Build your own generative AI chatbot directly from BigQuery
Wissem Khlifi
Senior Data Analytics & AI Specialist Lead
Firat Tekiner
Product Management
Organizations today have access to a wealth of data, including customer information, financial records, operational logs, and more, which they aim to leverage for building new generative AI solutions. However, they face a number of challenges:
-
Building and training LLMs requires significant technical expertise and computational resources. Teams usually need to use many different frameworks and application stacks to manage their environments.
-
There are challenges around data governance and data quality. Data often coming from non-managed or non-curated datastores makes it difficult to productionize these applications. At the end of the day, LLMs are only as good as the data they are trained on.
-
Understanding how LLMs arrive at their answers can be challenging, which can raise concerns about a solution’s trust and accountability. When you understand the data that you feed into the model, you have better assurances and better understanding of the model’s output. Given this, imagine doing this through your enterprise data lake and data warehouse — data that you have a good understanding of. Therefore, applying similar rules in your AI application helps in terms of managing the data quality.
-
AI sometimes struggles with the nuances of human language, for example humor or idiomatic expressions, which can lead to misunderstandings. For a global enterprise, any internal chatbot needs to be able to handle multiple languages and cultural contexts, which can be complex to implement.
How BigQuery and Gemini models can help
In this blog we will demonstrate how to build a sample application called DataSageGen, an innovative chatbot designed to be a personal guide to access and process information from a vast array of sources, including:
-
Data and AI product documentation
-
Blog posts and white papers
-
Community knowledge
-
Product and event announcements
Simply ask DataSageGen a question, and it will intelligently search and retrieve relevant information, providing you with concise and understandable answers.
But DataSageGen is more than just a search engine. It leverages advanced techniques like retrieval augmented generation (RAG) and BigQuery ML to understand the context of your query and deliver the most relevant and insightful responses.
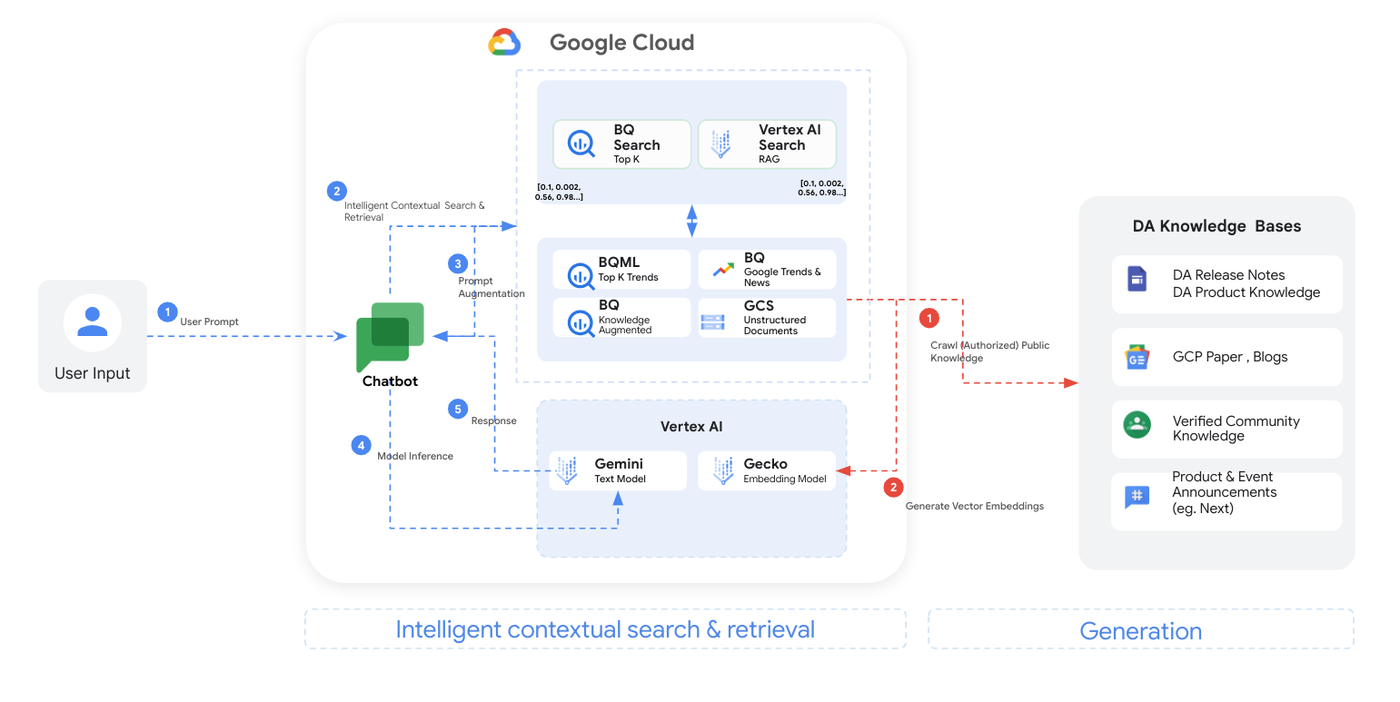
Here's how it works in the nutshell:
-
User input: You ask DataSageGen a question through the chatbot interface.
-
Intelligent search and retrieval: DataSageGen uses a combination of BigQuery, Vertex AI Search, and RAG to identify the most relevant information from its knowledge base.
-
Prompt augmentation: The user's question is enriched with additional context and instructions to guide the chatbot's response.
-
Model inference: The augmented prompt is processed by the powerful Gemini Pro model in Vertex AI, which generates a tailored and informative answer.
-
Response generation: DataSageGen delivers the answer back to you in a clear and concise way.
Solutions like these offer valuable insights for anyone considering building a chatbot to serve a technical knowledge base. Therefore, we are providing the detailed steps here for you so that you can leverage these capabilities to build your own knowledge base, without your enterprise data leaving your enterprise data warehouse (e.g. BigQuery) or your unstructured data (in Cloud Storage).
Building the DataSageGen data architecture
Step 1: Collecting user input
The flow initiates with capturing the user's input through the DataSageGen chatbot interface. The user's query or command, referred to as the "User Prompt," is extracted from the request payload using Flask's request handling. This step is crucial, as it determines the input for the entire processing pipeline.
Class/Method explanation:
-
Flask global request object - A global request object used in Flask applications to handle incoming request data.
-
request.json.get('question', '') - Extracts the 'question' key value from the JSON formatted request payload. If the key does not exist, it defaults to an empty string. This method ensures that the input handling is robust and error-free.
Step 2: Intelligent contextual search and retrieval
In this step, we use BigQuery ML to predict top results based on data trends, plus advanced text analysis (RAG) to tap into release notes, whitepapers, community knowledge, and announcements. To pinpoint the best answers, we then convert the questions into semantic "embeddings", capturing their deeper meaning. This helps ensure your technical data analytics queries get the most relevant, up-to-date information. Here is a more detailed description of Step 2:
-
BigQuery Search Top K on top of BigQuery ML model: This queries curated datasets to predict the top 'K' results, considering the context and trends across multiple dimensions.
-
Vertex AI Search: This augments the search with data knowledge powered by RAG , a combining retrieval of relevant unstructured documents and text generation. The flow includes a variety of knowledge sources, such as:
-
Data and analytics release notes and product knowledge: Automatic and periodic crawls of updates and detailed information on products that the DataSageGen chatbot can reference.
-
Google Cloud whitepapers and blogs: Written resources that offer insights and information relevant to Google Cloud Platform Data and Analytics services.
-
Verified community knowledge: Trusted information from the Data and Analytics community of users that could be used to answer queries or solve issues.
-
Data and analytics product and event announcements: Information on new data and analytics products and events that the DataSageGen chatbot can access to provide current information.
This step involves generating a semantic representation of the user's query using the `generate_text_embeddings` function. The function transforms the textual input into a dense vector (embedding), capturing the semantic nuances of the input. This vector representation is then used for contextual search and retrieval operations.
Class/Method explanation:
-
`TextEmbeddingModel.from_pretrained("textembedding-gecko@001")`: Instantiates a Vertex AI text embedding model that has been pre-trained on a large corpus of text data. This method loads the "textembedding-gecko@001" Vertex AI model, preparing it for generating embeddings. This part of the code can be found in the data ingestion component.
-
`model.get_embeddings([sentences])`: Generates embeddings for the input sentences. The embeddings are dense vector representations of the input text, facilitating semantic understanding and comparisons.
-
Using BigQuery ML from the Data & Analytics trends tables, we use the `ML.PREDICT` function alongside a machine learning model trained in BigQuery ML. The `ML.PREDICT` function allows us to use the trained model to make predictions based on new data. This approach allows us to leverage your BigQuery ML model for scoring and retrieve the top-k Data and Analytics trends directly using BigQuery.
Step 3: Prompt augmentation
The prompt passed to DataSageGen chatbot by the user is augmented by the retrieval of RAG. In this step we fine-tune responses received for a better user experience. We take your question and add instructions on tone, plus augment it with a list of off-limit topics (such as hate speech, violence, or sensitive personal information). This helps ensure the chatbot's answers are helpful and stay on track.
The user prompt is augmented with structured instructions and a list of banned phrases to guide the chatbot's response generation. This augmentation involves appending additional context that instructs the model on how to format its responses and topics to avoid, ensuring the output is aligned with user expectations and content guidelines.
Class/Method explanation:
-
String manipulation: Combines the structured instructions with banned phrases (`banned_phrases`), and the original user prompt into a single, augmented prompt. This process prepares the augmented input for the model.
Step 4: Model inference
The augmented prompt is passed as input to the Gemini Pro model in Vertex AI for inference and tuned answer retrieval. In this step we get to the heart of your query! We add guidance to your question, then tap into the Gemini Pro model on Vertex AI. To enrich its answers, we search for a vector index for the most relevant background information. This process means you get more precise, informative responses to complex data analytics questions.
This phase utilizes the augmented prompt as input to the Gemini Pro model hosted on Vertex AI for inference. Additionally, it involves querying Vertex AI vector search index for contextually relevant documents based on the query embeddings. This enriched context, combined with the model's inference capabilities, allows for generating nuanced and informed responses.
Class/Method explanation:
-
`aiplatform.MatchingEngineIndexEndpoint(index_endpoint_name)`: Initializes a connection to a specific Matching Engine index endpoint, allowing for semantic search operations within stored documents.
-
`index_endpoint.find_neighbors(deployed_index_id, queries, num_neighbors)`: Retrieves the nearest neighbors for the query embedding from the specified index, providing contextually relevant information for response generation.
-
`GenerativeModel("gemini-pro")`: Loads the "gemini-pro" generative model, prepared for generating text based on the augmented prompt. This class encapsulates the functionality for interacting with the pretrained machine learning model in Vertex AI, facilitating the generation of coherent and contextually appropriate text outputs.
Step 5: Response generation
After processing the information by the Gemini Pro model in Vertex AI, the DataSageGen chatbot generates a response that is delivered back to the user.
In the final step, the Gemini Pro model processes the augmented prompt, including the contextual information retrieved from the Matching Engine index, to generate a tailored response. This response is then formatted and delivered back to the user, completing the interaction loop.
Class/Method explanation:
-
Response Delivery: The generated response is sent back to the user through the DataSagGen chatbot interface, leveraging web technologies and possibly the Flask framework to manage the client-server communication.
Making DataSageGen an application
In the final step, we transform the RAG into a robust web application. Identity-Aware Proxy (IAP) secures access, ensuring only authorized users can interact with the chatbot. HTTPS Cloud Load Balancing ensures optimal performance and reliability by distributing traffic efficiently, especially during peak usage or maintenance windows. And Cloud Run hosts the chatbot, automatically scaling resources to meet demand while optimizing costs. change, load balancer allows managing such unforeseen challenges.
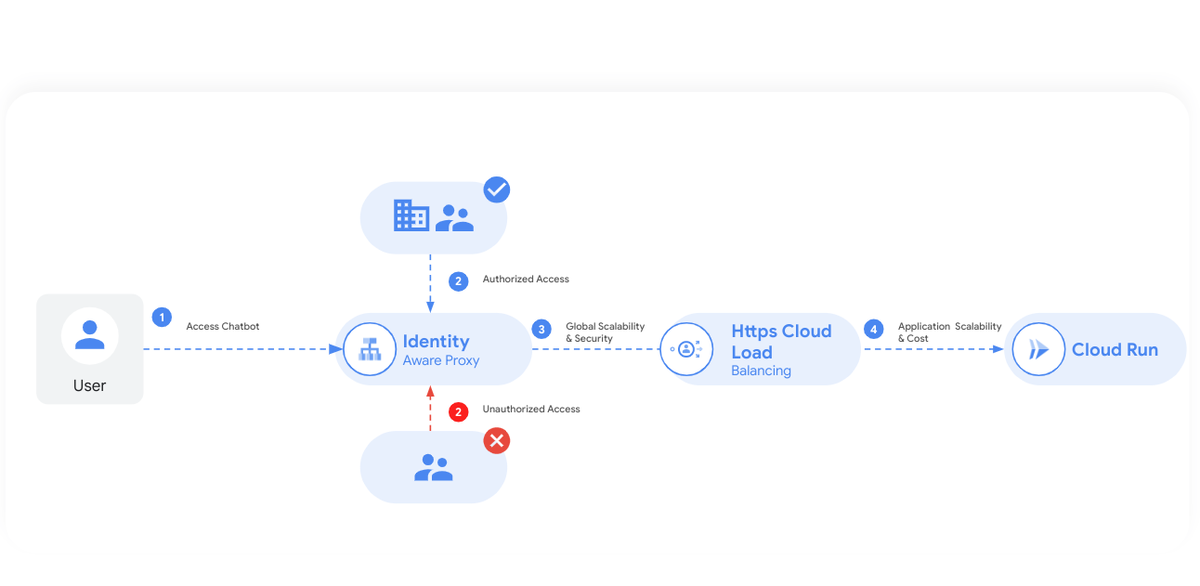
This image outlines the application infrastructure architecture of the DataSageGen chatbot system, focusing on security and scalability. The various components are:
1. User Access: Users start by accessing the DataSageGen chatbot, through a web interface.
2. Identity Aware Proxy (IAP): As users attempt to access the DataSageGen chatbot, the IAP acts as a gatekeeper.
-
Authorized access: IAP allows users with the right credentials (authenticated and authorized) to proceed.
-
Unauthorized access: Users without proper credentials are blocked, ensuring that only legitimate users can interact with the chatbot.
HTTPS Cloud Load Balancing: Once past the IAP, the architecture employs HTTPS Cloud Load Balancing to manage incoming traffic. This provides global scalability and fast, 6 sec failover, meaning it can handle a high volume of requests and quickly reroute traffic if a part of the system fails.
3. Cloud Run: This is the final step, where the DataSageGen chatbot application is hosted. Cloud Run allows for application scalability and manages costs effectively, automatically scaling based on incoming requests and charging only for the compute resources used during request processing.
Overall, the DataSageGen chatbot application architecture emphasizes secure access control with IAP, robust traffic management with HTTPS Cloud Load Balancing, and efficient resource use and scalability with Cloud Run.
Conclusion
Knowledge-based chatbots are different. They don't just spit out pre-programmed responses. Instead, they use large language models (LLMs) to analyze your entire knowledge base – FAQs, help articles, product catalogs – and generate natural, human-like responses that are contextually relevant. The benefits are immense:
-
Aggregate your knowledge and capabilities in one place
-
Get the right answers within the context, allowing teams to spend more time on their core activities
-
Enjoy 24/7, multilingual support: No more waiting for agents — customers get instant help, regardless of the time of day or what language they speak.
-
Scale your support without hiring: Automate repetitive queries, free up agents, and clear ticket backlogs.
-
Future-proof your contact center: Handle unexpected surges in support volume without breaking a sweat.
-
Get started quickly and easily: No technical expertise needed. Connect your knowledge base and you're good to go.
But remember, to take advantage of generative AI to build a next-generation chatbot, you need to:
-
Prep your knowledge base: Ensure information is up-to-date, consistent, and text-based.
-
Set guardrails: Define what questions your bot can answer and what kind of responses it can give.
With these considerations, knowledge-based chatbots can revolutionize customer support, offering enhanced experiences, increased efficiency, and a future-proof solution for your business.
The field of generative AI is rapidly evolving, requiring ongoing adaptation and refinement of chatbot solutions.The DataSageGen architecture helps ensure that you get the most accurate and relevant information possible, saving you time and effort, while also being built with security and scalability in mind. It uses Identity Aware Proxy (IAP) to control access, HTTPS Cloud Load Balancing for efficient traffic management, and Cloud Run for cost-effective scalability. Whether you're a data engineer, product manager, or simply curious about data and AI, DataSageGen is an invaluable tool for anyone looking to deepen their understanding and navigate this complex field with ease.
To learn more about BigQuery’s new RAG and vector search features, check out the documentation. Use this tutorial to apply Google's best-in-class AI models to your data, deploy models and operationalize ML workflows without moving data from BigQuery. Check out this github repository to see how you can deploy such an application with your own corpus. You can also watch a demonstration on how to build an end-to-end data analytics and AI application directly from BigQuery while harnessing the potential of advanced models like Gemini.

