Performance considerations for loading data into BigQuery
Jit Biswas
Principal Architect - Data & Analytics, Google
Layolin Jesudhass
Customer Engineer - Data & Analytics, Google
Customers have been using BigQuery for their data warehousing needs since it was introduced. Many of these customers routinely load very large data sets into their Enterprise Data Warehouse. Whether one is doing an initial data ingestion with hundreds of TB of data or incrementally loading from systems of record, performance of bulk inserts is key to quicker insights from the data. The most common architecture for batch data loads uses Google Cloud Storage(Object storage) as the staging area for all bulk loads. All the different file formats are converted into an optimized Columnar format called ‘Capacitor’ inside BigQuery.
This blog will focus on various file types for best performance. Data files that are uploaded to BigQuery, typically come in Comma Separated Values(CSV), AVRO, PARQUET, JSON, ORC formats. We are going to use two large datasets to compare and contrast each of these file formats. We will explore loading efficiencies of compressed vs. uncompressed data for each of these file formats. Data can be loaded into BigQuery using multiple tools in the GCP ecosystem. You can use the Google Cloud console, bq load command, using the BigQuery API or using the client libraries. This blog attempts to elucidate the various options for bulk data loading into BigQuery and also provides data on the performance for each file-type and loading mechanism.
Introduction
There are various factors you need to consider when loading data into BigQuery.
Data file format
Data compression
Level of parallelization of data load
Schema autodetect ‘ON’ or ‘OFF’
Wide tables vs narrow(fewer columns) tables.
Data file format
Bulk insert into BigQuery is the fastest way to insert data for speed and cost efficiency. Streaming inserts are however more efficient when you need to report on the data immediately. Today data files come in many different file types including Comma Separated(CSV), JSON, PARQUET, AVRO to name a few. We are often asked how the file format matters and whether there are any advantages in choosing one file format over the other.
CSV files (comma-separated values) contain tabular data with a header row naming the columns. When loading data one can parse the header for column names. When loading from csv files one can use the header row for schema autodetect to pick up the columns. With schema autodetect set to off, one can skip the header row and create a schema manually, using the column names in the header. CSV files can use other field separators(like ; or |) too as a separator, since many data outputs already have a comma in the data. You cannot store nested or repeated data in CSV file format.
JSON (JavaScript object notation) data is stored as a key-value pair in a semi structured format. JSON is preferred as a file type because it can store data in a hierarchical format. The schemaless nature of JSON data rows gives the flexibility to evolve the schema and thus change the payload. JSON formats are user-readable. REST-based web services use json over other file types.
PARQUET is a column-oriented data file format designed for efficient storage and retrieval of data. PARQUET compression and encoding is very efficient and provides improved performance to handle complex data in bulk.
AVRO: The data is stored in a binary format and the schema is stored in JSON format. This helps in minimizing the file size and maximizes efficiency.
From a data loading perspective we did various tests with millions to hundreds of billions of rows with narrow to wide column data .We have done this test with a public dataset named `bigquery-public-data.samples.github_timeline` and `bigquery-public-data.wikipedia.pageviews_2022`. We used 1000 flex slots for the test and the number of loading(called PIPELINE slots) slots is limited to the number of slots you have allocated for your environment. Schema Autodetection was set to ‘NO’. For the parallelization of the data files, each file should typically be less than 256MB uncompressed for faster throughput and here is a summary of our findings:
Do I compress the data?
Sometimes batch files are compressed for faster network transfers to the cloud. Especially for large data files that are being transferred, it is faster to compress the data before sending over the cloud Interconnect or VPN connection. In such cases is it better to uncompress the data before loading into BigQuery? Here are the tests we did for various file types with different file sizes with different compression algorithms. Shown results are the average of five runs:
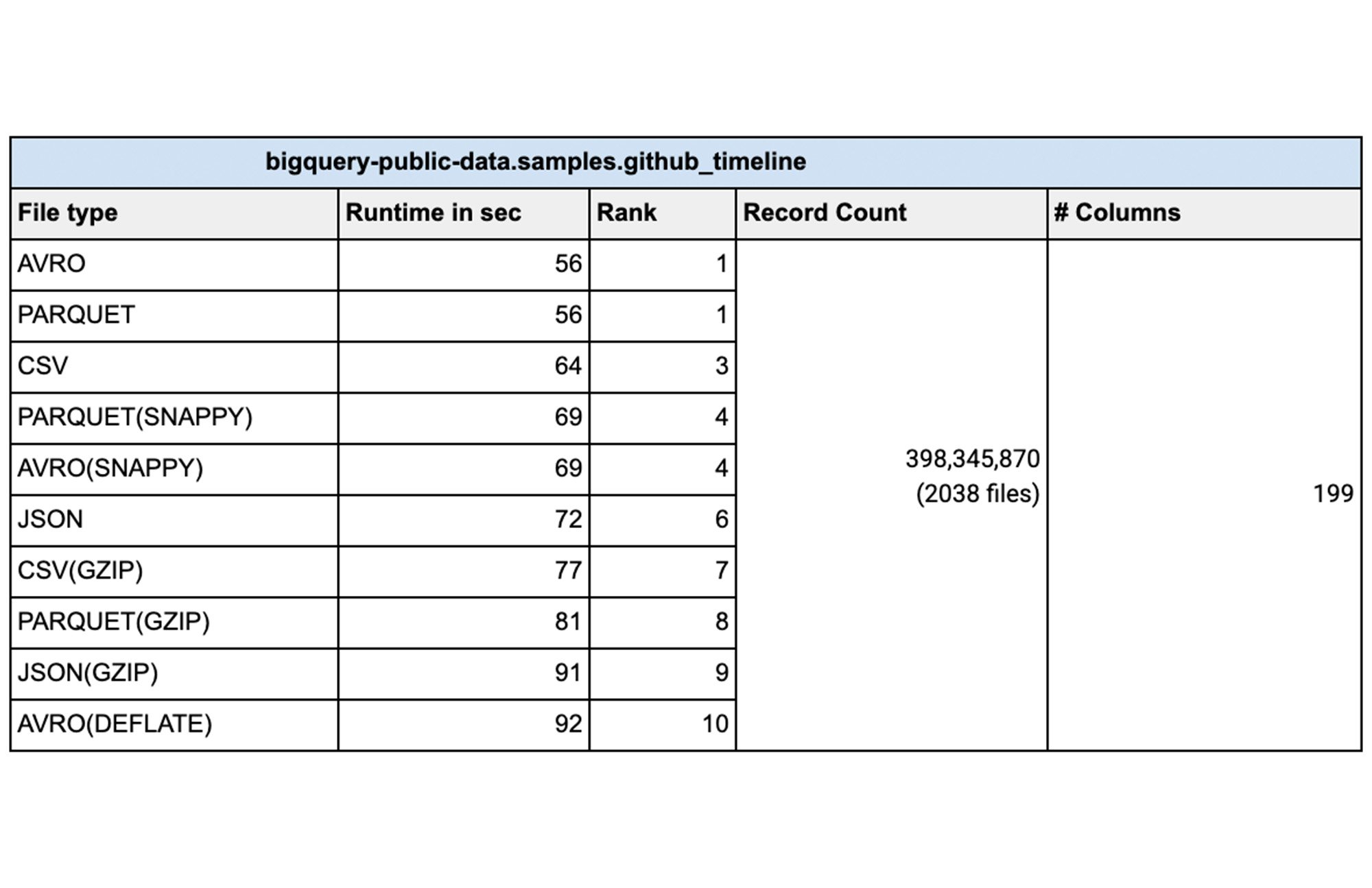
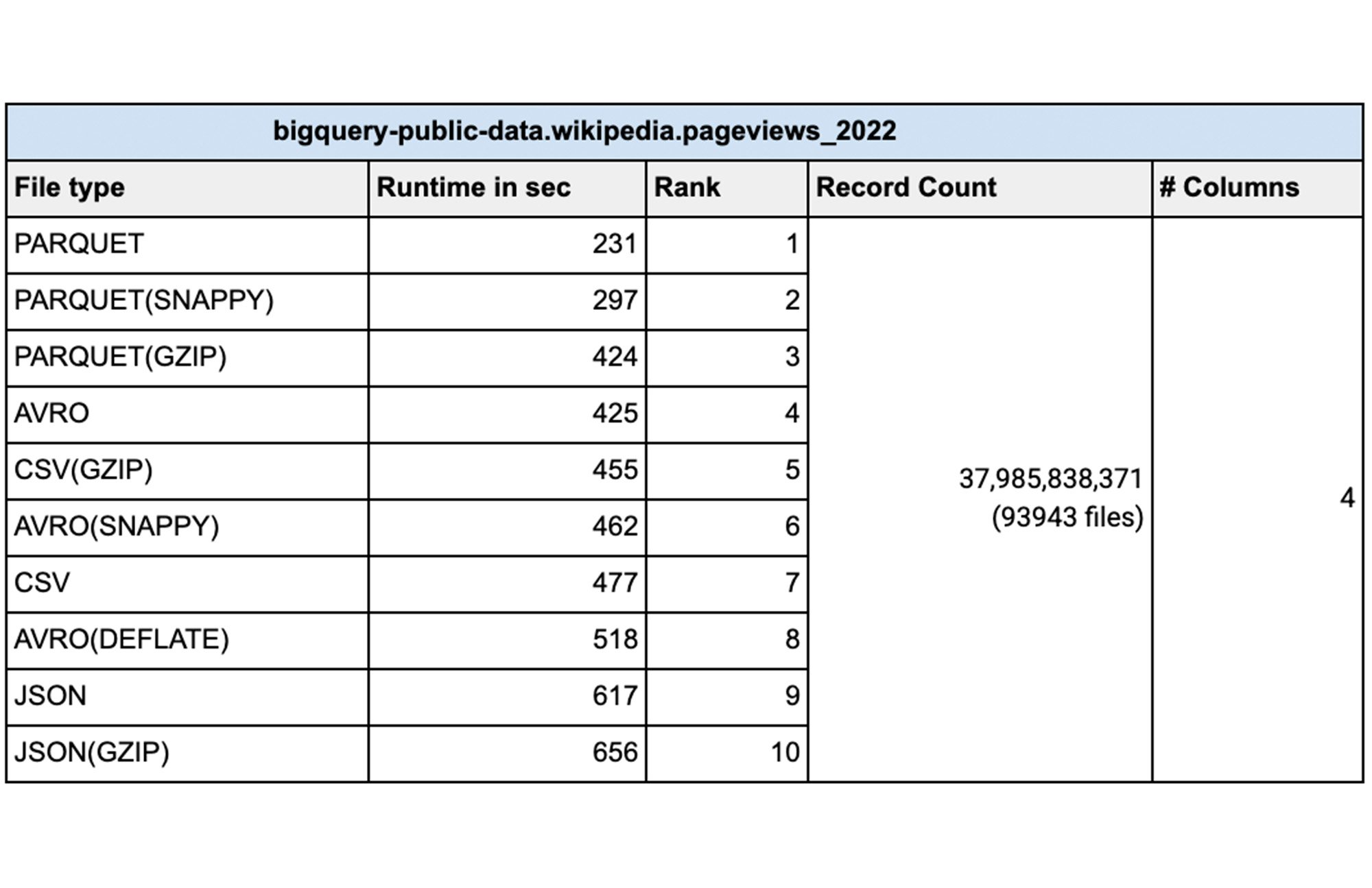
How do I load the data?
There are various ways to load the data into BigQuery. You can use the Google Cloud Console, command line, Client Library or use the REST API. As all these load types invoke the same API under the hood so there is no advantage of picking one way over the other. We used 1000 PIPELINE slots reservations, for doing the data loads shown above. For workloads that require predictable load times, it is imperative that one uses PIPELINE slot reservations, so that load jobs are not dependent on the vagaries of available slots in the default pool. In the real world many of our customers have multiple load jobs happening concurrently. In those cases, assigning PIPELINE slots to individual jobs has to be done carefully keeping a balance between load times and slot efficiency.
Conclusion: There is no distinct advantage in loading time when the source file is in compressed format for the tests that we did. In fact for the most part uncompressed data loads in the same or faster time than compressed data. For all file types including AVRO, PARQUET and JSON it takes longer to load the data when the file is compressed. Decompression is a CPU bound activity and your mileage varies based on the amount of PIPELINE slots assigned to your load job. Data loading slots(PIPELINE slots) are different from the data querying slots. For compressed files, you should parallelize the load operation, so as to make sure that data loads are efficient. Split the data files to 256MB or less to speed up the parallelization of the data load.
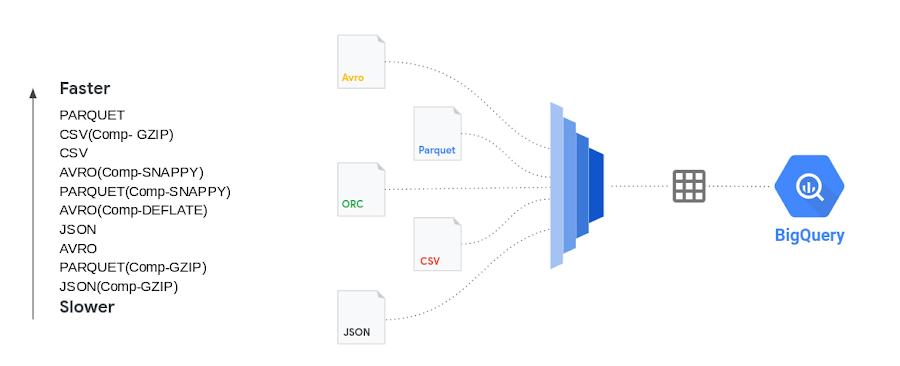
From a performance perspective AVRO and PARQUET files have similar load times. Fixing your schema does load the data faster than schema autodetect set to ‘ON’. Regarding ETL jobs, it is faster and simpler to do your transformation inside BigQuery using SQL, but if you have complex transformation needs that cannot be done with SQL, use Dataflow for unified batch and streaming, Dataproc for streaming based pipelines, or Cloud Data Fusion for no-code / low-code transformation needs. Wherever possible, avoid implicit/explicit data types conversions for faster load times. Please also refer to Bigquery documentation for details on data loading to BigQuery.
To learn more about how Google BigQuery can help your enterprise, try out Quickstarts page here
Disclaimer: These tests were done with limited resources for BigQuery in a test environment during different times of the day with noisy neighbors, so the actual timings and the number of rows might not be reflective of your test results. The numbers provided here are for comparison sake only, so that you can choose the right file types, compression for your workload. This testing was done with two tables, one with 199 columns (wide table) and another with 4 columns (narrow table). Your results will vary based on the datatypes, number of columns, amount of data, assignment of PIPELINE slots and various file types. We recommend that you test with your own data before coming to any conclusion.


