BigQuery tables for Apache Iceberg: optimized storage for the open lakehouse
Anoop Johnson
Principal Engineer
Dylan Myers
Group Product Manager
For several years, BigQuery native tables have supported enterprise-level data management capabilities such as ACID transactions, streaming ingestion, and automatic storage optimizations. Many BigQuery customers store data in data lakes using open-source file formats such as Apache Parquet and table formats such as Apache Iceberg. In 2022, we launched BigLake tables to allow customers to maintain a single copy of data and benefit from the security and performance offered by BigQuery. However, BigLake tables are currently read-only; BigQuery customers have to perform data mutations through external query engines and manually orchestrate data management. Another challenge is the “small files problem” during ingestion: because cloud object stores do not support appends, table writes need to be micro-batched, requiring trade-offs between performance and data consistency.
Today, we’re excited to announce the preview of BigQuery tables for Apache Iceberg, a fully managed, Apache Iceberg-compatible storage engine from BigQuery with features such as autonomous storage optimizations, clustering, and high-throughput streaming ingestion. BigQuery tables for Apache Iceberg use the Apache Iceberg format to store data in customer-owned cloud storage buckets while providing a similar customer experience and feature set as BigQuery native tables. Through BigQuery tables for Apache Iceberg, we are bringing a decade of BigQuery innovations to the lakehouse.
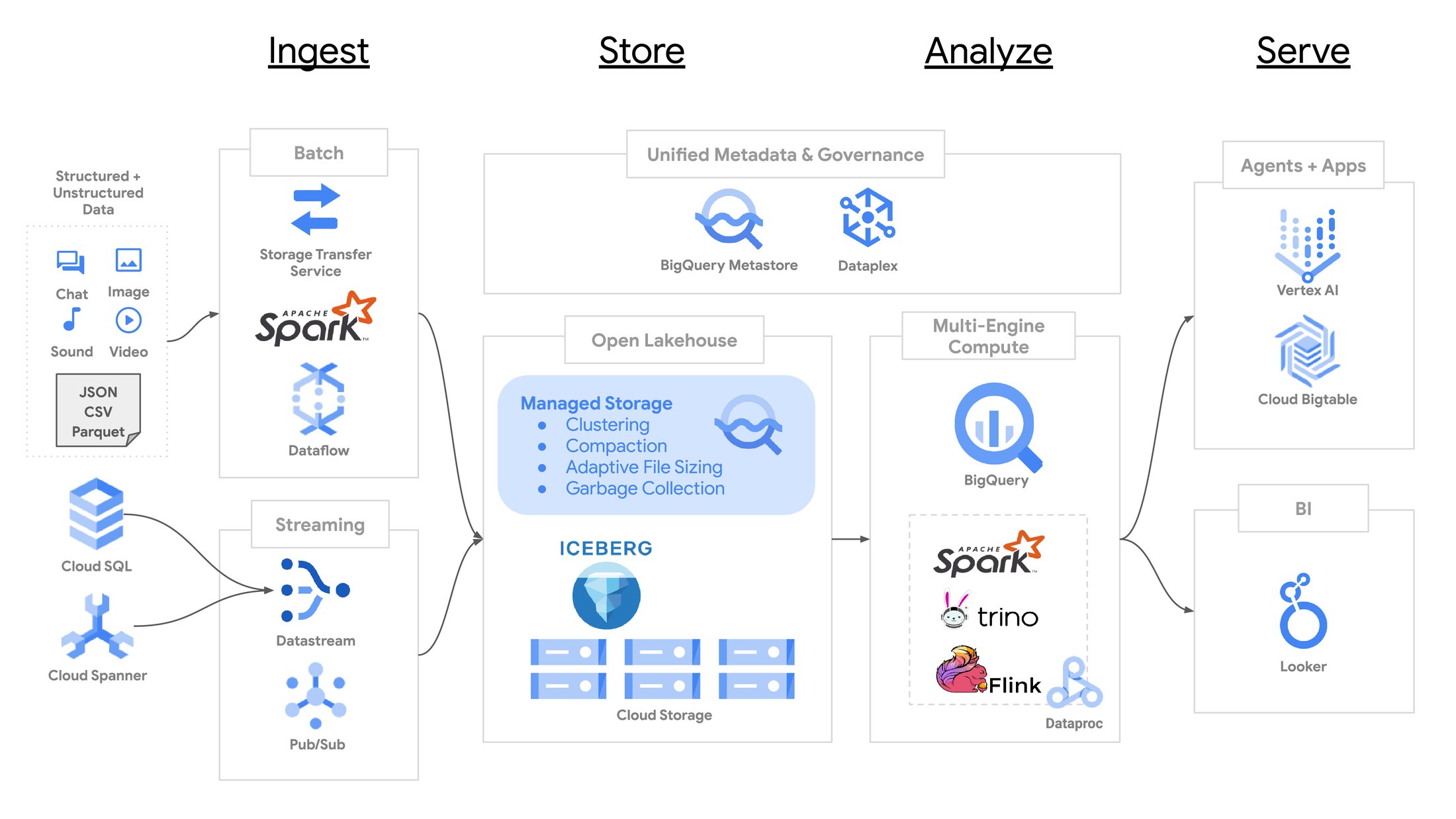
BigQuery tables for Apache Iceberg are writable from BigQuery through GoogleSQL data manipulation language (DML) and supports high-throughput streaming ingestion from open-source engines such as Apache Spark through BigQuery’s Write API. Here is an example to create a table with clustering:
Fully managed enterprise storage for the lakehouse
BigQuery tables for Apache Iceberg address the limitations of open-source table formats. With BigQuery tables for Apache Iceberg, BigQuery takes care of table-maintenance tasks autonomously without customer toil. BigQuery keeps the table optimized by combining smaller files into optimal file sizes, providing automatic re-clustering of data and garbage collection of files. For instance, optimal file sizes are adaptively determined based on the size of the table. BigQuery tables for Apache Iceberg benefit from over a decade of expertise running automated storage optimization for BigQuery native tables efficiently and cost-effectively. There is no need to run OPTIMIZE or VACUUM manually.
For high-throughput streaming ingestion, BigQuery tables for Apache Iceberg leverage Vortex, an exabyte-scale structured storage system that powers the BigQuery storage write API. BigQuery tables for Apache Iceberg durably store recently ingested tuples in a row-oriented format and periodically convert them to Parquet. The high-throughput ingestion and parallel reads are supported through the open-source Spark and Flink BigQuery connectors. Pub/Sub and Datastream can ingest data into BigQuery tables for Apache Iceberg, so you don’t need to maintain bespoke infrastructure.
BigQuery tables for Apache Iceberg store table metadata in BigQuery’s scalable metadata management system. BigQuery stores fine-grained metadata and uses distributed query processing and data management techniques to handle metadata. As a result, BigQuery tables for Apache Iceberg aren’t constrained by needing to commit the metadata to object stores, allowing a higher rate of mutations than what is possible with table formats. Since writers cannot directly mutate the transaction log, the table metadata is tamper-proof, and has a reliable audit history.
BigQuery tables for Apache Iceberg continue to support fine-grained security policies enforced by the storage APIs while extending support for governance policy management, data quality and end-to-end lineage through Dataplex.

BigQuery tables for Apache Iceberg export metadata into Iceberg snapshots in cloud storage. The pointer to the latest exported metadata will soon be registered in BigQuery metastore, a serverless runtime metadata service announced earlier this year. Iceberg metadata exports allows any engine capable of understanding Iceberg to query the data directly from Cloud Storage.
Learn more
Customers like HCA Healthcare, one of the largest health care providers in the world, see value in leveraging BigQuery tables for Apache Iceberg as their Apache Iceberg-compatible storage layer from BigQuery, making new lakehouse use-cases possible. The preview of BigQuery tables for Apache Iceberg is available in all Google Cloud regions today. You can get started today by following the documentation.

