GKE Stateful High Availability (HA) Controller now in GA
Peter Schuurman
Software Engineer, Google
Akshay Ram
Senior Product Manager
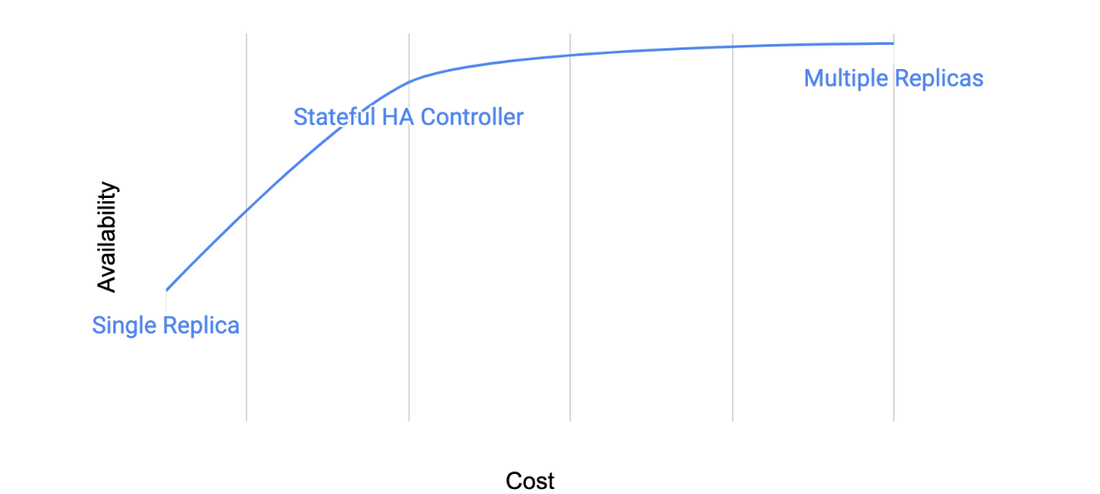
Designing for application requirements is a key business consideration for any production application on Google Kubernetes Engine (GKE). This is especially true for stateful applications, e.g., databases and message queues. But running stateful applications often means choosing between cost and availability. For instance, you can run a single replica application in a single zone, minimizing costs but trading off on availability. Or if you need higher availability, you can run multiple application replicas, providing data redundancy in the event of a node failure — but you pay for that redundancy in terms of compute and network infrastructure.
Furthermore, in Kubernetes, during disruption events (e.g., upgrades, zone failure), the scheduler follows an eventually consistent approach. While this works for stateless applications, customers are looking for a more proactive approach for stateful applications. They want to control failover time and have visibility into how stateful applications behave during disruption events.
Customers want a middle ground: the availability of multiple replicas, with the cost efficiency of a single replica application. To help, today we’re announcing Stateful HA Operator on GKE, a new feature that brings proactive scheduling to stateful applications while balancing cost and availability.
Let’s take a closer look at how Stateful HA Operator can help you balance availability and cost for your stateful apps.
Getting to know Stateful HA Operator
At a high level, Stateful HA Operator provides proactive controls to stateful applications, and increases availability through its integration with regional persistent disk (RePD).
Many low-cost availability tools offer failover that is eventually consistent, where the failover process takes approximately 10 minutes. This is too long if you want to achieve an industry gold-standard Recovery Time Objective (RTO) of 60-120 seconds. Stateful HA Operator reduces this lag and lets you customize your failover response on a per workload level, so failover times match business requirements. You also have full observability so you can audit and track any failover activity.
The use of regional persistent disks, meanwhile, introduces a new option in the cost vs availability spectrum. Regional persistent disk is a storage option that provides synchronous replication of data between two zones in a region. Since adding additional storage is generally cheaper than running additional compute, and because RePD does not charge for cross-zone networking fees, you can balance cost and availability. Pairing the Stateful HA Operator with Spare Capacity or PriorityClass provides your application available compute capacity to fail over to in the event of a total failure.
Diagram 1. Stateful HA conceptual cost vs availability representation
|
Single Replica (Zonal Storage) |
Multi-Replica |
Stateful HA (Single Zone, Regional Storage) |
|
|
Automated recovery from node failure |
Y |
Y |
Y |
|
Automated recovery from zone failure |
N |
Y *(depending on configuration) |
Y |
|
Application recovery time from disaster |
Hours |
Seconds |
Minutes (configurable: You can control the speed of pod failover and the available failover compute capacity in your cluster by using PriorityClass or Spare Capacity) |
|
Cost |
$ |
$$$ (multiple compute replicas, cross-zone networking costs) |
$$ (optional additional compute replica, increased cost for regional storage) (compute cost trade-off of cost vs. availability, storage/network trade-off based on application characteristics) |
|
Tolerance to data loss* |
Data loss, for the duration of a zonal outage |
No data loss |
No data loss |
* Data loss means unrecoverable loss of data committed to persistent storage. Any non-committed data is still lost.
Case studies
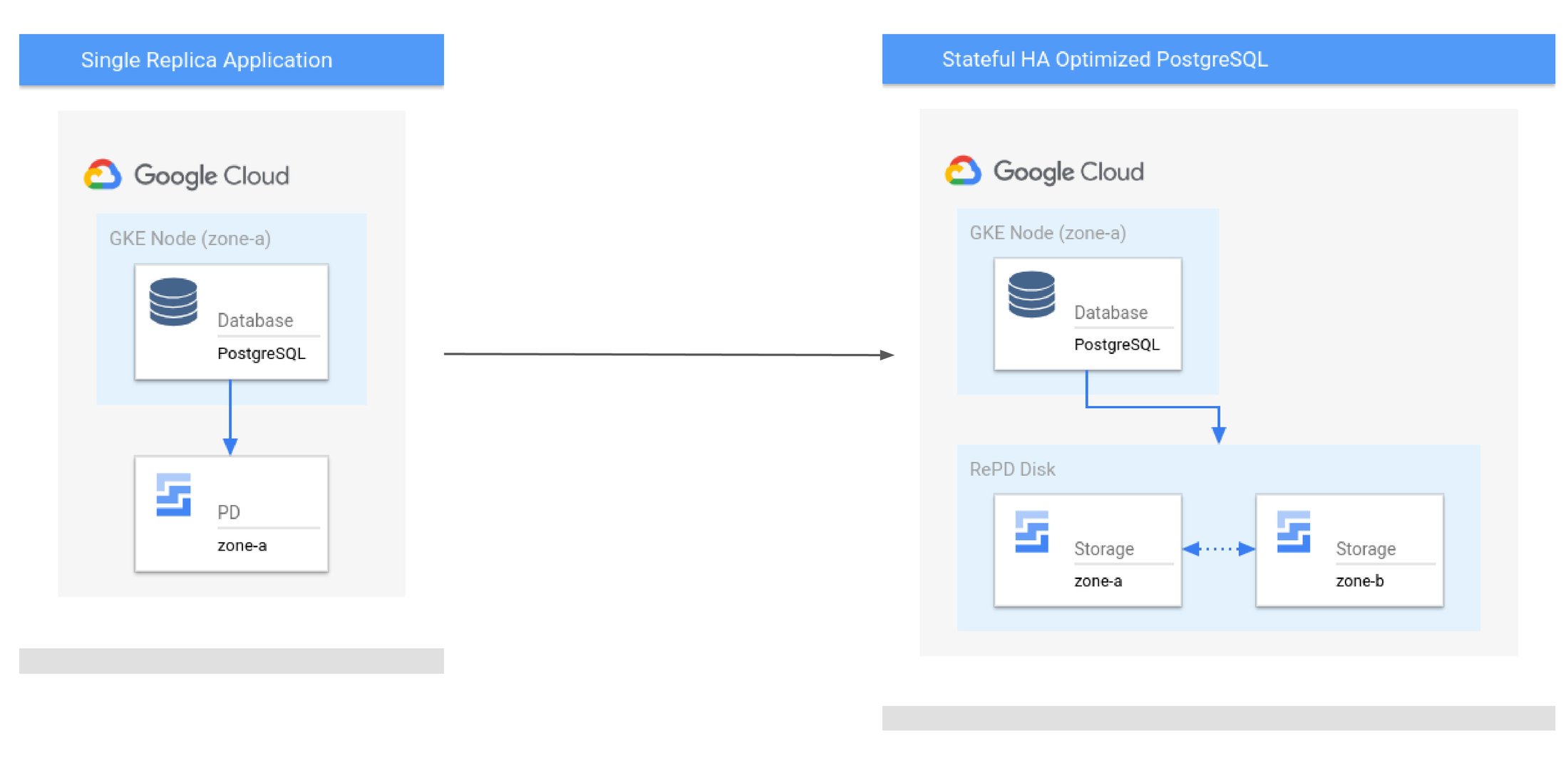
Use case 1: Upgrading availability for a single-replica PostgreSQL only at an 8% increase in cost
Consider a standard highly available single replica PostgreSQL application* with a total list price of $391/ month. Single replica applications are subject to disruptions and RTO can be hours to days.
By enabling the Stateful HA Controller and allowing it to orchestrate failover with Regional PD, you can add tolerance to disruptions such as zonal failures for a marginal increase of 8%. Stateful HA Operator reschedules your replica within a preconfigured timeout, allowing you to minimize the unavailability window of your application to fit its SLA, at a very attractive cost point. If you need even more availability, you can also add failover compute capacity.
Diagram 2. Convert a single replica Postgres app to GKE StatefulHA Optimized infra
|
Standard PostgreSQL (1-replica) |
Stateful HA (1-replica, regional replicated Storage) |
|
|
Compute Costs |
$391.35 |
$391.35 |
|
Storage Costs |
$44 |
$78 |
|
Network Costs |
$0 |
$0 |
|
Recovery Time Objective |
Hours *(Depends on the period of zonal unavailability) |
Minutes |
|
Total Cost |
$435 |
$469 |
|
Additional Cost |
- |
8% |
*Pricing assumes 3x e2-standard-16 VM shape, 200 GiB pd-ssd storage requirement, 6 MiBps ingress. See here for Standard PostgreSQL (1-replica) and Stateful HA (1-replica, regional replicated Storage) configuration and pricing assumptions.
Use case 2: Reducing costs for a multi-replica Kafka with cost savings up to 53%
Some applications need to maintain a high RTO in the event of node failures, but inter-zone application replication introduces additional compute and storage costs. In the unlikely event of a zone failure, all replicas can be rescheduled from the primary to the secondary zone. This allows the application to optimize savings on inter-zone networking costs under normal operation.
Kafka was designed for running across a flat network. Depending on data replication costs, some applications see that inter-zone data replication can exceed over 80% of total application costs, significantly outweighing the cost of both compute and storage. Kafka can operate on the same principle of zonal isolation. Consider a 6-replica Kafka application. Spreading all Kafka brokers evenly across zones results in a total list price of $3,969.54 per month. By enabling the Stateful HA Controller, you can reduce the costs by up to 53%.
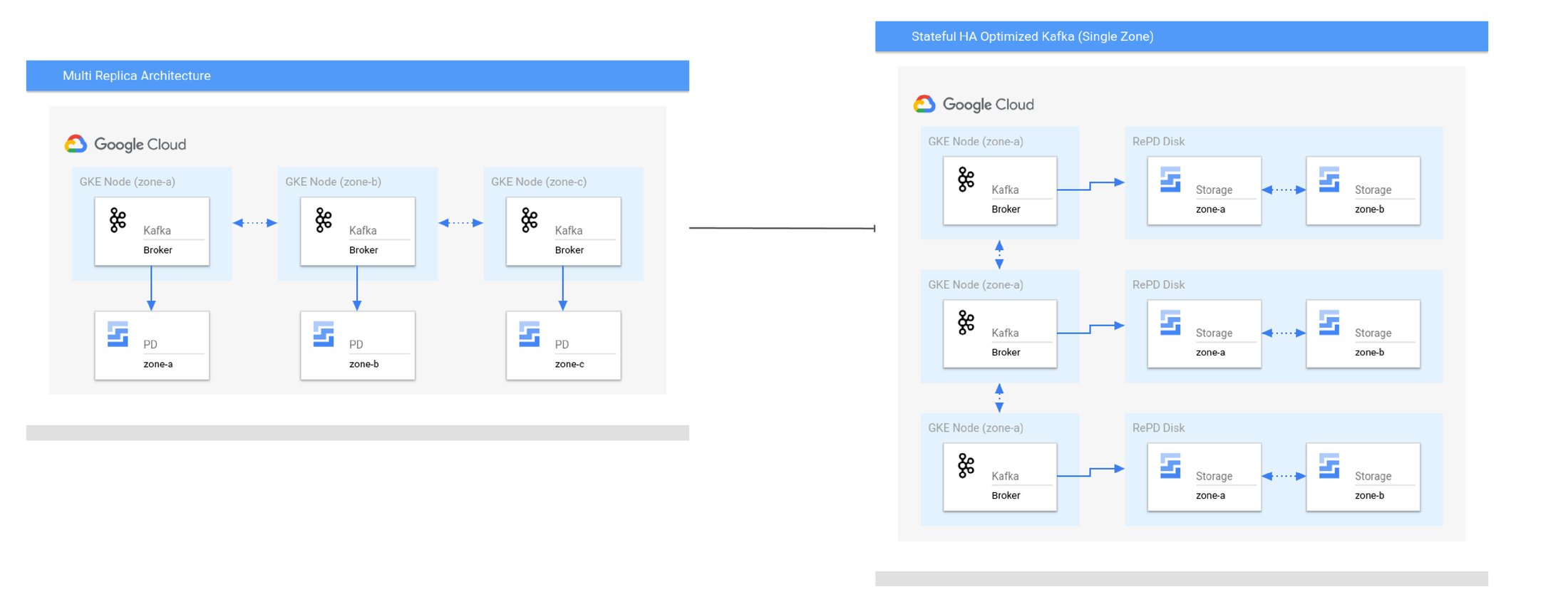
Diagram 3. Convert a multi-replica Kafka app to Stateful HA Optimized
|
Standard Kafka (3 zone) |
Stateful HA Kafka (1 zone) |
|
|
Compute Costs |
$1,174.04 |
$1,174.04 |
|
Storage Costs |
$360 |
$660 |
|
Network Costs |
$2,362.50 |
$0 |
|
Recovery Time Objective |
Milliseconds |
Minutes |
|
Total Cost |
$3,896 |
$1834 |
|
Cost Reduction |
- |
53% |
*Pricing assumes 6x e2-standard-16 VM shape, 500 GiB pd-balanced storage requirement, 20 MiBps ingress. See here for Standard Kafka (3 zone) and Stateful HA Kafka (1 zone) configurations and pricing assumptions.
Try the GKE Stateful HA Operator
The Stateful HA Operator is a fully automated solution that reduces the toil of customizing your application to meet its availability needs.It’s available now to try out. To enable and use it in your GKE cluster, you can follow the instructions in the documentation.



