BigQuery in June: a new data type, new data import formats, and finer cost controls
Tino Tereshko
Product Manager, Google BigQuery
This is the first installment in a monthly review of recently-released BigQuery features. While our rather active release notes do contain concise but actionable information, we’ve heard from some of our users that they’d love a little more information on these updates and what they mean in a bigger picture.
This month, we present a number of practical new features, primarily focused on data types and data file formats. We hope these features unlock or enhance BigQuery for your particular use case or industry.
A new data type
NUMERIC type is available in betaMany of our customers need more flexibility than integers (for tracking sub-denominations) or floating point numbers (with dynamic precision) can provide. When manipulating high volatility currencies, exchange rates, or percentages with fixed precision, it’s easier to implement more complex or multi-step mathematical operations with the NUMERIC type without having to worry about casting from type to type. (No need to cast about for answers!)
BigQuery now includes the NUMERIC data type to address all of these needs in a 64-bit data type.
To learn more, view the NUMERIC type documentation.
Data formats (for ingest)
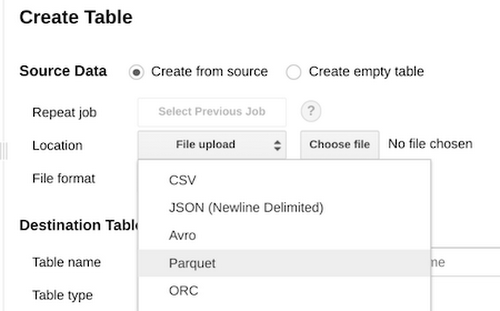
Parquet and ORCParquet is now generally available as a natively supported format for ingest into BigQuery. In addition, native support for ingesting Optimized Row Columnar (ORC) format files is also now available in BigQuery.
Parquet and ORC are ubiquitously-adopted open source columnar storage formats, especially among Hadoop practitioners. For folks who already have data in these formats, BigQuery simplifies and streamlines the ingest process. We aim to make it as easy as possible to move data in your data warehouse.
"Parquet started in 2012, inspired by the Dremel paper, and I'm really excited to see it go full circle today with BigQuery offering support for it,” says Julien Le Dem, VP Apache Parquet, Principal Engineer at WeWork. “This is a great step towards better integration between the big data ecosystem and the warehouse, which simplifies the users' life and reduces the prevalence of silos."
Head over to Parquet
https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-parquet
and ORC ingest documentation for more.
Enhancing DML
BigQuery has had support forUPDATE, DELETE, and INSERT DML operations for some time, but what if you need to combine multiple datasets, based on conditional criteria? The MERGE statement allows you to efficiently insert, update, and delete data in a table with one operation, simplifying your or your data scientists’ workflows.In addition, BigQuery has added DML (Data Manipulation Language) support over tables that have an active streaming buffer. BigQuery has also relaxed quotas on UPDATE, DELETE, and MERGE DML statements from 96 to 200 per table per day. This may not seem like a big change, but it’s important to note that each statement can process an unlimited number of rows at one time. We aim to give you the flexibility to do more queries, even though each individual query can access a tremendous amount of data.
You can update table data based on the results of a query (via correlated mutations), and batching such operations is a useful best practice for BigQuery. BigQuery quotas are there to protect the user, so if your use case requires higher limits, please talk to us via your account team, on Stackoverflow or on Twitter!
These improvements to DML make it easier for you to manage changes to your data in BigQuery.
BigQuery self service Cost Controls
Project-level query cost control limits will now be applied within minutes. The Cloud Console Quota page will show current utilization for projects with a limit defined:
With this release, folks can more effectively manage and monitor their spend on BigQuery. Setting a daily project-wide budget is now faster and easier.
For more updates, please subscribe to the BigQuery Release Notes. Finally, we hope to see you at NEXT ‘18, in San Francisco from July 24-26, to learn about our new data- and machine learning-oriented announcements!


