How to build comprehensive customer financial profiles with Elastic Cloud and Google Cloud
Yang Li
Staff Cloud Solutions Architect, Google Cloud
Dimitri Marx
Partner Solutions Architecture Lead, Elastic
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialFinancial institutions have vast amounts of data about their customers. However, many of them struggle to leverage data to their advantage. Data may be sitting in silos or trapped on costly mainframes. Customers may only have access to a limited quantity of data, or service providers may need to search through multiple systems of record to handle a simple customer inquiry. This creates a hazard for providers and a headache for customers.
Elastic and Google Cloud enable institutions to manage this information. Powerful search tools allow data to be surfaced faster than ever - Whether it's card payments, ACH (Automated Clearing House), wires, bank transfers, real-time payments, or another payment method. This information can be correlated to customer profiles, cash balances, merchant info, purchase history, and other relevant information to enable the customer or business objective.
This reference architecture enables these use cases:
1. Offering a great customer experience: Customers expect immediate access to their entire payment history, with the ability to recognize anomalies. Not just through digital channels, but through omnichannel experiences (e.g. customer service interactions).
2. Customer 360: Real-time dashboards which correlates transaction information across multiple variables, offering the business a better view into their customer base, and driving efforts for sales, marketing, and product innovation.
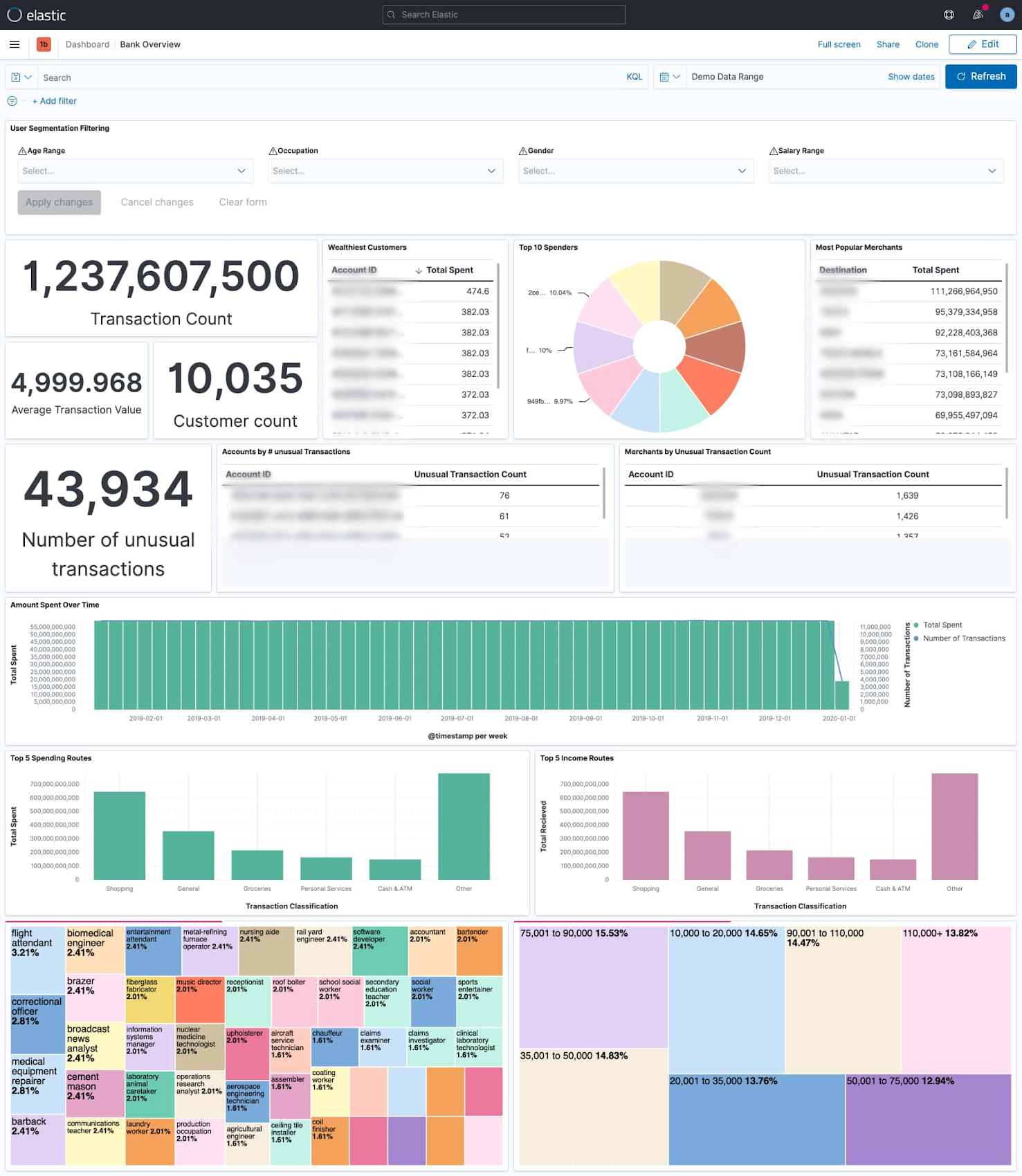
3. Partnership management: Merchant acceptance is key for payment providers. Having better access to present and historical merchant transactions can enhance relationships or provide leverage in negotiations. With that, banks can create and monetize new services.
4. Cost optimization: Mainframes are not designed for internet-scale access. Along-side with technological limitation, the cost becomes a prohibitive factor. While Mainframes will not be replaced any time sooner, this architecture will help to avoid costly access to data to serve new applications.
5. Risk reduction: By standardizing on the Elastic Stack, banks are longer limited in the number of data sources they can ingest. With this, banks can better respond to call center delays and potential customer-facing impacts like natural disasters. By deploying machine learning and alerting features, banks can detect and stamp out financial fraud before it impacts member accounts.
Architecture
The following diagram shows the steps to move data from Mainframe to Google Cloud, process and enrich the data in BigQuery, then provide comprehensive search capabilities through Elastic Cloud.
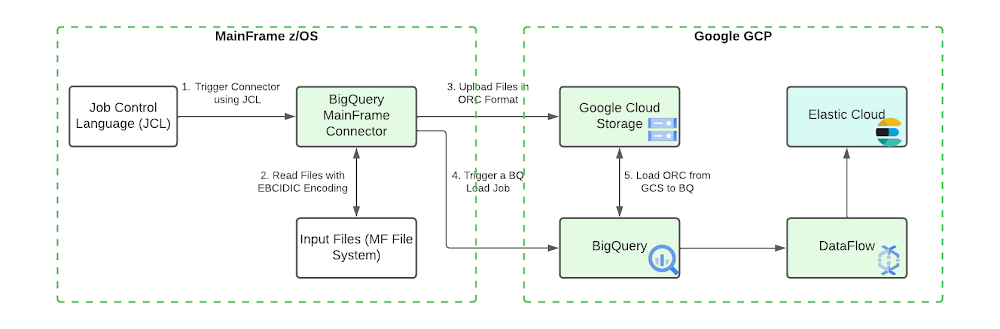
This architecture includes the following components:
Move Data from Mainframe to Google Cloud
Moving data from IBM z/OS to Google Cloud is straightforward with the Mainframe Connector, by following simple steps and defining configurations. The connector runs in z/OS batch job steps and includes a shell interpreter and JVM-based implementations of gsutil, bq and gcloud command-line utilities. This makes it possible to create and run a complete ELT pipeline from JCL, both for the initial batch data migration and ongoing delta updates.
A typical flow of the connector includes:
Reading the mainframe dataset
Transcoding the dataset to ORC
Uploading ORC file to Cloud Storage
Register ORC file as an external table or load as a native table
Submit a Query job containing a MERGE DML statement to upsert incremental data into a target table or a SELECT statement to append to or replace an existing table
Here are the steps to install the BQ MainFrame Connector:
copy mainframe connector jar to unix filesystem on z/OS
copy BQSH JCL procedure to a PDS on z/OS
edit BQSH JCL to set site specific environment variables
Please refer to the BQ Mainframe connector blog for example configuration and commands.
Process and Enrich Data in BigQuery
BigQuery is a completely serverless and cost-effective enterprise data warehouse. Its serverless architecture lets you use SQL language to query and enrich Enterprise scale data. And its scalable, distributed analysis engine lets you query terabytes in seconds and petabytes in minutes. An integrated BQML and BI Engine enables you to analyze the data and gain business insights.
Ingest Data from BQ to Elastic Cloud
Dataflow is used here to ingest data from BQ to Elastic Cloud. It’s a serverless, fast, and cost-effective stream and batch data processing service. Dataflow provides an Elasticsearch Flex Template which can be easily configured to create the streaming pipeline. This blog from Elastic shows an example on how to configure the template.
Cloud Orchestration from Mainframe
It's possible to load both BigQuery and Elastic Cloud entirely from a mainframe job, with no need for an external job scheduler.
To launch the Dataflow flex template directly, you can invoke the gcloud dataflow flex-template run command in a z/OS batch job step.
If you require additional actions beyond simply launching the template, you can instead invoke the gcloud pubsub topics publish command in a batch job step after your BigQuery ELT steps are completed, using the --attribute option to include your BigQuery table name and any other template parameters. The pubsub message can be used to trigger any additional actions within your cloud environment.
To take action in response to the pubsub message sent from your mainframe job, create a Cloud Build Pipeline with a pubsub trigger and include a Cloud Build Pipeline step that uses the gcloud builder to invoke gcloud dataflow flex-template run and launch the template using the parameters copied from the pubsub message. If you need to use a custom dataflow template rather than the public template, you can use the git builder to checkout your code followed by the maven builder to compile and launch a custom dataflow pipeline. Additional pipeline steps can be added for any other actions you require.
The pubsub messages sent from your batch job can also be used to trigger a Cloud Run service or a GKE service via Eventarc and may also be consumed directly by a Dataflow pipeline or any other application.
Mainframe Capacity Planning
CPU consumption is a major factor in mainframe workload cost. In the basic architecture design above, the Mainframe Connector runs on the JVM and runs on zIIP processor. Relative to simply uploading data to cloud storage, ORC encoding consumes much more CPU time. When processing large amounts of data it's possible to exhaust zIIP capacity and spill workloads onto GP processors. You may apply the following advanced architecture to reduce CPU consumption and avoid increased z/OS processing costs.
Remote Dataset Transcoding on Compute Engine VM
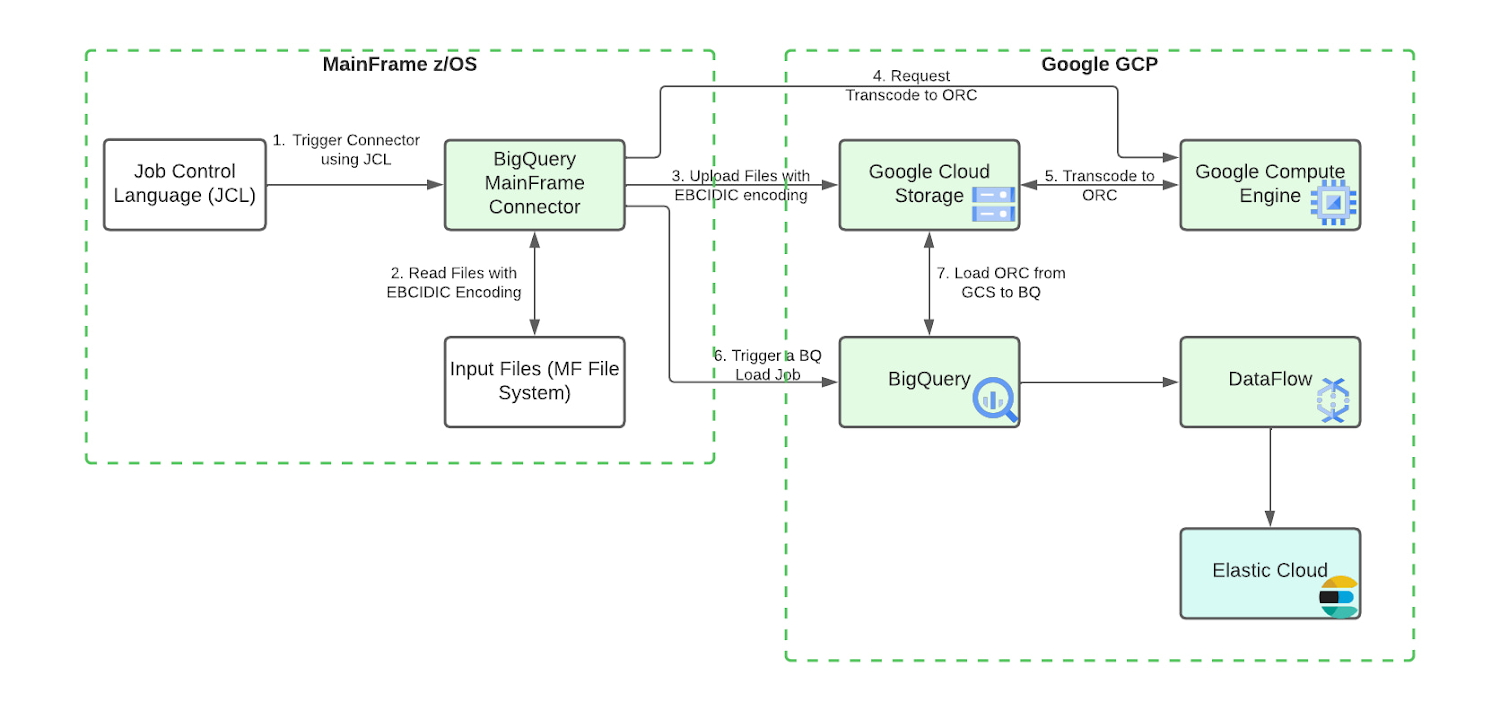
To reduce mainframe CPU consumption, ORC file transcoding can be delegated to a GCE instance. A gRPC service is included with the mainframe connector specifically for this purpose. Instructions for setup can be found in the mainframe connector documentation. Using remote ORC transcoding will significantly reduce CPU usage of the Mainframe Connector batch jobs and is recommended for all production level BigQuery workloads. Multiple instances of the gRPC service can be deployed behind a load balancer and shared by all Mainframe Connector batch jobs.
Transfer Data via FICON and Interconnect
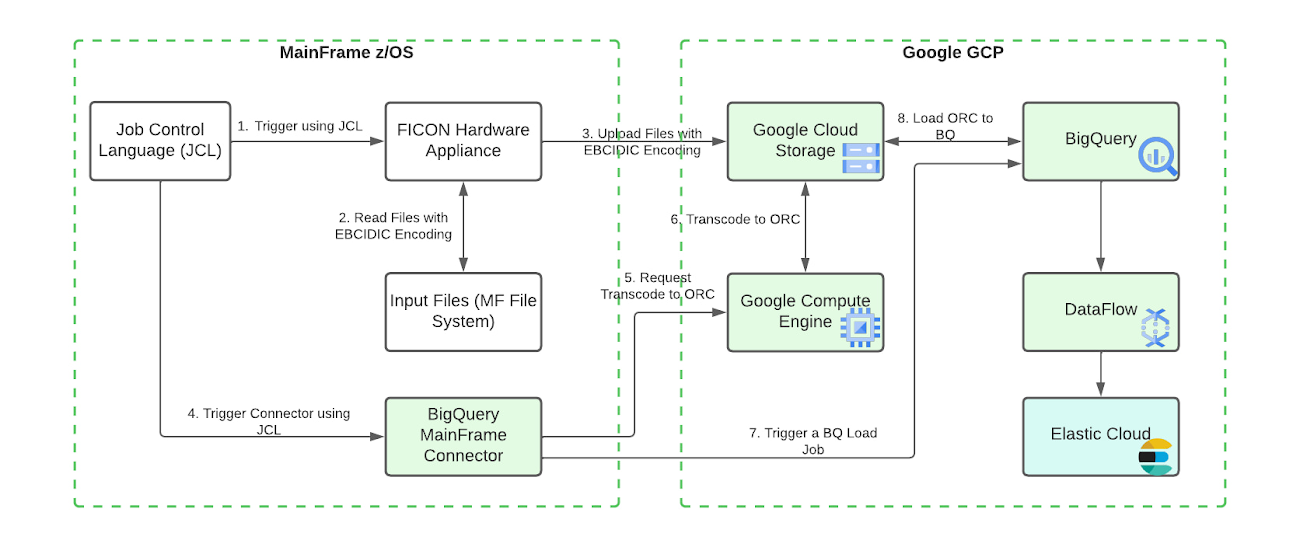
Google Cloud technology partners offer products to enable transfer of mainframe datasets via FICON and 10G ethernet to Cloud Storage. Obtaining a hardware FICON appliance and Interconnect is a practical requirement for workloads that transfer in excess of 500GB daily. This architecture is ideal for integration of z/OS and Google Cloud because it largely eliminates data transfer related CPU utilization concerns.
We really appreciate Jason Mar from Google Cloud who provided rich context and technical guidance regarding the Mainframe Connector, and Eric Lowry from Elastic for his suggestions and recommendations, and the Google Cloud and Elastic team members who contributed to this collaboration.

