Data engineering lessons from Google AdSense: using streaming joins in a recommendation system
Reza Rokni
Dataflow Product Manager
Rikard Lundmark
Software Engineer AdSense
Google AdSense helps countless businesses make money from their content by placing advertisements—and their recommendation system plays a huge role in this work. From the beginning, the team operated a batch-based data processing pipeline for the recommendation system, but like many Google Cloud customers we work with, they saw a lot of opportunity in migrating to a stream processing model which could enable AdSense publishers to receive real-time recommendations for their setup. As a result, in 2014, the AdSense publisher optimization team began exploring how to change their underlying data processing system.
In this post, we will walk through the technical details of how the AdSense publisher optimization data engineering team made the switch, and what they learned. Although the AdSense team used FlumeJava, an internal Google tool, their lessons learned are directly applicable to Google Cloud customers since FlumeJava is the same technology Google Cloud customers know as Cloud Dataflow. Today, these technologies share the majority of their code base, and further unification of FlumeJava and Cloud Dataflow is part of ongoing engineering efforts.
The original pipeline
Prior to making the change in 2014, the team’s original pipeline would extract data from several repositories, carry out any data transformations required, and then join the various data points using a common key. These new denormalized rows of data would then be used to generate AdSense’s recommendations. Once the batch run had completed, the recommendations could be communicated to the publishers. As you might expect, the pipeline needed to process a large amount of data on every run, so running the pipeline frequently was not a practical option. That meant it wasn’t suited for publishing recommendations in real time.
Moving to a streaming pipeline
The streaming pipeline that was developed went through several evolutions. In the first iteration, not every source of data was converted to be an unbounded (streaming) source, creating a pipeline that mixed bounded lookup data which was infrequently updated with the unbounded stream of data.
Blending real time and historic data sources in a combination of batch and stream is an excellent first step in migrating your environment towards real-time, and in some cases will effectively address the incremental capabilities the use case called for. It is important to make use of technologies that can blend both batch and stream processing, enabling users to move different aspects of their workloads between stream and batch until they find the right blend of speed, comfort, and price.
Initial version, unbounded data sources
In order to convert the primary sources of data from batch reads to streamed updates, the pipeline consumed the updates by connecting to a stream of change data capture (CDC) information coming from the data sources.
Initial version, with bounded lookup data sources
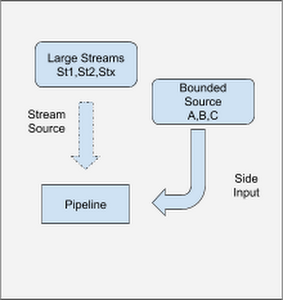
The AdSense team found that some of the lookup data points were both small and infrequently updated. This allowed them to make use of a side input pattern to ensure the data was available wherever it was needed. (SideInputs are a feature that is available in Apache Beam SDK, which you can read more about in the Beam documentation.)
One interesting challenge of this architecture was that the pipeline didn’t make use of any temporal windowing functions, meaning the streams and the SideInput were are all running in a global window. This global window starts when the pipeline begins and doesn’t end until the pipeline is canceled. This raised the question, “How do you update its value?” To solve this problem, the team implemented a solution, a "Slowly-changing lookup cache" pattern, which is available today through Cloud Dataflow and Apache Beam. The side input created can be used as a lookup table for the elements flowing through the pipeline.
Today’s pipeline, with an un-windowed joins pattern
Today, the recommendation pipeline no longer makes use of side inputs and treats all sources as streams to be joined in the same way. After all, the data sources are all just streams, even ones which change infrequently! As you can see in the diagram below, things are a lot simpler even though we have moved all sources to streaming!
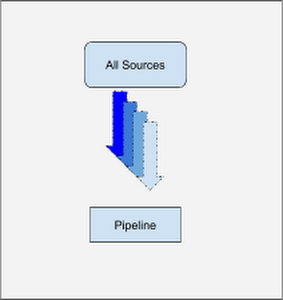
In the last section, we touched on the team’s requirement that the pipeline be able to do joins on data which isn’t bound by temporal windows.
More specifically, if we have a key 1 and we have two data tuples <Data1,null> and <null, Data2>, we would want to store <Data1,null> until <null, Data2> arrives, and then emit <Data1,Data2>. In order to solve this problem, the team made use of per key state within a global window. The pattern essentially materlizes a projection of the data sources onto the pipeline. Specifically, the pipeline lifecycle is outlined in the diagram below:
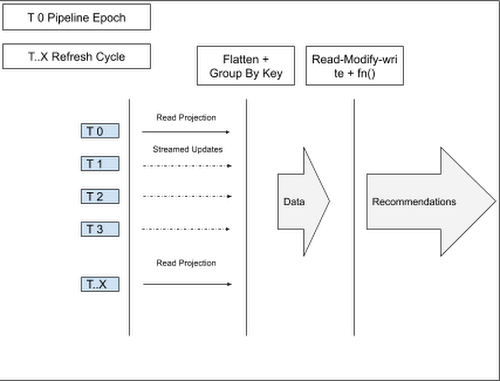
- T 0 : On Pipeline Epoch, all data sources are read.
- T 1 .. T 3 : The sources send updates as a stream.
- T..X : To guard against the pipeline becoming out of sync with the source systems, there is a refresh cycle: All data is re-read from all sources periodically (once daily, for example) ; This is an easy-to-implement reconciliation process, allowing any eventual consistency issues which may have arisen to be flushed out.
As data arrives, there is a read-modify-write call made to the state API. During this step, the timestamps of the data points are checked against the existing data points with only the latest data point being kept. It is important to note that order is not guaranteed for data arriving into the key state space. The latest values are then emitted forward.
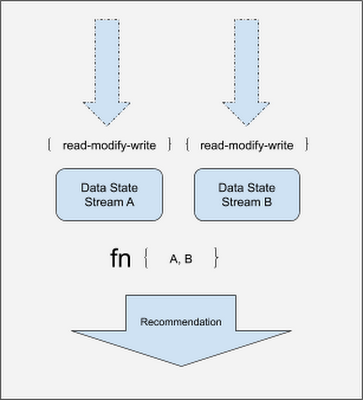
Garbage collection
This pattern is capable of storing large volumes of data in a streaming pipeline. While there are many keys, each key will hold only a relatively small amount of data. However, it would be wasteful to keep all keys forever, particularly when the key may no longer receive any updates. For every key, an alarm is set that will carry out garbage collection if no updates have been seen for a predetermined time. In order to achieve this in Apache Beam, you can make use of a Timer object, setting a value for it in EventTime domain.
Conclusion
AdSense delivers recommendations to publishers in near real time using this pattern, helping AdSense users get more value from the service. The team is able to concentrate on adding business value in their core domain, with the internal FlumeJava team managing and maintaining the technology that the pipeline runs on.
If you have a similar use case and wish to implement this pattern, you can do so via Google Cloud Dataflow using the Apache Beam SDK and the State and Timer APIs. Follow these links to find out more about Google Cloud Dataflow and Apache Beam.
Acknowledgments: Tyler Akidau, Technical Lead FlumeJava, Google Cloud Dataflow, also contributed to this post.



