Maintain business continuity across regions with BigQuery managed disaster recovery
Larry Henderson
Sr. Product Manager
Brian Welcker
Director, Product Management
Geographical redundancy is a fundamental part of building a resilient cloud-based data strategy. For many years, BigQuery has offered an industry-leading 99.99% uptime service-level agreement (SLA) for availability within a single geographical region. Full redundancy across two data centers within a single region is included with every BigQuery dataset you create and is managed in a completely transparent manner.
For customers looking for enhanced redundancy across large geographic regions, we are now introducing managed disaster recovery for BigQuery. This feature, now in preview, offers automated failover of compute and storage and a new cross-regional SLA tailored for business-critical workloads. This feature enables you to ensure business continuity in the unlikely event of a total regional infrastructure outage. Managed disaster recovery also provides failover configurations for capacity reservations, so you can manage query and storage failover behavior. This feature is available through BigQuery Enterprise Plus edition.
How does it work?
Customers using BigQuery’s enterprise plus edition can now configure their capacity reservations to enable automated failover across distinct geographic regions. Extending the capabilities of BigQuery’s cross-region dataset replication, failover reservations ensure that the location of both data and compute resources are coordinated during a disaster recovery event.
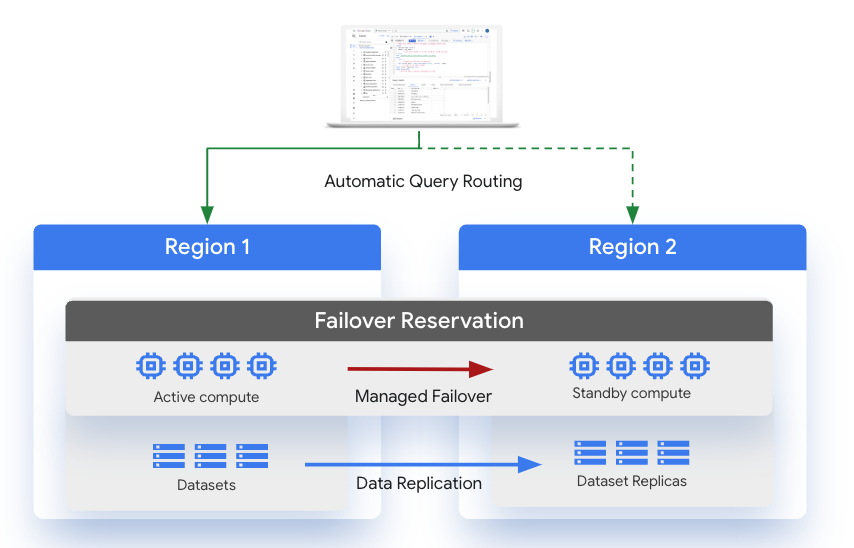
Slot capacity in the secondary region for enterprise plus edition reservations are provisioned and maintained automatically at no additional cost. Some competitive products require customers to duplicate their compute clusters in the secondary location.
In the event of a total regional outage, the secondary region can be promoted to the primary role for both compute and data. With BigQuery’s query routing layer, failover is completely transparent to end users and tools.
-
Primary region: The region containing the current primary replica of a dataset. This is also the region where the dataset data can be modified (e.g. loads, DDL, or DML).
-
Secondary region: The region where the failover reservation standby capacity and replicated datasets are available in the case of a regional outage.
-
Failover reservation: An enterprise plus edition reservation configured with a primary/secondary region pair. Note: Datasets are attached to failover reservations.
The dataset replica in the primary region is the primary replica, and the replica in the secondary region is the secondary replica. These roles are swapped during the failover process.
The primary replica is writeable, and the secondary replica is read-only. Writes to the primary replica are asynchronously replicated to the secondary replica. Within each region, the data is stored redundantly in two zones. Network traffic never leaves the Google Cloud network.
What is a region pair?
A region pair in BigQuery’s managed disaster recovery is a pair of regions that are geographically supported by turbo replication and compute redundancy. Within the defined region pair, BigQuery replicates data between the two regions and manages secondary available capacity. This replication allows BigQuery managed disaster recovery to provide high availability and durability for data. Customers are able to define their desired region pair (based on the supported regions) per failover reservation.
Supported region pairs
BigQuery’s managed disaster recovery feature supports failover reservations across specific region pairs (similar to Cloud Storage, for regions within a geographic area). You can designate either region in a pair for your initial primary or secondary region.
Capacity in the secondary region
BigQuery ensures that the capacity of your primary region will be available in your secondary region within five minutes of a failover. This assurance applies to your reservation baseline, whether it’s used or not. BigQuery also provides the same level of autoscaling availability as provided in the primary.
How much does it cost?
BigQuery's managed disaster recovery feature is available with the Enterprise Plus edition. Standby compute capacity in the secondary region is included with the per slot-hour price with no requirement to purchase separate standby capacity. As an option, you may choose to provision additional Enterprise Plus reservations in the secondary region, specifically for read-only queries.
Managed disaster recovery customers are billed for replicated storage in the primary and secondary regions for associated datasets. At GA, this feature will automatically use turbo replication for data transfer between regions.
* Turbo replication is not available during preview but will be enabled automatically at general availability (GA).
Recovery Time Objective (RTO)
Promotion of a secondary reservation and associated datasets takes less than five minutes, even if the primary region is down. All queries in flight are canceled and rejected during the RTO timeline.
Recovery Point Objective (RPO)
Data will be less than 15 minutes old in secondary dataset replicas configured for failover reservation between supported region pairs, turbo replication enabled and only after initial replication is completed (also known as backfill).
Note: Turbo replication and RPO/RPO with SLA are not available during preview.
Configuration in action
During preview, managed disaster recovery configuration is supported via the BigQuery Console (UI) and SQL. The following workflow shows how you can set up and manage disaster recovery in BigQuery:
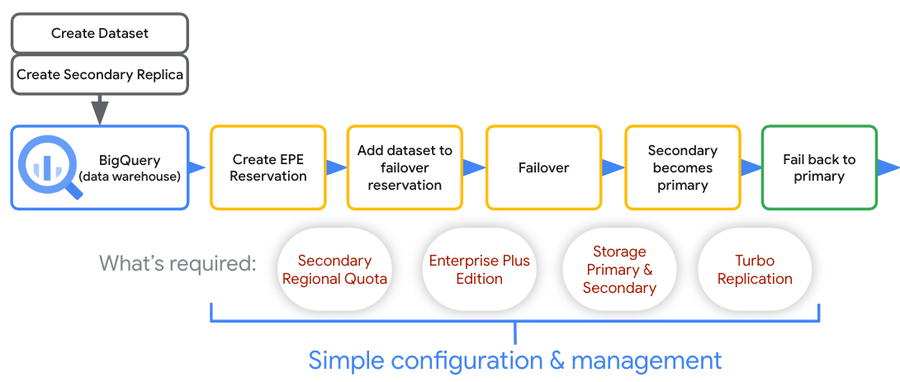
Create a replica for a given dataset
To replicate a dataset, use the ALTER SCHEMA ADD REPLICA DDL statement.
After you add a replica, it takes time for the initial copy operation to complete. You can still run queries referencing the primary replica while the data is being replicated, with no reduction in query-processing capacity.
Configure a failover reservation + attach a dataset
The first step is to create a failover reservation and specify its secondary location. Specifying a secondary location can also be done for existing Enterprise Plus reservations.
The next step is to associate one or more datasets with the failover reservation. The dataset needs to be replicated in the same primary / secondary region as specified in the reservation.
Promote the failover reservation + dataset in the secondary
Fail over the reservation and associated datasets. This must be performed from the secondary region.
Fail back to original primary
Fail back the reservation and associated datasets (performed from the new secondary/old primary).
Getting started
Business continuity is paramount for customers with mission-critical data environments. We are excited to make the preview of BigQuery’s managed disaster recovery feature available for your testing. You can learn more about managed disaster recovery and how to get started in the BigQuery managed disaster recovery QuickStart.


