Filestore Enterprise Multishares for GKE now generally available
Saikat Roychowdhury
Senior Software Engineer
Akshay Ram
Group Product Manager, GKE
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
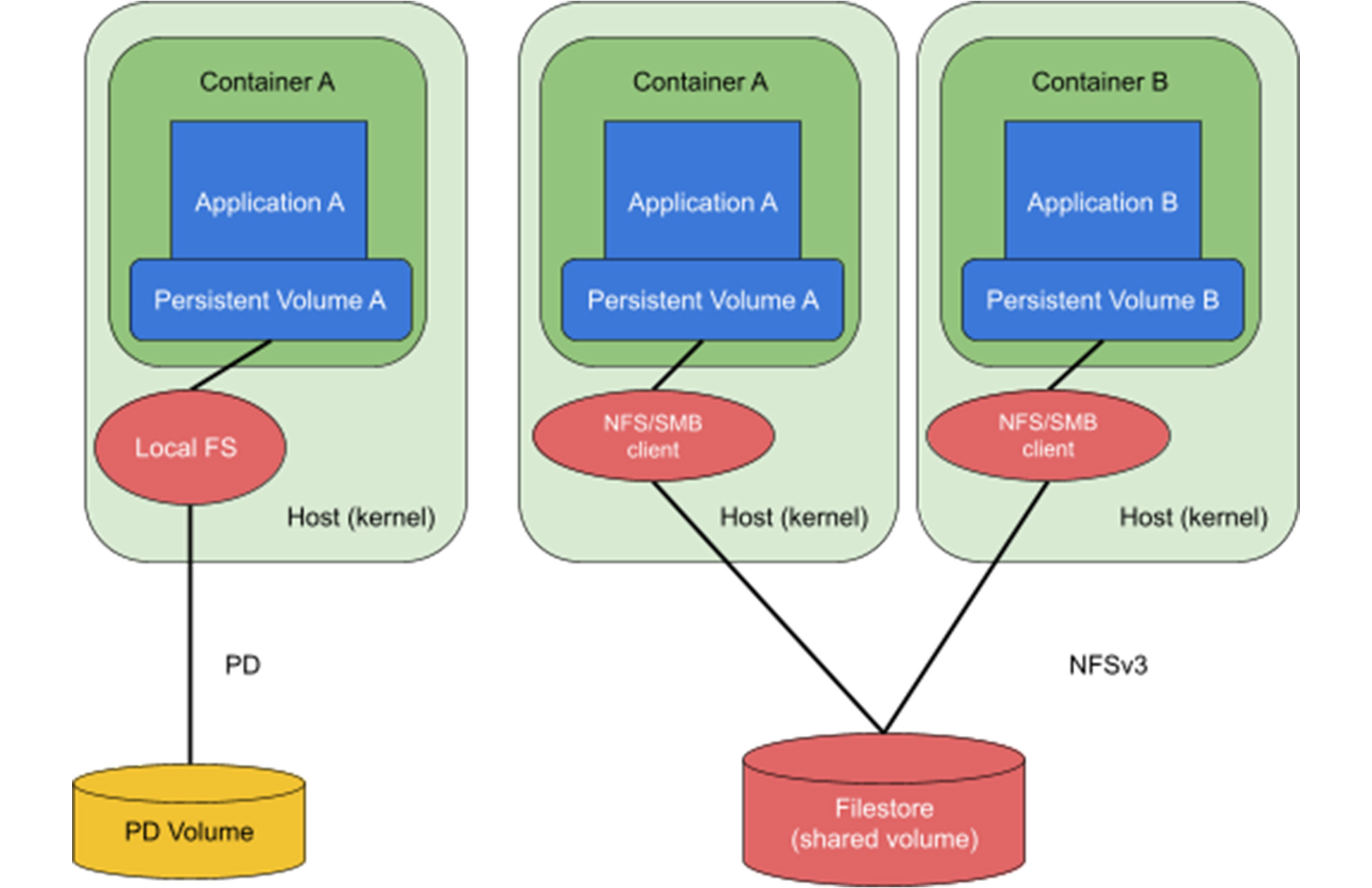
Free trialWhen setting up storage for your Google Kubernetes Engine (GKE) environment, customers can choose between block storage (Persistent Disk, or PD) or file storage (Filestore Enterprise). While both storage types are fully supported with containers on GKE including operations such as migrating containers across hosts for use cases such as upgrades or failover, Filestore Enterprise requires very little expertise on behalf of the customer to operate, especially during a failover
At Storage Spotlight, we introduced Filestore Enterprise multishare for use with GKE Autopilot and Standard clusters, and today, that feature is generally available. In this blog post, we look at considerations for choosing block vs. file in a GKE environment, and how to use the new Filestore Enterprise multishare feature.
Block vs. file storage considerations
When you choose block-based Persistent Disk, you get best-in-class price/performance with extensive selection of multiple PD types, making it popular with many GKE customers. However, with PD, customers need to have expertise in storage systems. When using PD, the file system logic is in the host. This coupling means that during migrations, the host must cleanly shut down the container, unmount the file system, reattach the PD to the target host, and mount the file system. Only then can it boot the container. While GKE manages a lot of these operations automatically, in the case of failover there are potential file system and disk corruption issues. Users will need to run some cleanup processes (“fsck”) on the mounted volume before it can be used.
Contrast that with Filestore Enterprise, which provides a fully managed regional file system that is decoupled from the host, and which does not need you to perform any infrastructure operations to attach/detach volumes. In addition, you also benefit from storage that can be simultaneously read to and written by multiple (hundreds to thousands) containers. That’s why Filestore Enterprise is popular across a variety of use cases: multiple developers accessing data e.g. JupyterHub; content management systems such as Wordpress, Drupal, IBM FileNet; interactive SaaS applications e.g., project or process management tools; and cases where multiple users read and write and analytics applications that consume multiple files e.g., genomic processing.
Optimizing storage utilization with Filestore Enterprise multishare
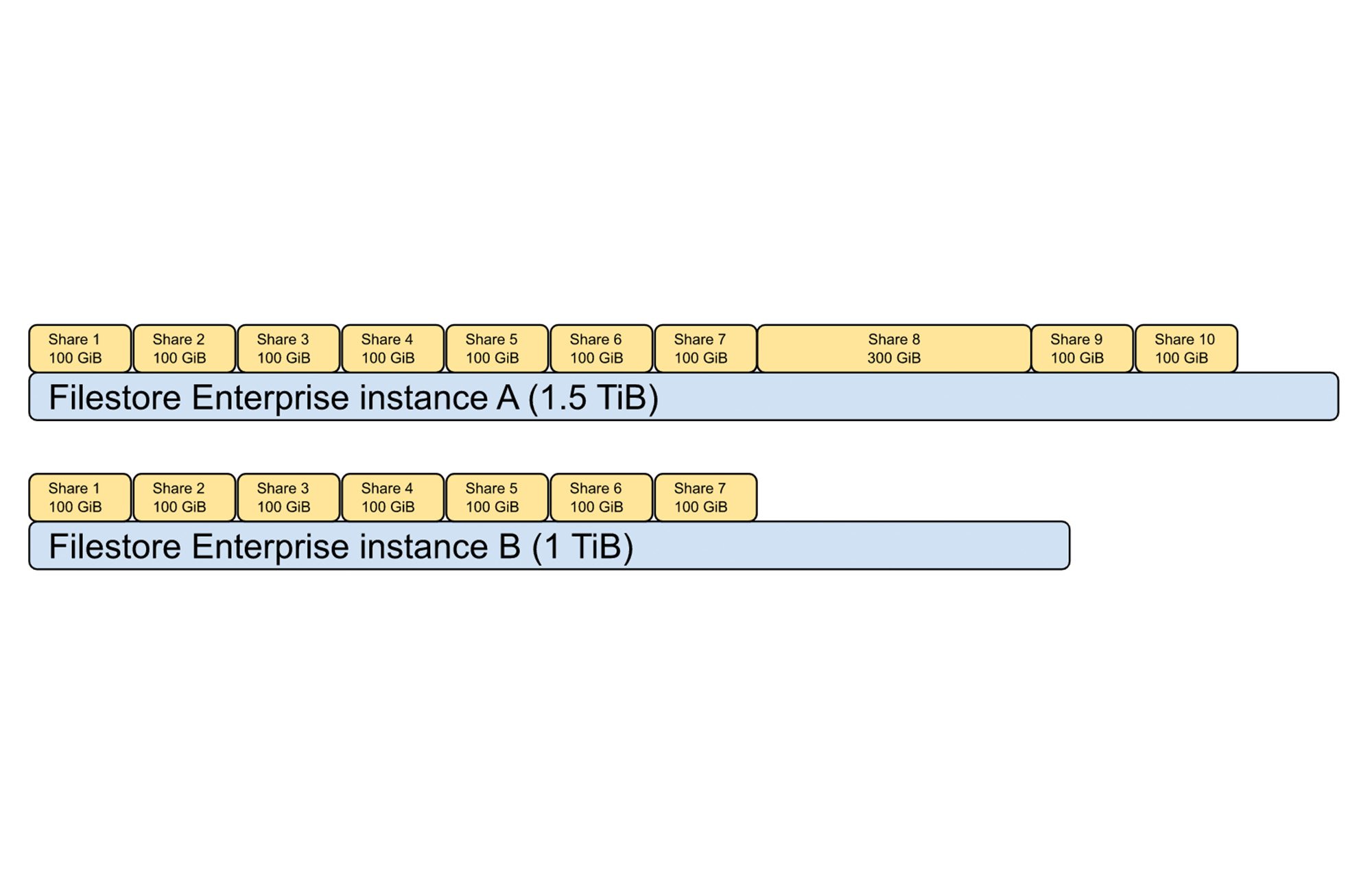
The introduction of Filestore Enterprise multishare for use with your GKE Autopilot and Standard clusters makes using Filestore even more compelling. Filestore has been available to use with the Container Storage Interface (CSI) driver with a 1TB starting capacity. Customers wanted to bin pack volumes on Filestore instances like they do with containers on GKE nodes, and were using directories to drive better utilization of Filestore instances. However, this solution is not seamless and lacks enterprise features such as capacity isolation, observability per volume, and support for CMEK. Filestore multishare support for GKE brings the best of both worlds: the granular resource sizing that Kubernetes customers are used to along with the dependability of Filestore Enterprise. Just like how containers are bin-packed on a node for better efficiency, multiple persistent volumes can be packed on a Filestore Enterprise instance to increase storage utilization and decrease costs. Additionally, Filestore multishare saves network resources by sharing network elements such as IP addresses across multiple shares and thus enhancing the application scalability.
You can provision Persistent Volumes (PVs) ranging from 100 GiB up to 1TiB on a Filestore instance. GKE seamlessly manages all related resources. Further, as shown in Figure 1, when you request storage via the kubernetes Persistent Volume Claim (PVC), underneath the hood, the GKE Filestore CSI driver seamlessly bin-packs volume requests on Filestore Enterprise instances and also creates new Filestore instances once space on a particular instance runs out. As the volumes are deleted, the GKE Filestore CSI driver seamlessly shrinks or deletes the underlying Filestore instances.
“Filestore Enterprise gives us a regional storage system that is decoupled from compute and works well with containers on GKE. Now with Multishare, we can optimize our usage to drive better cost efficiency,” said Ajay Kemparaj, Mandiant. “This feature has now tipped our decision to make Filestore Enterprise our default storage solution on GKE.”
Deployment and configuration considerations
If you decide to use the new Filestore multishare capability, here are a few things to keep in mind:
Noisy neighbors: Enabling shares allows you to reuse space of the underlying Filestore instance to save on costs. However, it also means that you share performance resources such as IOPS and throughput.
Trust boundary: Since all storage requests (via PVCs) that use Filestore multishare can be packed on the same underlying Filestore instance, we recommend that PVCs share the same trust boundary. If you need stronger isolation (e.g., you are requesting storage from two different customers and want to keep the data isolated), we recommend using Filestore single-share instances (where each PV maps to a unique filestore instance), which is also supported on GKE with CSI dynamic provisioning.
Regional availability: Filestore Enterprise is a regional service and delivers 99.99% availability SLA. Consequently, you can deploy GKE clusters across three zones within a region and all clusters have access to the same Filestore NFS share. This deployment architecture provides protection from a zonal outage, as all Filestore Enterprise data is synchronously replicated across three zones.
Getting started
Filestore Enterprise multishare is provisioned using standard Container Storage Interface semantics including dynamic provisioning. To see a detailed example on how two Kubernetes deployments with persistent volumes share an underlying Filestore Enterprise instance see the user guide.

