Announcing preview of BigQuery’s native support for semi-structured data
Nick Orlove
BigQuery Product Manager
Francis Lan
Staff Software Engineer, Google Cloud
Today we’re announcing a public preview for the BigQuery native JSON data type, a capability which brings support for storing and analyzing semi-structured data in BigQuery.
With this new JSON storage type and advanced JSON features like JSON dot notation support, adaptable data type changes, and new JSON functions, semi-structured data in BigQuery is now intuitive to use and query in its native format.
You can enroll in the feature preview by signing up here.
The challenge with changing data
Building a data pipeline involves many decisions. Where will my data be ingested from? Does my application require data to be loaded as a batch job or real-time streaming ingest? How should my tables be structured? Many of these decisions are often made up front before a data pipeline is built, meaning table or data type changes down the road can unfortunately be complex and/or costly.
To handle such events, customers have traditionally had to build complex change-handling automation, pause data ingest to allow for manual intervention, or write unplanned data to a catch-all String field which later has to be parsed in a post-process manner.
These approaches all add cost, complexity, and slow down your ability to make data driven insights.
Native JSON to the rescue
JSON is a widely used format that allows for semi-structured data, because it does not require a schema. This offers you added flexibility to store and query data that doesn’t always adhere to fixed schemas and data types. By ingesting semi-structured data as a JSON data type, BigQuery allows each JSON field to be encoded and processed independently. You can then query the values of fields within the JSON data individually via dot notation, which makes JSON queries easy to use. This new JSON functionality is also cost efficient compared to previous methods of extracting JSON elements from String fields, which requires processing entire blocks of data.
Thanks to BigQuery’s native JSON support, customers can now write to BigQuery without worrying about future changes to their data. Customers like DeNA, a mobile gaming and e-commerce services provider, sees value in leveraging this new capability as it provides faster time to value.
"Agility is key to our business. We believe Native JSON functionality will enable us to handle changes in data models more quickly and shorten the lead time to pull insights from our data."—Ryoji Hasegawa, Data Engineer, DeNA Co Ltd.
JSON in action
The best way to learn is often by doing, so let’s see native JSON in action. Suppose we have two ingestion pipelines, one performing batch ingest and the other performing real-time streaming ingest, both of which ingest application login events into BigQuery for further analysis. By leveraging the native JSON feature, we can now embrace upstream data evolution and changes to our application.
Batch ingesting JSON as a CSV
JSON types are currently supported via batch load jobs of CSV-formatted files. So as an example, let’s create a new table called json_example.batch_events and then ingest this correctly escaped login_events.csv file into BigQuery with the below bq commands. You’ll notice the batch_events table has both structured columns as well as a labels field which uses the new JSON type for our semi-structured fields. In this example some application values will remain highly structured such as event creationTime, event ID, event name, etc. so we’ll define this table as storing both structured data as well as semi-structured data.
We’ll look at how to run queries using the new JSON functions a bit later in this blog, but first let’s also explore how we might stream semi-structured real-time events into BigQuery using the JSON type too.
Real-Time Streaming JSON Events
Now let’s walk through an example of how to stream the same semi-structured application login events into BigQuery. We’ll first create a new table called json_example.streaming_events which leverages the same combination of structured and semi-structured columns. However, instead of using the bq command line, we’ll create this table by running the SQL Data definition language (DDL) statement:
BigQuery supports two forms of real-time ingestion: the BigQuery Storage Write API and the legacy streaming API. The Storage Write API provides a unified data-ingestion API to write data into BigQuery via gRPC and provides advanced features like exactly-once delivery semantics, stream-level transactions, support for multiple workers, and is generally recommended over the legacy streaming API. However because the legacy streaming API is still in use by some customers, let’s walk through both examples: ingesting JSON data through the Storage Write API and ingesting JSON data through the legacy insertAll streaming API.
JSON via the Storage Write API
To ingest data via the Storage Write API, we’ll stream data as protocol buffers. For a quick refresher on working with protocol buffers, here’s a great tutorial.
We’ll first define our message format for writing into the json_example.streaming_events table using a .proto file in proto2. You can copy the file from here, then run the following command within a Linux environment to update your protocol buffer definition:
We’ll then use this sample Python code to stream both structured and semi-structured data into the streaming_events table. This code streams a batch of row data by appending proto2 serialized bytes to the serialzed_rows repeated field like the example below. Of particular note is the labels field which was defined within our table to be JSON.
Once executed, we can see our table now has ingested a few rows from the Storage Write API!

JSON via the legacy insertAll streaming API
And lastly, let’s explore streaming data to the same streaming_events table with the legacy insertAll API. With the insertAll API approach, we’ll ingest a set of JSON events stored within a local file in real-time to our same streaming_events table. The events will will be structured like the below, with the labels field being highly variable and semi-structured:

Now run the following Python code which reads data from the local JSON events file and streams it into BigQuery.
Now that our JSON events have successfully been ingested into BigQuery (through batch ingest, the Storage Write API, the legacy streaming API, or even all three) we’re ready to query our semi-structured data in BigQuery!
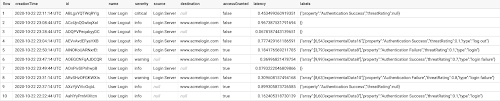
Querying your new JSON data
With the introduction of the native JSON type, we’re also introducing new JSON functions to easily and efficiently query data in its native format.
For instance, we can get a count of the events we ingested which encountered a login authentication failure by filtering on the labels.property field of the JSON value using dot notation:
We can also perform aggregations by averaging event threats caused by login failures within our data set by natively casting a threatRating field within labels as a FLOAT:
Native JSON with existing tables
What if you have existing tables, can you take advantage of the Native JSON type without rewriting all your data? Yes!
BigQuery makes operations like modifying existing table schemas a snap though DDL statements like the below which adds a new JSON column titled newJSONField to an existing table:
From here, you can decide on how you want to leverage your newJSON column by either converting existing data (perhaps existing JSON data stored as a String) into the newJSON field or by ingesting net new data into this column.
To convert existing data into JSON, you can leverage an UPDATE DML statement through either the PARSE_JSON function, which converts a String into a JSON type, or by using the TO_JSON function, which converts any data type into a JSON type. Here are examples of each below:
Converting a String into JSON:
Converting existing data stored as a nested and repeated STRUCT, like the example here, into JSON:
How can you get started with native JSON in BigQuery?
Data comes in all forms, shapes, sizes, and never stops evolving. If you’d like to support your data and its future evolution with the BigQuery native JSON preview feature, please complete the sign up form here.

