Fine tune autoscaling for your Dataflow Streaming pipelines
Sergei Lilichenko
Solutions Architect, Google Cloud
Yuriy Zhovtobryukh
Senior Product Manager, Google
Stream processing helps users get timely insights and act on data as it is generated. It is used for applications such as fraud detection, recommendation systems, IoT and others. However, scaling live streaming pipelines as input load changes is a complex task, especially if you need to provide low-latency guarantees and keep costs in check. That's why Dataflow has invested heavily in improving its autoscaling capabilities over the years, to help users by automatically adjusting compute capacity for the job. These capabilities include:
- Horizontal auto-scaling: This lets the Dataflow service automatically choose the appropriate number of worker instances required for your job.
- Streaming Engine: This provides smoother horizontal autoscaling in response to variations in incoming data volume.
- Vertical auto-scaling (in Dataflow Prime): This dynamically adjusts the compute capacity allocated to each worker based on utilization.
Sometimes customers want to customize the autoscaling algorithm parameters. In particular, we see three common use cases when customers want to update min/max number of workers for a running streaming job:
- Save cost when latency spikes: Latency spikes may cause excessive upscaling to handle the input load, which increases cost. In this case, customers may want to apply a smaller number of worker’ limits to reduce the costs.
- Keep latency low during expected increase in traffic: For example, a customer may have a stream that is known to have spikes in traffic every hour. It can take minutes for the autoscaler to respond to those spikes. Instead, the users can have the number of workers to be increased proactively ahead of the top of the hour.
- Keep latency low during traffic churns: It can be hard for the default autoscaling algorithm to select the optimal number of workers during bursty traffic. This can lead to higher latency. Customers may want to be able to apply a narrower range of min/max number of workers to make autoscaling less sensitive during these periods.
Introducing inflight streaming job updates for user-calibrated autoscaling
Dataflow already offers a way to update auto-scaling parameters for long-running streaming jobs by doing a job update. However, this update operation causes a pause in the data processing, which can last minutes and doesn’t work well for pipelines with strict latency guarantees.
This is why we are happy to announce the in-flight job option update feature. This feature allows Streaming Engine users to adjust min/max number of workers at runtime. If the current number of workers is within the new minimum and maximum boundaries then this update will not cause any processing delays. Otherwise the pipeline will start scaling up or down within a short period of time.
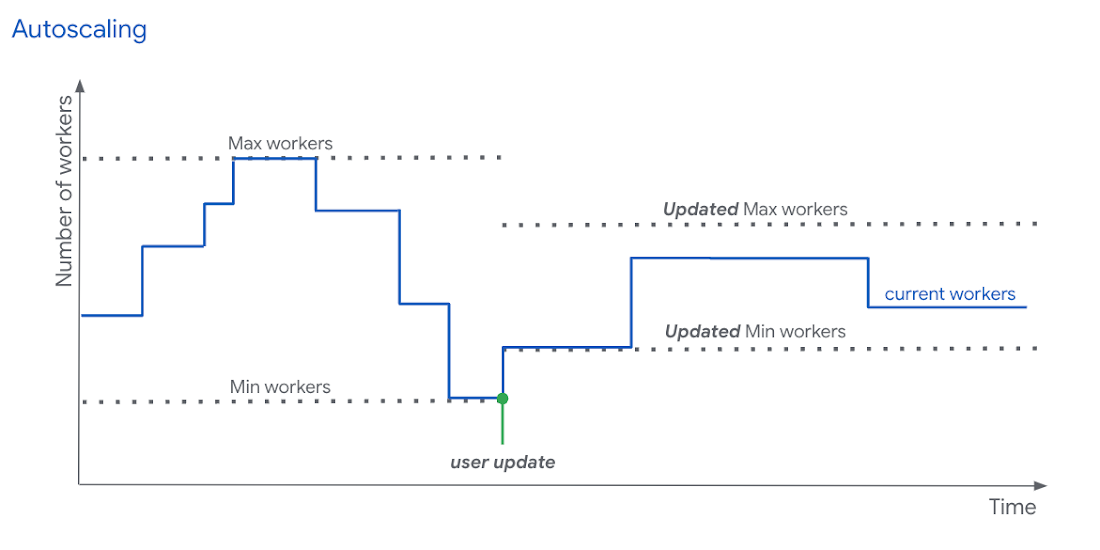
It is available for users through:
- Google Cloud console command:
- Dataflow Update API
Please note that the in-flight job updates feature is only available to pipelines using Streaming Engine.
Once the update applied, users can see the effects in the Autoscaling monitoring UI:
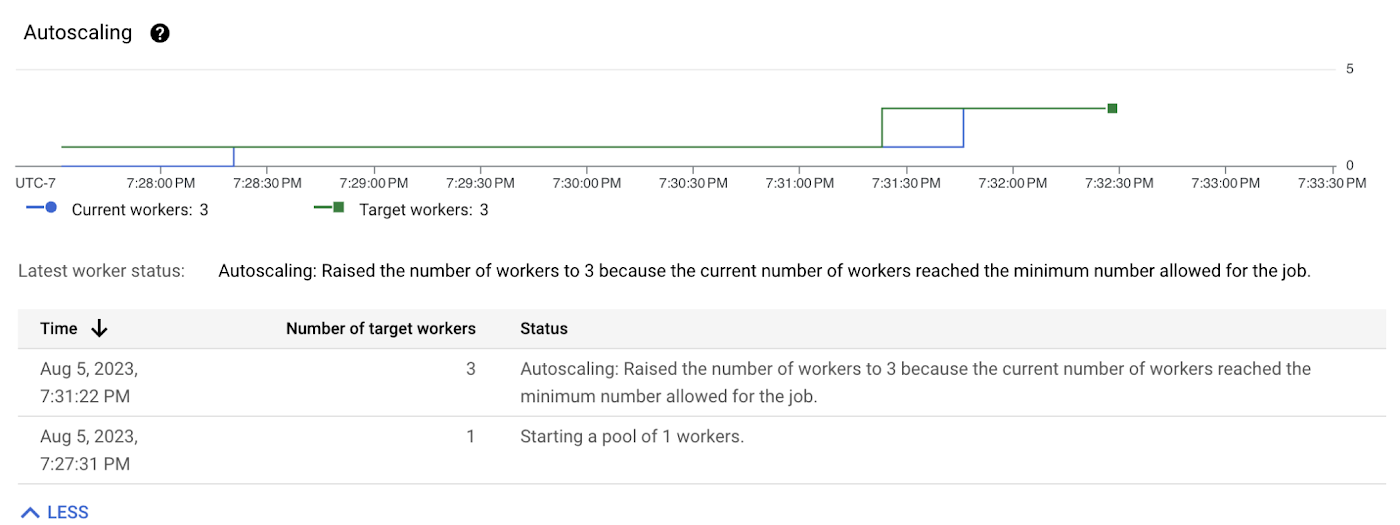
The “Pipeline options” section in the “Job info” panel will display the new values of “minNumberOfWorkers” and “maxNumberOfWorkers”.
Case Study: How Yahoo used this feature
Yahoo needs to frequently update their streaming pipelines that process Google Pub/Sub messages. This customer also has a very tight end-to-end processing SLA so they can't afford to wait for the pipeline to be drained and replaced. If they were to follow the typical process, they would start missing their SLA.
With the new in-flight update option, we proposed an alternative approach. Before the current pipeline drain is initiated, its maximum number of workers is set to the current number of workers using the new API. Then a replacement pipeline is launched with the maximum number of workers also equal to the current number of workers of the existing pipeline. This new pipeline is launched on the same Pub/Sub subscription as the existing one (note: in general using the same subscriptions for multiple pipelines is not recommended as it allows duplicates to occur as there is no deduplication across separate pipelines. It works only when duplicates during update are acceptable). Once the new pipeline starts processing the messages, the existing pipeline is drained. Finally, the new production pipeline is updated with the desired minimum and maximum number of workers.
Typically, we don't recommend running more than one Dataflow pipeline on the same Pub/Sub subscription. It's hard to predict how many Pub/Sub messages will be in the pipeline, so the pipelines might scale up too much. The new API lets you disable autoscaling during replacement, which has been shown to work well for this customer and helped them maintain the latency SLA.
"With Yahoo mail moving to the Google Cloud Platform we are taking full advantage of the scale and power of Google's data and analytics services. Streaming data analytics real time across hundreds of millions of mailboxes is key for Yahoo and we are using the simplicity and performance of Google's Dataflow to make that a reality." - Aaron Lake, SVP & CIO, Yahoo
You can see the source code of sample scripts to orchestrate a no-latency pipeline replacement and a simple test pipeline in this GitHub repository.
What’s next
Autoscaling live streaming pipelines is important to achieve low-latency guarantees and meet the cost requirements. Doing it right can be challenging. That's where the Dataflow Streaming Engine comes in.
Many auto scaling features are now available to all Streaming Engine users. With the in-flight job updates, our users get an additional tool to fine tune the auto-scaling for their requirements.
Stay tuned for future updates and learn more by contacting the Google Cloud Sales team.

