The surprising economics of Horizontal Pod Autoscaling tuning
Roman Arcea
Product Manager, GKE
Marcin Maciejewski
GKE Product Manager
The Kubernetes Horizontal Pod Autoscaler (HPA) is a fundamental tool for managing the scalability and efficiency of your environment, working by deploying more Pods in response to increased load. However, achieving the best price-performance with HPA requires a nuanced understanding of its settings, particularly your CPU utilization targets. The common assumption that a 50% CPU target is a good starting point can actually lead to higher costs. In fact, the 50% HPA CPU target might require significantly more provisioned resources compared to a 70% target, with a marginal impact on performance. And sometimes, changing settings such as resource requests on Pods can actually deliver a better balance between cost, performance and agility.
In this blog, we explore why that is, so you can learn more about fundamental HPA optimization strategies for Google Kubernetes Engine (GKE).
The resource efficiency conundrum
On the surface, setting HPA at a 50% CPU utilization target seems like a safe way to ensure efficiency. However, it can lead to an imbalance between cost and performance. To illustrate this, we performed some synthetic workload tests based on common traffic patterns. We compared autoscaling with two CPU targets: 50% and 70%, as well as a second 70% HPA target scenario with modified Pod resource requests.
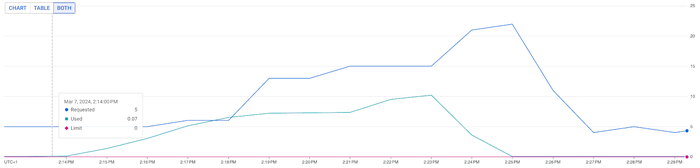
Scenario 1: 50% CPU HPA target and 1 CPU/pod resource requests
With a 50% CPU target and our applied traffic pattern, HPA scaled to 22 CPUs. This setup resulted in an average end-user response time of 293ms and a consistent P95 response time of 395ms.
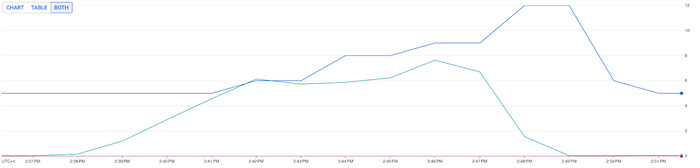
Scenario 2: 70% CPU HPA target and 1 CPU/pod resource requests
Conversely, with a CPU target of 70%, HPA only scaled to 12 CPUs under the same user load. This represents a significant 84% reduction in resources compared to a target of 50% CPU target on HPA. While there was a slight impact on end-user performance (average response time increased from 293ms to 360ms and P95 latency increased from 398ms to 750ms), this illustrates the potential trade-off between resource efficiency and performance.
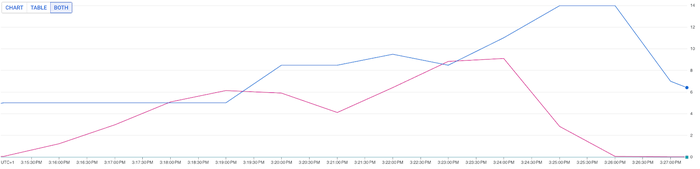
Scenario 3: 70% CPU HPA target and .5 CPU/Pod resource request
Setting the HPA CPU target isn’t the only tool you can use to balance cost and performance. You can also tune your Pod resource requests.
In a third test, we kept the 70% CPU HPA target, but instead of requesting a full 1 CPU per Pod, we set the value at 500 millicores, while doubling the idle state of pods from 5 to 10 pods to achieve the same starting point for benchmarking. This pushes the HPA algorithm to scale more aggressively from a broader baseline of pods.
This scenario did provision 14 CPUs instead of 12; however, it also delivered meaningful improvements to the end user experience, averaging 325 ms response time, compared to 398ms in the previous scenario, and 598ms for P95 responses compared to 750 ms.
Comparing the results
Let’s see how different scenarios are compared in our synthetic tests.
Note: Results are provided for conceptual understanding of HPA and resource request implications for optimization and do not represent any kind of benchmarking or guarantees.
Understanding the tradeoffs
When it comes to HPA optimization, there’s a delicate balance between efficiency and performance. The key lies in finding the optimal rate of CPU utilization vs. performance degradation on scale up (P95), which can be influenced by a combination of factors that are often beyond your control, including:
-
Frequency of metrics scraping: This can vary based on the metric type and vendor.
-
Traffic shape: How steep the traffic spikes are in your specific scenario.
-
Reactiveness of the workload: The linearity and speed with which a metric change (such as CPU utilization) manifests under increased load.
Gauging these factors is paramount, as there isn't a 'one-size-fits-all' approach. And it goes without saying that you should always carry out performance testing on your workload before implementing any strategy in a production environment.
As you can see from the scenarios above, a cost-effective approach is often to experiment with CPU targets like 70% or 80%. This offers several advantages, assuming your workload can tolerate the increased utilization:
-
Reduced costs: Having fewer pods directly translates to lower aggregate resource requests, minimizing your overall bill.
-
Acceptable burst handling: A higher target provides breathing room within existing Pods to accommodate traffic bursts, reducing the frequency and intensity of scaling events.
-
Potential for more optimization: Inversely, smaller Pods with higher utilization targets might perform better under load, which could also impact the HPA algorithm’s decisions, resulting in more effective scale-up.
Alternative HPA optimization strategies
The ultimate solution for optimizing your auto scaling strategy is a balanced approach that maximizes efficiency and performance. By combining different tactics, you can achieve optimal equilibrium for your specific workload. In addition to the above techniques, you should also consider:
-
Configuring scale-up and scale-down behaviors: Leverage HPA cooldown to preserve instances longer or scale them down faster. This helps maintain stability during traffic spikes and reduces unnecessary resource consumption. Learn more here: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#configurable-scaling-behavior
-
Scaling on external or custom metrics: For more granular control over HPA’s scaling decisions, you can tap into external or custom metrics alongside CPU or memory utilization metrics. This allows you to tailor autoscaling to your unique application requirements. A great example is to scale based on traffic using metrics from your load balancer. Here are some tips: https://cloud.google.com/kubernetes-engine/docs/concepts/traffic-management#traffic-based_autoscaling
Ultimately though, the key to successfully optimizing HPA behavior lies in understanding your workload’s profile and selecting the right node size through an iterative process that involves continuous testing, monitoring, and adjustments. This balanced approach is the best way to achieve efficiency, performance, and scalability for your GKE clusters.

