Put your data to use across organizations with a Data Sharing and Analytics Platform
Filipe Gracio, PhD
Customer Engineer, AI/ML for Public Sector
Sebastien Chaspoux
Professional Services Consultant
Securely sharing data and analytics is fundamental to an organization's data cloud strategy. It’s how you unlock and create value from your data assets, for you and your stakeholders. However, large and data-rich organizations that collaborate across teams, systems, and other organizations, often struggle to make this work. How do you get started?
We’ve been working with a UK Public Sector organization on an ambitious program to build a large hybrid and multi-cloud data sharing and analysis capability. Based on our collaboration, we are planning the next version of this platform. Here we showcase a reference, born of our experience collaborating with this and other customers with large multi-cloud landscapes. It will save you time if you’re getting started and serves as a reference if you’re already under way.
A blueprint and architecture
Part of the value that Google Cloud brings is the ability to implement an end-to-end architecture that enables organizations to extract data in real-time regardless of which cloud or datastore the data resides in, and use it in for greater insight and artificial intelligence (AI), with unified governance and access. Because our customer needs to take in data from other third-party sources, and needs to allow access to third-party users, we’ve included their specific needs in our architecture plans. Let’s go over the plans in more detail.
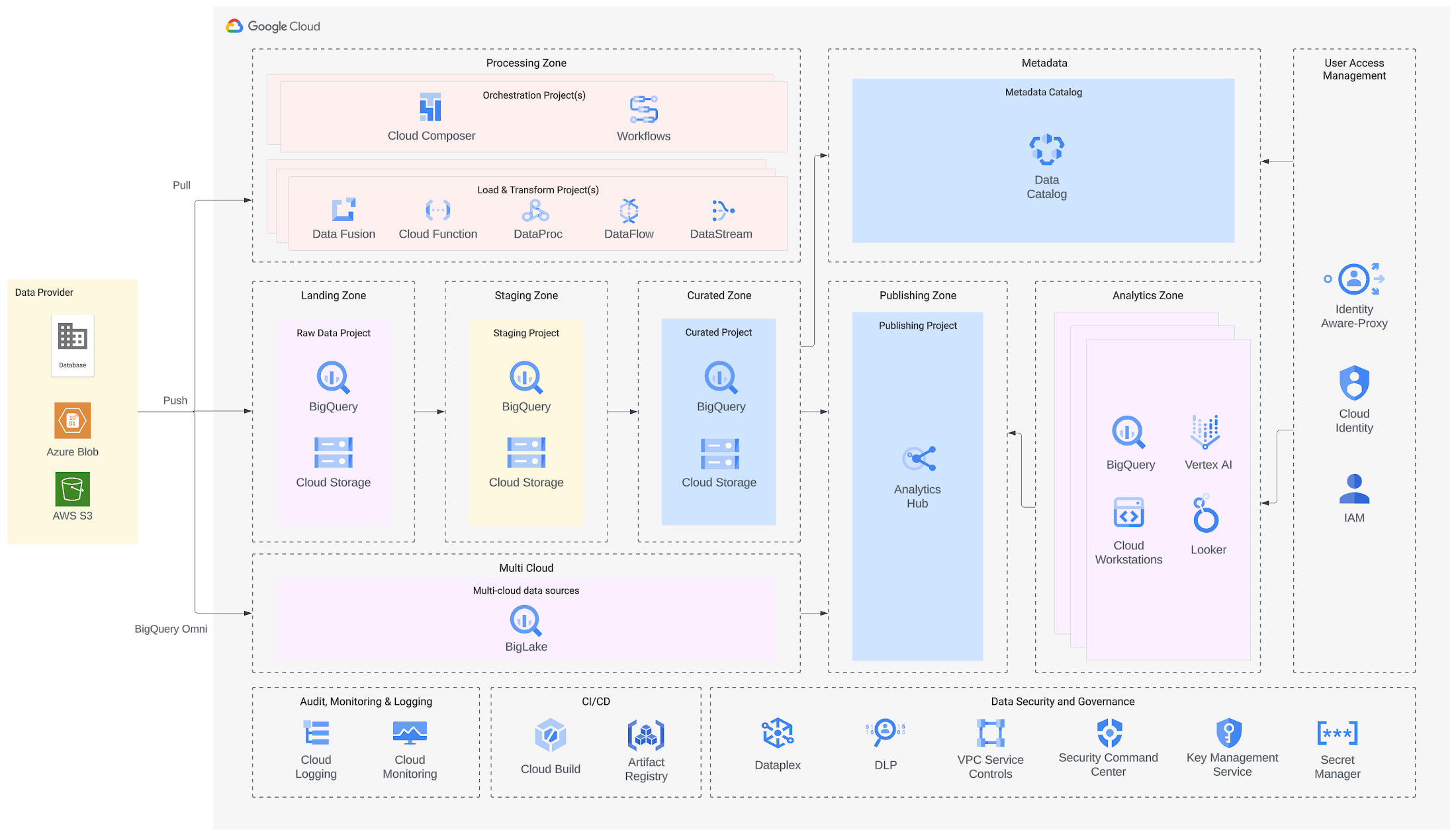
Data ingestion
It’s important to have repeatable patterns for data ingestion. For our customer, some data are held directly in Google Cloud, and others are off the platform. Many large government organizations face this challenge of multi-cloud data integration. For data that your platform will own and hold, you can pull it in via tools such as Cloud Data Fusion or Cloud Storage Transfer Service to quickly and securely ingest objects and files from various storage locations across Google Cloud, Amazon, Azure or on-premises. You can also push data using the Google Cloud Storage API, BigQuery Storage API to stream records into BigQuery in real time or to batch process an arbitrarily large number of records.
If the data sits outside Google Cloud and your organization has the rights to query it, but must keep the data where it is, you can use BigQuery Omni to query data in AWS S3 and Azure Blob in available regions. You can also use Looker and choose from its many different connectors to databases to query external data. Finally, Analytics Hub will let your users access data published by other GCP organizations.
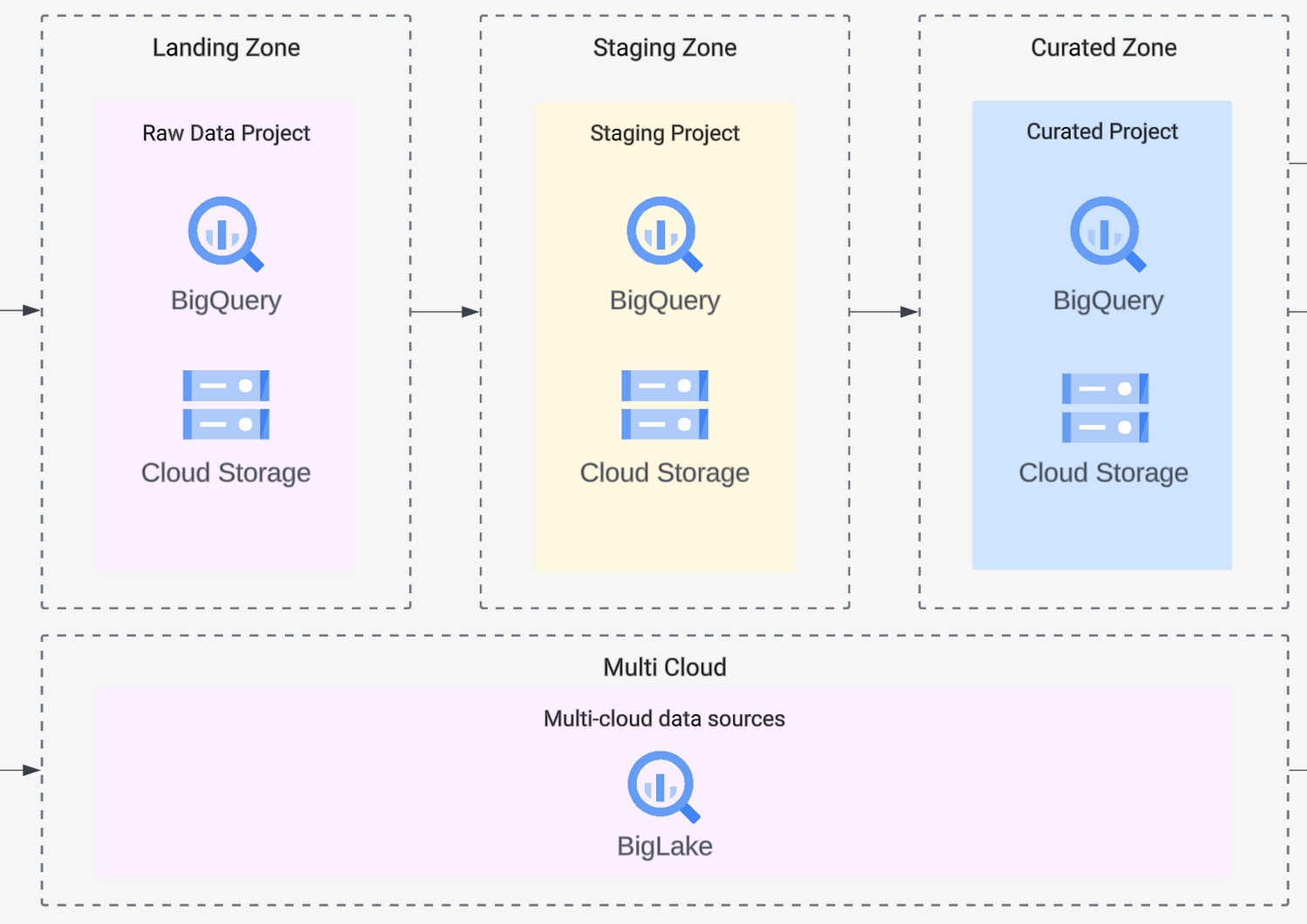
Landing zones and data processing
Once the data lands on the platform, you need to transform, stage, and curate it. The heavy lifting of data transformation is executed by tools like Dataproc (for Spark jobs) or Dataflow (for streaming jobs using Apache Beam). These environments are either serverless or fully managed, and, depending on your needs, will scale automatically and let you specify code-based data transformations that you need. You can isolate the data into different projects so that you can easily manage access permissions and follow the principle of least privilege. The orchestration of different steps of data transformation and movement should be done in tools like Cloud Composer (managed Airflow) or Cloud Workflows, giving your data pipelines lineage and auditability.

Security, governance, and monitoring
Government and highly regulated industries must pay extra attention to security. All data stored on Google Cloud is encrypted at rest and in transit, with options to use either Google-managed encryption keys — for less operation overhead — or your own keys if you prefer. Regardless, you should use a multi-layered approach to secure your data: setting up a VPC-SC perimeter around the projects of the platform will ensure all access meets your security requirements based on IP addresses, identities and/or trusted devices. Also, use Identity Aware Proxy to enable the operations teams with shell access to the relevant VMs. Enabling data access logs for resources containing sensitive data in Cloud Logging will give you full visibility and auditability on your platform. You can also leverage Cloud Monitoring to build alerts and notifications for unwanted events.
Finally, Dataplex lets you easily organize your data across lakes, zones and different tiers to let you implement your own governance framework. This organizational clarity, combined with many other security features such as centralized data retention policies, data lineage, data quality and data classification will let you further improve your security posture and the auditability of your platform.

Data publishing
Government organizations often want to share data with the public or other government departments. Because of this, your platform should allow your users to access data from other organizations, but also needs to allow other organizations to access the data you hold. This was our customer's challenge. For this, you’ll need to make data available while managing permissions across different data sources — all while keeping data owners in control, and not centralizing data management. That’s where Analytics Hub comes in: you can efficiently and securely curate a library of internal and external assets, letting you exchange data within and across organizations. Exchanges within Analytics Hub are private by default, but it’s easy to set granular roles and permissions so you can deliver data at scale to exactly the right users. This way, data publishers can easily view and manage subscriptions for all their shared datasets so they are in control of their data. Data subscribers get an opaque, read-only, linked dataset inside their project. With this blueprint you can create a true data-sharing exchange, and you can subscribe to other exchanges, giving your platform’s users secure access to multiple datasets from multiple sources.
Meanwhile, unstructured data can either be transformed at the time of ingestion (for example using Document AI to systematize and label data in documents), or it can reside in Cloud Storage and be given access via object tables in BigQuery.
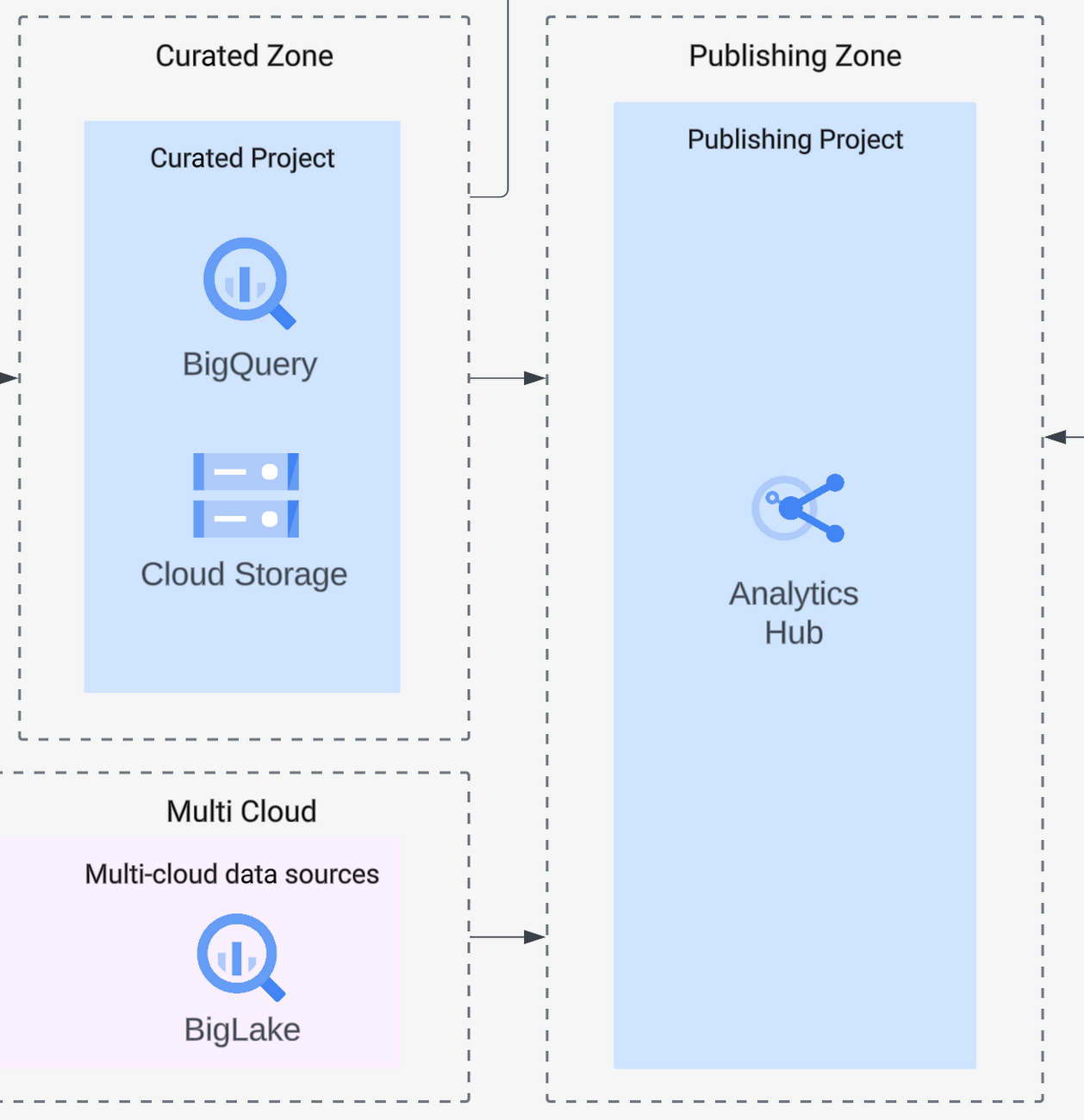
Analytics zone
The next things our customer’s analysts needed were tools to analyze and create value from the data they had access to. For visualization and insights, Looker connects to available datasets and lets business users explore data interactively with dashboards, with the option to drill down and investigate different views and facets of the data. For analysts, using BigQuery and its UI provides a simple interface to run powerful SQL queries and get answers to more complex questions quickly. Data scientists accessing the platform will want Vertex AI to develop machine learning models and investigate complex relationships in the data. Data scientists will be able to use Vertex AI Notebooks that are based on their familiar open-source Jupyter notebooks, access powerful accelerators like GPUs, and use Google’s AutoML capabilities to speed up development. Finally, developers can use Cloud Workstations as a fully customizable web-based IDE. These choices mean that your data platform will support all user types: from business users to data scientists and engineers.
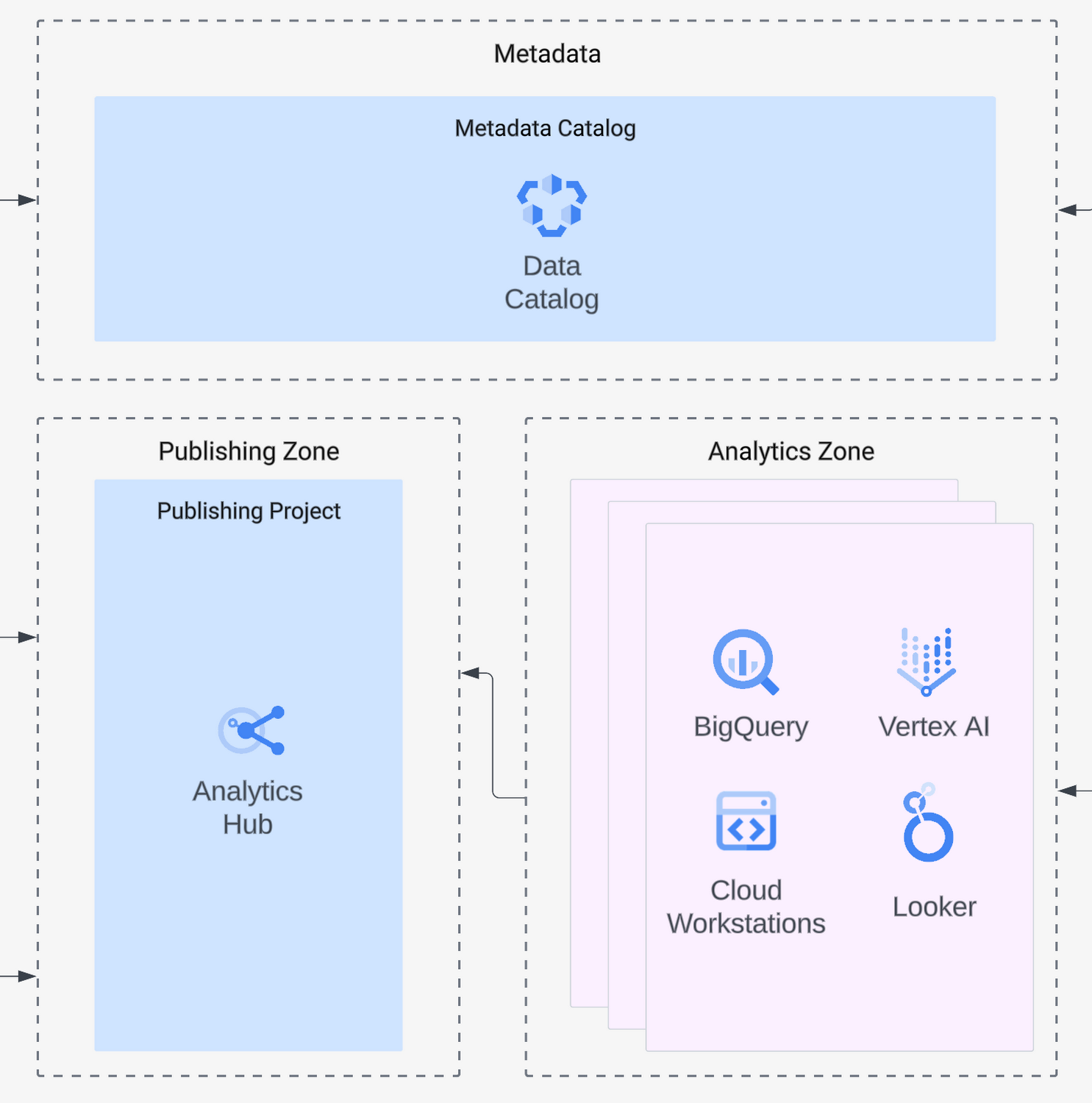
User and access management
Users will need to be assigned to groups that will govern their permissions. Cloud Identity and Access Management (IAM) ensure that only users that belong to the groups with the right permissions can access the data for which they are authorized, and can only perform the set of actions for which they are authorized with the analytical services.
At the same time, you should enforce multi-factor authentication (MFA) for all users on the platform. We recommend using hardware keys for MFA where possible, prioritizing the highly privileged users. BeyondCorp Enterprise features, meanwhile, let you control the access context for users to enforce a minimum level of security for the endpoint posture — for example, requiring an up-to-date operating system, or for the connection to be from an endpoint that is managed by your organization.
Get started with this blueprint
We have been working with many Public Sector customers wanting to break silos across government departments and reap the benefits of integrating data sources. This blueprint covers the major pillars of data analytics and sharing platforms: data ingestion, data staging and transformation, data publishing, analysis tools, security, and user access management.
To go more in depth, follow the Data Engineer and Cloud Architect Learning Paths, and consider getting the Professional Cloud Architect and Professional Data Engineer Certification. Finally, if you want our support to design architectures with you, talk to our Professional Services.
Sebastien and Filipe would like to thank Peter and Janos for helping to write and edit this post



