pairs. You want to group it by key, or join it by key with another dataset. When you have just one machine where your data fully resides, you just need to efficiently sort your data elements in memory or on disk by key, and then run your grouping or joins. But when you are doing distributed processing, and your data resides on multiple volumes attached to different processing nodes, that’s not so easy. One typically ends up co-locating all key-value pairs related to a specific key on a particular worker node, and then perform the grouping. To accomplish that, these key-value pairs need to be physically moved between processing nodes, in a process that is called a “shuffle.”
Because the shuffle process is very time-consuming and resource intensive, it makes sense to optimize this step. In fact, when we launched BigQuery after publishing the Dremel paper, we added a distributed, in-memory Shuffle service to the original distributed storage and separate compute cluster architectural components that were the basis of Dremel. We realized that to really make BigQuery work, we needed a fast way to do data shuffling.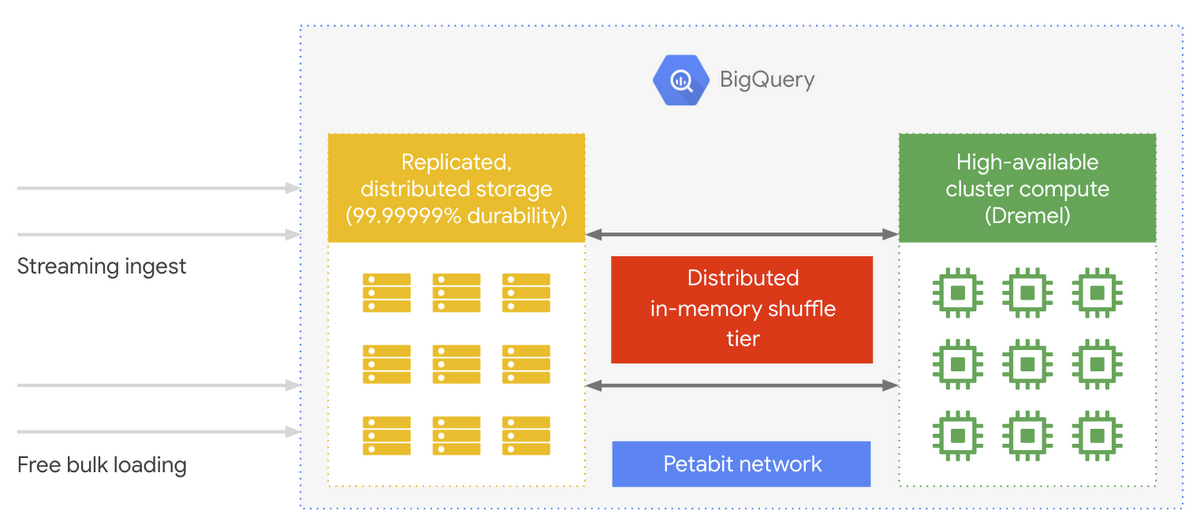
In Cloud Dataflow we have the same need to shuffle data elements as BigQuery does, because we provide users the ability to group and join data, and because we do distributed data processing on many workers.
Dataflow Shuffle for batch pipelines
As you will see in our webinar “Advancing Serverless Data Processing in Cloud Dataflow” on September 12th, 2018, we can achieve significant performance and scalability benefits when we move the shuffle operation from Persistent Disk and Worker nodes (part of current Cloud Dataflow service) to a specialized distributed, in-memory Shuffle service component. We call this component Dataflow Shuffle, and it works very similar to how BigQuery shuffle works.
In Batch pipelines, many of our users reported speed-ups in their pipelines, all without changing a single line of code. All they needed to do to use Dataflow Shuffle was specifying a pipeline parameter. The other great benefit of Dataflow Shuffle for batch pipelines is that you can shuffle significantly larger datasets. In the past, even when you used SSD Persistent Disks, you could shuffle perhaps 50TB simultaneously. For datasets larger than 50TB, the coordination between workers and moving key-value pairs around was just too much. With our new architecture for shuffling operations, we can scale to hundreds of terabytes, and the ceiling keeps rising with product improvements every month.
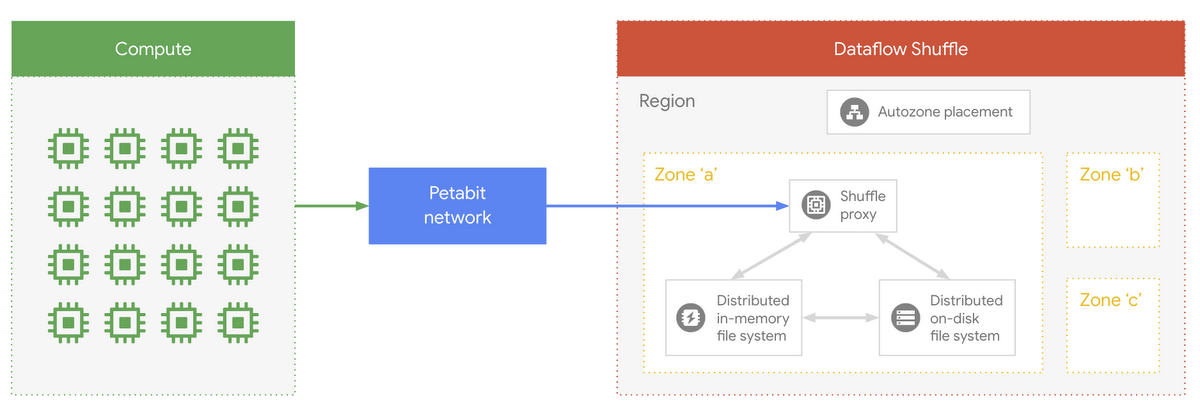
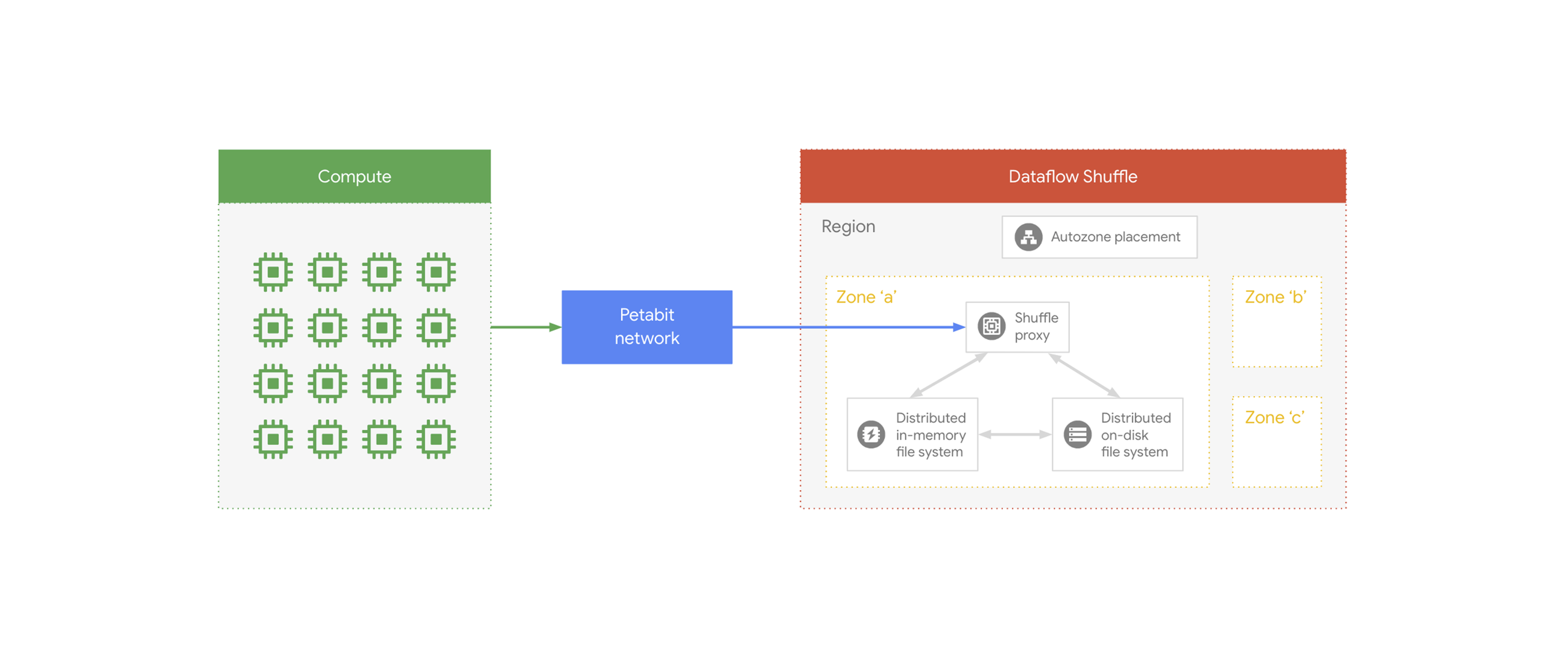
Dataflow Shuffle architecture
In our upcoming webinar we will touch upon the architecture of Dataflow Shuffle and explain how a combination of distributed in-memory and on-disk file systems are being used to provide the performance and scalability benefits to our customers.
Dataflow Streaming Engine for streaming pipelines
Just like in batch, streaming pipelines also need to be able to shuffle data, when users group data or join streams together. Furthermore, there is a special consideration for streaming pipelines, because while streaming, users often want to aggregate data elements based on some time dimension. Due to the fact that some data might arrive late, we need to be able to save the data elements associated with specific time intervals until we can trigger on various conditions and process these data elements.
Both because streaming pipelines need to do shuffling, and because we need to store data elements related to time windows, we have recently introduced a distributed component called the Streaming Engine. Just like the Dataflow Shuffle’s operation in batch pipelines, the Streaming Engine offloads the window state storage from the Persistent Disks attached to workers to a backend service. It also implements an efficient shuffle for streaming cases.
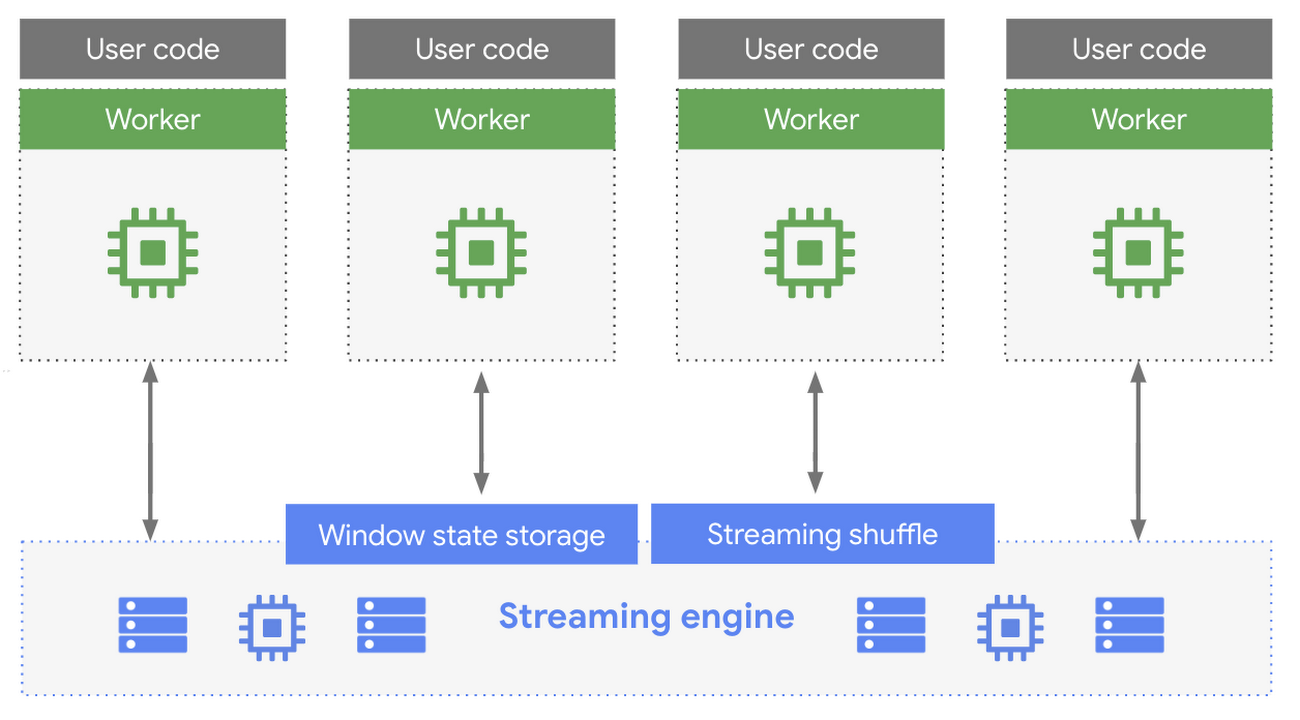
No code changes are required in pipelines. Worker nodes continue running user code and transparently communicate with the Streaming Engine to store state. The benefit of this approach is that our streaming autoscaling is smoother now, as you will see in our webinar. We are also able to maintain the infrastructure of streaming without impacting our customers, improving supportability of streaming pipelines. And, lastly, the part of Dataflow that used to be responsible for shuffle and state storage is not running on workers anymore, so user code has more resources now to process data.
Key takeaways
Separating state storage from compute and connecting the two via a distributed shuffle layer leads to better performance and scalability in data processing
Dataflow Shuffle makes batch pipelines run faster and support larger datasets. It is available today in GA in
us-central1andeurope-west1GCP regionsDataflow Streaming Engine improves autoscaling for Streaming pipelines. Streaming Engine is in beta in the same two regions.
In our webinar we will go in depth into the inner workings of Dataflow Shuffle and Streaming Engine.
Next steps
Register for our September 12th, 2018 webinar Advancing Serverless Data Processing in Cloud Dataflow here.
Learn more about Dataflow Shuffle scalability and Streaming Engine autoscaling
Review the benefits and other considerations of Dataflow Shuffle and Streaming Engine

