Data analytics, meet containers: Kubernetes Operator for Apache Spark now in beta
Yinan Li
Software Engineer
Palak Bhatia
Product Manager
Many organizations run Apache Spark, a widely-used data analytics engine for large-scale data processing, and are also eager to use Kubernetes and associated tools like kubectl. Today, we’re announcing the beta launch of the Kubernetes Operator for Apache Spark (referred to as Spark Operator, for short, from here on), which helps you easily manage your Spark applications natively from Kubernetes. It is available today in the GCP Marketplace for Kubernetes.
Traditionally, large-scale data processing workloads—Spark jobs included—run on dedicated software stacks such as Yarn or Mesos. With the rising popularity of microservices and containers, organizations have demonstrated a need for first-class support for data processing and machine learning workloads in Kubernetes. One of the most important community efforts in this area is native Kubernetes integration, available in Spark since version 2.3.0. The diagram below illustrates how this integration works on a Kubernetes cluster.
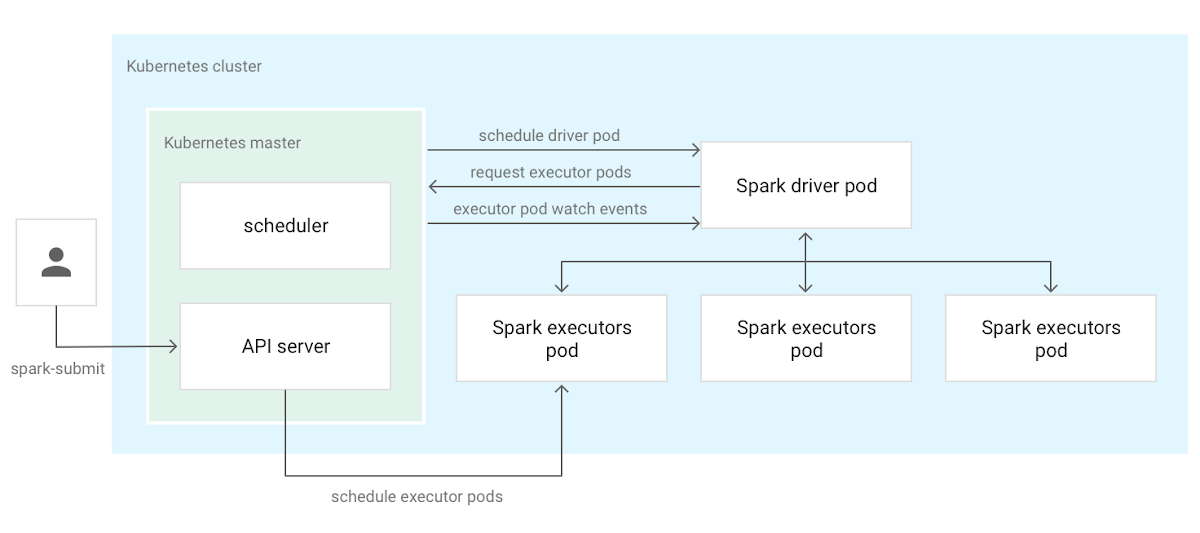
The Kubernetes Operator for Apache Spark runs, monitors and manages the lifecycle of Spark applications leveraging its native Kubernetes integration. Specifically, this operator is a Kubernetes custom controller that uses custom resources for declarative specification of Spark applications. The controller offers fine-grained lifecycle management of Spark applications, including support for automatic restart using a configurable restart policy, and for running cron-based, scheduled applications. It provides improved elasticity and integration with Kubernetes services such as logging and monitoring. With the Spark Operator, you can create a declarative specification that describes your Spark applications and use native Kubernetes tooling such as kubectl to manage your applications. As a result, you now have a common control plane for managing different kinds of workloads on Kubernetes, simplifying management and improving your cluster’s resource utilization.
With this launch, the Spark Operator for Apache Spark is ready for use for large scale data transformation, analytics, and machine learning on Google Cloud Platform (GCP). It supports the new and improved Apache Spark 2.4, letting you run PySpark and SparkR applications on Kubernetes. It also includes many enhancements and fixes that improves its reliability and observability, and can be easily installed with Helm.
Support for Spark 2.4
Spark 2.4, released in October last year, features improved Kubernetes integration. First, it now supports Python and R Spark applications with Docker images tailored to the language bindings. Second, it provides support for client mode, allowing interactive applications such as the Spark Shell and data science tools like Jupyter and Apache Zeppelin notebooks to run computations natively on Kubernetes. Then, there’s support for certain types of Kubernetes data volumes. Combined with other enhancements and fixes that make native Kubernetes integration more reliable and usable, our Spark Operator is a cloud-native solution that makes it easy to run and manage Spark applications on Kubernetes.
Integration with GCP
The Operator integrates with various GCP products and services, including Stackdriver for logging and monitoring, and Cloud Storage and BigQuery—for storage and analytics. Specifically, the operator exposes application-level metrics in the Prometheus data format and automatically configures Spark applications to expose driver- and executor-level metrics to Prometheus. With a Prometheus server with the Stackdriver sidecar, your cluster can automatically collect metrics and send them to Stackdriver Monitoring. Application driver and executor logs are automatically collected and pushed to Stackdriver when the application runs on Google Kubernetes Engine (GKE).
The Spark Operator also includes a command-line tool named sparkctl that automatically detects an application’s dependencies on the user’s client machine and uploads them to a Cloud Storage bucket. It then substitutes the client-local dependencies with the ones stored in the Cloud Storage portion of the application specification, greatly simplifying the use of client-local application dependencies in a Kubernetes environment.
The Spark Operator for Apache Spark ships with a custom Spark 2.4 Dockerfile that supports using Cloud Storage for input or output data in an application. This Dockerfile also includes the Prometheus JMX exporter, which exposes Spark metrics in the Prometheus data format. The Prometheus JMX exporter is Spark Operator’s default approach for using and configuring an application when Prometheus monitoring is enabled.
The GCP Marketplace: a one stop shop
GCP Marketplace for Kubernetes is a one-stop shop for major Kubernetes applications. The Spark Operator is available for quick installation on the Marketplace, including logging, monitoring, and integration with other GCP services out of the gate.
An active community
The Spark Operator for Apache Spark has an active community of contributors and users. The Spark Operator is currently deployed and used by several organizations for machine learning and analytics use cases, and has a dedicated Slack channel with over 170 members that engage in active daily discussions. Its GitHub repository has commits from over 20 contributors from a variety of organizations and has close to 300 stars—here’s a shout-out to all those who have made the project what it is today!
Looking forward
With a growing community around the project, we are constantly working on ideas and plans to improve it. Going into 2019, we’re working on the following features with the community:
- Running and managing applications of different Spark versions with the native Kubernetes integration. Currently, an Operator version only supports a specific Spark version. For example, an Operator version that is compatible with Spark 2.4 cannot be used to run Spark 2.3.x applications.
- Priority queues and basic priority-based scheduling. This will make the Operator better suited for running production batch processing workloads, e.g., ETL pipelines.
- Kerberos authentication, starting with Spark 3.0.
- Using a Kubernetes Pod template to configure the Spark driver and/or executor Pods.
- Enhancements to the Operator’s
sparkctlcommand-line tool, for example, making it akubectlplugin that you can manage with tools likekrew.
If you are interested in trying out the Kubernetes Operator, please install it directly from the GCP Marketplace, check out the documentation and let us know if you have any questions, feedback, or issues.

