How Migrate for Anthos streamlines legacy Java app modernization
Ady Degany
Sr. Product Manager, Google Cloud
Tom Nikl
Senior Product Marketing Manager, Cloud Migration
Recently, we’ve been highlighting all the ways that Anthos, our hybrid and multi-cloud application platform, can help you modernize your Java applications and development and delivery processes. This week we’ll focus on how Migrate for Anthos, which takes your existing VM-based applications and intelligently converts them to run in containers on Google Kubernetes Engine (GKE), can also help you move your legacy Java applications.
Whether it’s to enable new functionality, decommission an on-premises data center, or to save on maintenance costs, many organizations are actively trying to modernize legacy Java applications—preferably by running them in containers on GKE and Anthos. Unfortunately, the way that some legacy applications acquire resource configuration and usage information is incompatible with standard-issue Kubernetes, and requires some complicated workarounds.
To help with this, the most recent release of Migrate for Anthos has a new feature to help streamline and simplify legacy application migration, automatically augmenting container resource visibility for legacy Linux-based applications, such as those that use Oracle Java SE 7 and 8 (prior to update 191). This is crucial if you want to successfully convert your legacy Java applications into containers without having to upgrade or refactor them.
Migrate for Anthos helps you successfully move Java applications into containers by transparently and automatically implementing a userspace filesystem that addresses the limitations of the Linux filesystem. As you probably know, Linux uses cgroups to enforce container resource allocations. However, a known issue when running in Kubernetes, is that the Kubernetes node’s procfs /proc file system is mounted by default in the container, and reflects host resources rather than those allocated to the container itself. And because some legacy applications still acquire resource configuration and usage information from files like meminfo and cpuinfo in the /proc directory, rather than from cgroups files, running those applications in a container can result in errors and instability. For example, older Java versions may use the information from meminfo and cpuinfo to determine how much memory to allocate to its JVM heap, how many threads to run in parallel for garbage collection (GC), etc. Running an older Java application in a container that hasn’t been properly configured can result in processes being killed due to out-of-memory errors, which can be difficult to triage and troubleshoot.
For legacy applications for which you cannot upgrade Java versions, Migrate for Anthos takes a common approach used in the community: it implements the LXCFS filesystem. It does this without requiring user intervention, special configuration or application rebuild. Our goal is to help you migrate all your applications—not just the easy ones—quickly and effectively, so you can make progress on your modernization goals.
The sample legacy Java web application
Let’s take a look at the difference in behaviors of a legacy Java application migrated with and without Migrate for Anthos.
For this test, we’re using a JBOSS 8.2.1 server using an older version of Oracle Java SE 7 update 80. You can download this version from Oracle’s Java SE 7 Archives. We package it in two ways: as a regular Docker container image, and as a server VM from which we have migrated the application to a container using Migrate for Anthos.
For the application, we use a sample JBoss node-info application with some additional lines of code to simulate memory pressure for each request served. The following modifications were applied:
src/main/java/pl/goldmann/work/helloworld/NodeInfoServlet.java
Testing the application on GKE
When deploying the two application containers, we apply the following resource restrictions in the GKE Pod spec, allocating 1 vCPU and 1 GiB of RAM, on a GKE node that has 4 vCPU and 16 GiB of RAM:
We then run the two application instances. First let’s check basic application output by directing a web browser to the application URL.
Here’s what happens on the standard container:
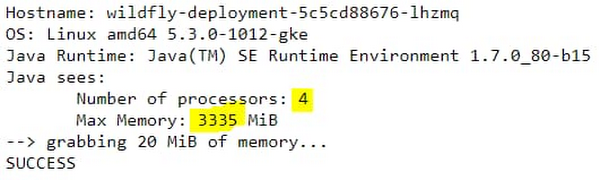
But here’s what happens on the Migrate for Anthos migrated container:
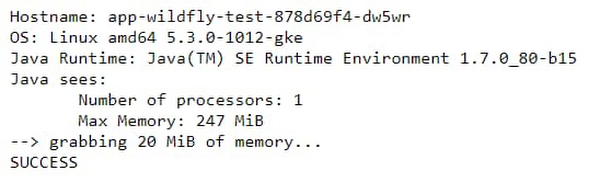
You can immediately see a difference between the results. In the standard container, as already reported in many such tests, Java reports resource values from the host node, and not from the container resource allocations. In the standard container, the reported maximum heap size is derived from Java 7's sizing algorithm, which, by default, is one quarter of the host’s physical memory. However, in this case of the Migrate for Anthos migrated container, the values are reported correctly.
You can see a similar impact when querying the Java Garbage Collection (GC) threading plan. Connect to shell, and run:
java -XX:+PrintFlagsFinal -version | grep ParallelGCThreads
On the standard container, you get:
uintx ParallelGCThreads = 4 {product}
But on the migrated workload container, you get:
uintx ParallelGCThreads = 0 {product}
So here as well, you see the correct concurrency from the Migrate for Anthos container, but not in the standard container.
Now let’s see the impact of these differences under load. We generate application load using Hey. For example, the following command generates application load for two minutes, with a request concurrency of 50:
./hey_linux_amd64 -z 2m http://##.###.###.###:8080/node-info/
Here are the test results with the standard container:
Status code distribution: [200] 332 responses [404] 8343 responsesError distribution: [29] Get http://##.###.###.###:8080/node-info/: EOF [10116] Get http://##.###.###.###:8080/node-info/: dial tcp ##.###.###.###:8080: connect: connection refused [91] Get http://##.###.###.###:8080/node-info/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers
This is a clear indication that the service is not handling the load correctly, and indeed when inspecting the container logs, we see multiple occurrences of
*** JBossAS process (79) received KILL signal ***
This is due to an out-of-memory (OOM) error. The Kubernetes deployment took care of automatically restarting the OOM-killed container, during which time the service was unavailable. The reason for this is a miscalculated Java heap size from considering the host resources, instead of the container resource constraints. When not calculated right, Java tries to allocate more memory than available and therefore gets killed, disrupting the app.
In contrast, executing the same load test on the container migrated with Migrate for Anthos results in:
Status code distribution:
[200] 1676 responses
[202] 76 responses
This indicates the application handled the load successfully even when memory pressure was high.
Unlock the power of containers for your legacy apps
We showed how Migrate for Anthos automatically augments a known container resource visibility issue in Kubernetes. This helps ensure that legacy applications that run on older Java versions behave correctly after being migrated, without having to manually tune or reconfigure them to fit dynamic constraints applied through the Kubernetes Pod specs. We also demonstrated how the legacy application remains stable and responsive under memory load, without experiencing errors or restarts.
With this feature, Migrate for Anthos can help you harness the benefits of containerization and container orchestration with Kubernetes, to modernize your operations and management of legacy applications. You’ll be able to leverage the power of CI/CD with image-based management, non-disruptive rolling updates, and unified policy and application performance management across cloud native and legacy applications, without requiring access to source code or application rewrite.
For more information, see our original release blog that outlines support for day-two operations and more or fill out this form for more info (please mention ‘Migrate for Anthos’ in the comment box).


