Advanced scheduling for AI/ML with Ray and Kueue
Andrew Sy Kim
Staff Software Engineer, Google
Kai-Hsun Chen
Software Engineer, Anyscale
Ray is an open-source unified compute framework gaining popularity among developers for its ability to easily scale AI/ML and Python applications. KubeRay offers a solution to harness the power of Ray within Google Kubernetes Engine (GKE). It serves as an orchestrator for Ray clusters, leveraging Kubernetes APIs as the foundational layer for compute, networking, and storage. KubeRay can also integrate with Kueue, a powerful cloud-native queueing system, unlocking advanced scheduling capabilities for Ray applications on GKE.
In this blog, we'll dive into how KubeRay and Kueue work together to orchestrate advanced scheduling for Ray applications. We'll explore techniques for:
- Priority scheduling: Prioritize AI/ML tasks to ensure production reliability and improve cost efficiency.
- Gang scheduling: Orchestrate the simultaneous execution of tightly coupled AI/ML tasks to maximize resource usage and accelerate training.
Priority scheduling
Scenario
A company hosts a variety of batch workloads on a GKE cluster, including continuous integration (CI) tests and offline batch inference tasks using RayJob for production purposes. Given that the cluster's resources are finite and must be shared among these applications, the company aims to ensure the swift completion of production workloads. Consequently, priority scheduling is employed, allowing production workloads to preempt resources from lower-priority tasks, such as CI tests.
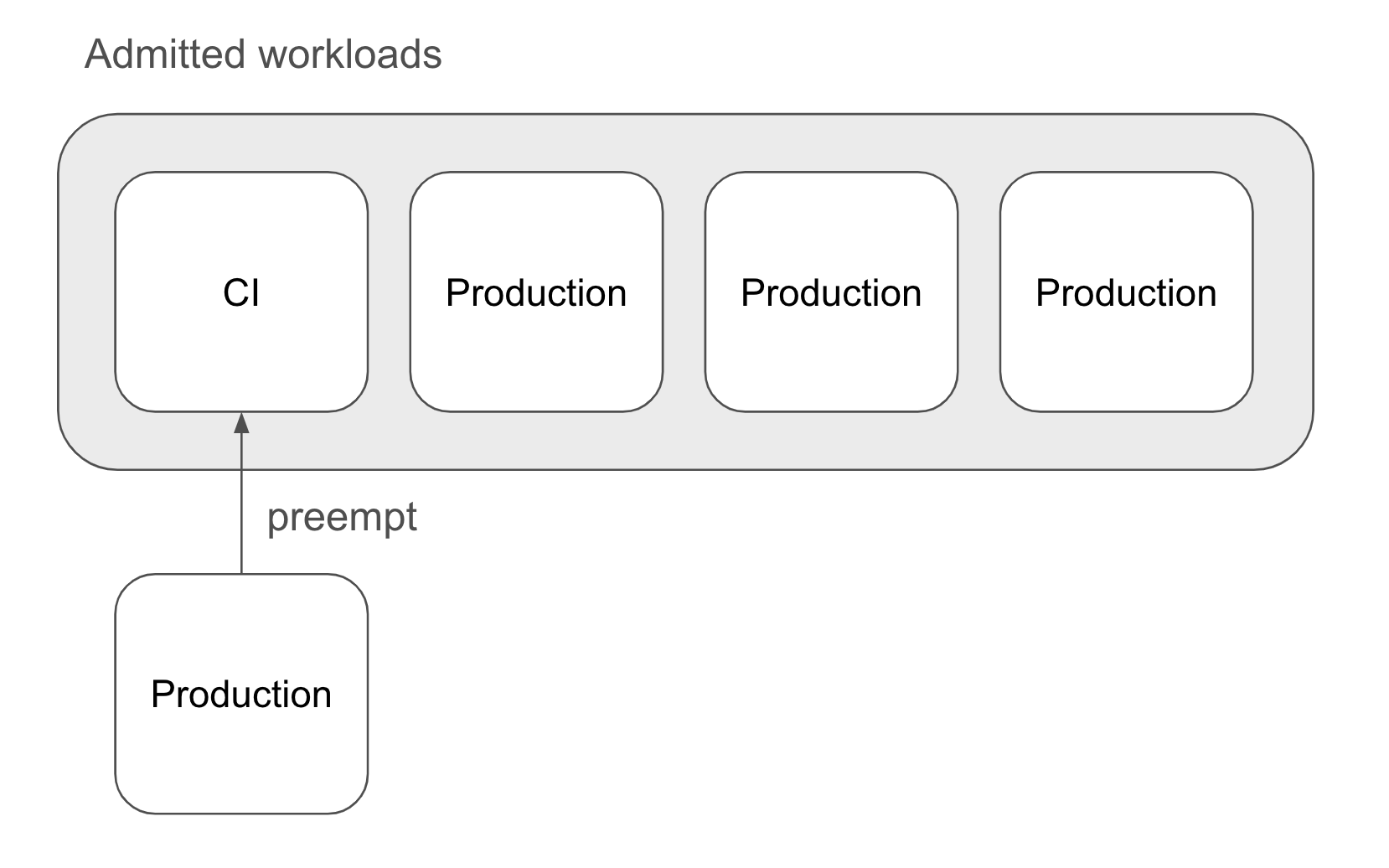
How do Kueue and KubeRay implement priority scheduling?
Kueue's WorkloadPriorityClass API provides the control necessary to prioritize RayJob and RayCluster resources within your GKE environment. Workload priority influences two key aspects. First, it determines the order of workloads in the ClusterQueue, with higher-priority workloads being executed earlier. Second, when there is insufficient quota in a ClusterQueue or its cohort, an incoming workload can trigger the preemption of previously admitted workloads, based on policies for the ClusterQueue. For RayJob and RayCluster, preemption involves deleting all Ray Pods and transitioning the custom resource status to ‘Suspended.’ When the ClusterQueue has enough resources later on, Kueue resumes the suspended workloads.
Priority scheduling is crucial for scenarios where production and development workloads compete for limited resources. By assigning higher priorities to production-related tasks, you enable preemption of less time-sensitive jobs, ensuring production models are updated and deployed in a timely manner.
Here’s an example of two WorkloadPriorityClass resources to distinguish between workloads for production and development:
You can then assign priority classes to KubeRay resources using Kueue’s priority class label:
See the Priority Scheduling with RayJob and Kueue guide for a full walk-through.
Gang scheduling
Scenario
Kueue's all-or-nothing approach to workload admission ensures that RayJobs and RayClusters are scheduled only when all required resources are available. This significantly improves resource efficiency by preventing partially provisioned clusters that are unable to execute tasks. This strategy, often termed "gang scheduling," is particularly valuable for the resource-intensive nature of AI/ML workloads.
Gang scheduling is important for use cases like data parallelism in distributed model training. Data parallelism shards data across multiple Pods, each running the same model. All gradients are sent to a parameter server, which updates the hyperparameters and then redistributes them to all Pods for the next iteration. If the RayJob or RayCluster is partially provisioned, the parameter server can't update the hyperparameters and will become stuck until the custom resource becomes fully provisioned. This results in a total waste of resources. Gang scheduling can effectively avoid this situation.
How do Kueue and KubeRay implement gang scheduling?
You can take advantage of Kueue’s dynamic resource provisioning and queueing to orchestrate gang scheduling with KubeRay. This is essential when working with limited hardware accelerators like GPUs and TPUs. Kueue ensures Ray workloads execute only when all required resources are available, preventing wasted GPU/TPU cycles and maximizing utilization.
Kueue achieves this efficient gang scheduling on GKE using the ProvisioningRequest API. This API signals that a Ray workload should wait until the necessary compute nodes can be provisioned simultaneously. GKE's cluster autoscaler accepts the ProvisioningRequest, scaling up nodes in one step, if and only if all required resources are available. Ray cluster Pods are then scheduled together on the newly provisioned nodes. Refer to How ProvisioningRequest Works for more details.
For a step-by-step demonstration, see the Gang Scheduling with RayJob and Kueue guide.
Conclusion
KubeRay and Kueue offer powerful tools for managing and optimizing Ray applications within GKE. Priority scheduling helps you ensure your most important AI/ML tasks always get the resources they need. Gang scheduling helps you make the most of hardware accelerators, preventing wasted time and maximizing efficiency. Together, these techniques improve the performance and cost-effectiveness of your Ray applications on the cloud
