Announcing Apache Iceberg support for BigLake
Gaurav Saxena
Group Product Manager, Engineering
Yuri Volobuev
Principal Engineer
Apache Iceberg is a popular open source table format for customers looking to build data lakes. It provides many features found in enterprise data warehouses, such as transactional DML, time travel, schema evolution, and advanced metadata that unlocks performance optimization. Iceberg’s open specification allows customers to run multiple query engines on a single copy of data stored in an object store. Backed by a growing community of contributors, Apache Iceberg is becoming the de facto open standard for data lakes, bringing interoperability across clouds for hybrid analytical workloads and systems to exchange data.
Earlier this year, we announced BigLake, a storage engine that enables customers to store data in open file formats (such as Parquet) on Google Cloud Storage and run GCP and open source query engines on it in a secure, governed, and performant manner. BigLake unifies data warehouses and lakes by enabling BigQuery and open source frameworks like Spark to access data with fine-grained access control. Today, we are excited to announce that this support now extends to the Apache Iceberg format, enabling customers to take advantage of Iceberg’s capabilities to build an open format data lake while benefiting from native GCP integration using BigLake.
“Besides BigQuery, a large segment of our data is stored on GCS. Our Datalake leveraged Iceberg to tap into this data in an efficient and scalable way on top of incredibly large datasets. BigLake integration makes this even easier by making this data available to our large BigQuery user base and leverage its powerful UI. Our users now have the ability to realize most BigQuery benefits on GCS data as if this was stored natively.” — Bo Chen, Sr. Manager of Data and Insights at Snap Inc.
Build a secure and governed Iceberg data lake with BigLake’s fine-grained security model
BigLake enables multi-compute architecture: Iceberg tables created in supported open source analytics engines can be read using BigQuery.
Once the table has been created in Spark, easily query using BigQuery:
Apache Spark already has rich support for Iceberg, allowing customers to use Iceberg’s core capabilities, such as DML, transactions, and schema evolution, to carry out large-scale transformation and data processing. Customers can run Spark using Dataproc (managed clusters or serverless), or use built-in support for Apache Spark in BigQuery (stored procedures) to process Iceberg tables hosted on Google Cloud Storage. Regardless of your choice of Spark, BigLake automatically makes those Iceberg tables available for end users to query.
Administrators can now use Iceberg tables, similar to BigLake tables, and don’t need to provide end users access to the underlying GCS bucket. The end user access is delegated through BigLake, simplifying access management and governance. Administrators can further secure Iceberg tables using fine-grained access policies, such as row, column level access control, or data masking, extending the existing BigLake governance framework to Iceberg tables. BigQuery utilizes Iceberg’s metadata for query execution, providing a performant query experience to end users.
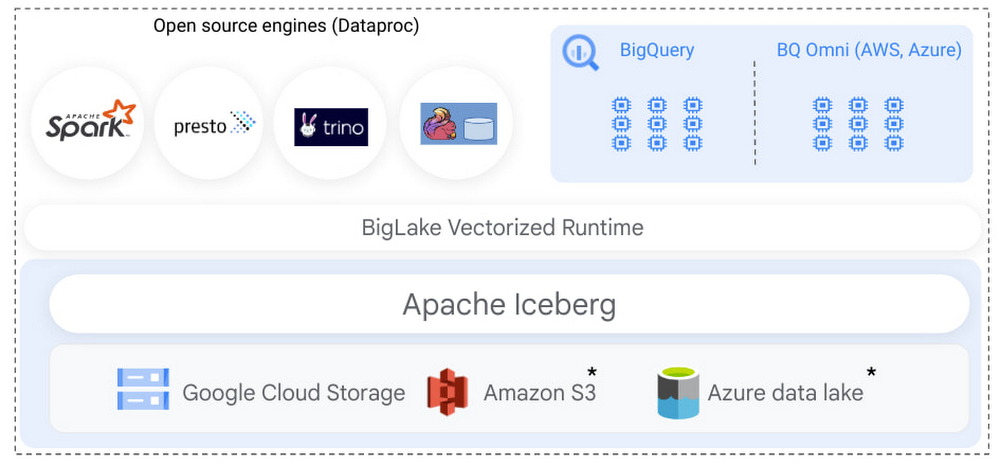
This set of capabilities enables customers to store a single copy of data on object stores using Iceberg and run BigQuery as well as Dataproc workloads on it in a secure, governed, and performant manner, eliminating the need to duplicate data or write custom infrastructure. For GCP customers who store their data on BigQuery Storage and Google Cloud Storage, BigLake now further unifies data lake and warehouse workloads. Customers can directly query, join, secure, and govern data across BigQuery storage and Iceberg tables on Google Cloud Storage. In the coming months, we will extend Apache Iceberg to Amazon S3 and Azure data lake Gen 2, enabling customers to build multi-cloud Iceberg data lakes.
Differentiate your Iceberg workloads with native BigQuery and GCP integration
The benefits of running Iceberg on Google Cloud extend beyond realizing Iceberg’s core capabilities and BigLake’s fine-grained security model. Customers can use native BigQuery and GCP integration to use BigQuery’s differentiated services on Iceberg tables created over Google Cloud Storage data. Some key integrations most relevant in the context of Iceberg are:
Securely exchange Iceberg data using Analytics Hub - Iceberg as an open standard provides interoperability between various storage systems and query engines to exchange data. On Google Cloud, customers use Analytics hub to share BigQuery & BigLake tables with their partners, customers, and suppliers without needing to copy data. Similar to BigQuery tables, data providers can now create shared datasets to share Iceberg tables on Google Cloud storage. Consumers of the shared data can use any Iceberg compatible supported query engine to consume the data, providing an open and governed model of sharing and consuming data.
Run data science workloads on Iceberg using BigQueryML - Customers can now use BigQueryML to extend their machine learning workloads to Iceberg tables stored on Google cloud storage, enabling customers to realize AI value on data stored outside of BigQuery.
Discover, detect and protect PII data on Iceberg using Cloud DLP - Customers can now use Cloud DLP to identify, discover and secure PII data elements contained in Iceberg tables, and secure sensitive data using BigLake’s fine-grained security model to meet workload compliance.
Get Started
Learn more about BigLake support for Apache Iceberg by watching this demo video, and a panel discussion of customers building using BigLake with Iceberg. Apache Iceberg support for BigLake is currently in preview, sign up to get started. Contact a Google sales representative to learn how Apache Iceberg can help evolve your data architecture.
Special mention to the engineering leadership of Micah Kornfield, Anoop Johnson, Garrett Casto, Justin Levandoski and team to make this launch possible.

