Cutting costs with Google Kubernetes Engine: using the cluster autoscaler and Preemptible VMs
Myroslav Rys
Solution Architect, SoftServe Inc.
[Editor’s note: SoftServe is a digital consulting firm and a Google Cloud partner that uses Google Kubernetes Engine extensively with its clients. Today, solution architect Myroslav Rys shares how he gets the most bang for his clients’ GKE buck.]
Kubernetes is the world’s most popular container orchestration tool. This open-source system provides a common platform for deploying containerized applications across hybrid-cloud environments. And if you choose a managed version like Google Kubernetes Engine (GKE), you don’t even need to configure the cluster itself—the cloud provider does it for you
GKE is a flexible, mature platform to deploy almost any type or size of business application—from new and native microservices to enterprise Java-based solutions. At SoftServe, we’ve been using it extensively for more than three years, and have found it to be an effective way to decrease operational expenses (OPEX) for our workloads. In particular, we’ve had a lot of success using the GKE cluster autoscaler, and Preemptible VMs. Let’s take a closer look.
Autoscaling your groups
Here’s a familiar scenario: Company X decides to re-architect a clunky in-house booking and reporting application by moving to Google Cloud Platform (GCP). It replaces the old Windows desktop application with a new, shiny Node.js front-end service, keeping all the heavy business logic in old core Java enterprise applications. But as a result, both front-end and back-end reporting suffers from the huge load at the end of the day, slowing performance.
You could create a Kubernetes node pool with enough nodes to support the load. But most of the time these resources will just sit there and cost you money.
Google has a solution for this: GKE's cluster autoscaler automatically resizes clusters based on the demands of selected workloads. With autoscaling enabled, GKE automatically adds a new node to your cluster if a newly created pod lacks the capacity to run. Conversely, if a node in your cluster is underutilized and its pod can be run on other nodes, GKE will delete it.
The best solution is to separate static application load and dynamic high-spike load. Simply use two or more GKE node pools: a static node pool for the static load, and a static/dynamic node pool with a cluster autoscaling group for the dynamic load.
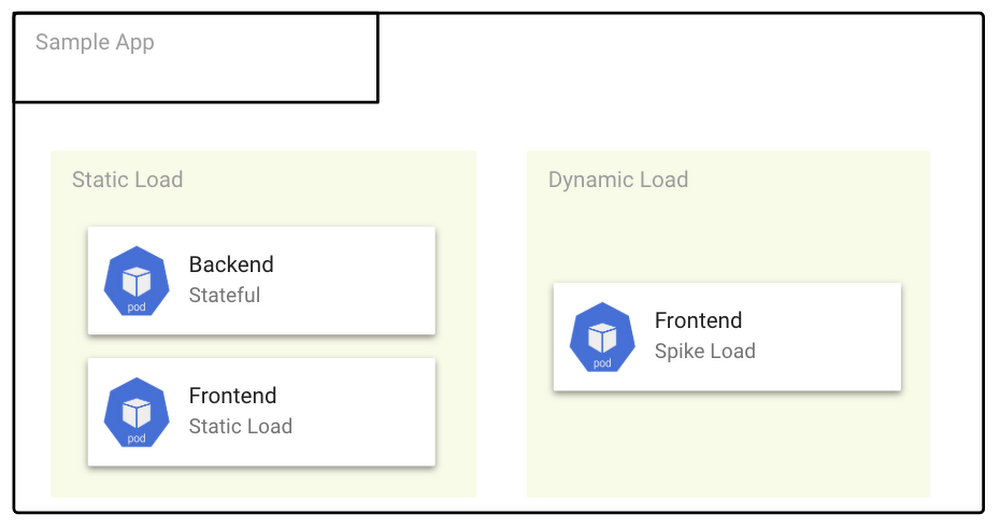
GKE autoscaling groups are very flexible. The autoscaler periodically checks whether there are any pods that need to be scheduled or are waiting for a node with available resources. With autoscaling groups, it’s easy to balance across zones, and set autoscaling limits via minimum and maximum Node Pool sizes.
You can manage all this easily from the GCP Console, gcloud CLI, or GCP REST API. In fact, check out how easy it is to create a GKE cluster with autoscaling:
We use GKE autoscaling groups all the time, and wonder how we ever got by without them!
Using Preemptible VMs and Kubernetes node pools
Once you’ve set up your infrastructure to scale cost-effectively, it’s time to look at another big consumer of compute time and power: collecting data and reports for business analytics. GCP has a solution for keeping costs down when running, identifying trends, patterns, and relationships: Preemptible VMs.
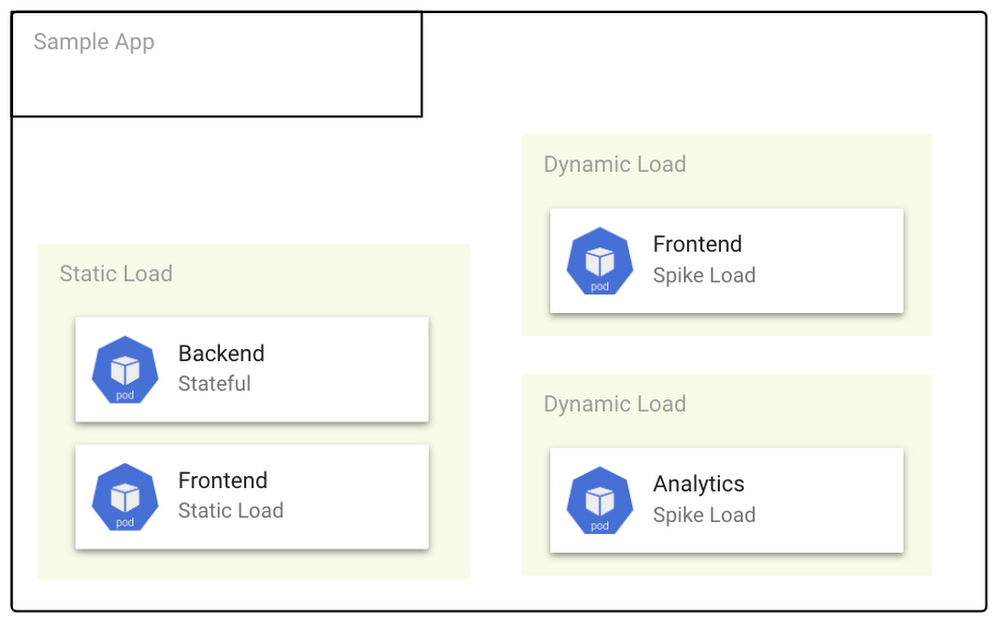
A preemptible VM (PVM) is an instance you can create and run at a much lower price than normal instances. Preemptible VMs are affordable, short-lived compute instances suitable for batch jobs and fault-tolerant workloads. Preemptible VMs offer the same machine types and options as regular compute instances and last for up to 24 hours.
Here at SoftServe, we use preemptible VMs for Kubernetes node pools. Here’s how to create and deploy preemptible node pool:
You can also schedule a workload on a preemptible node pool and manage it with Kubernetes Deployment configurations.
Then, to control pod scheduling, we use the Kubernetes node affinity feature, which gives us hard and soft preferences for scheduling pods. We use hard preferences to ensure that a particular pod won’t ever be scheduled on a preemptible node. Simply add the following lines to your pod or deployment spec:
Soft preferences, by contrast, just give Kubernetes your scheduling preferences.
Here’s an example of how to modify your pod or deployment spec with PreferredDuringSchedulingIgnoreDuringExecution to tell Kubernetes to run workload on a preemptible node pool if preemptible VMs are available:Here’s what the deployment schema for a Multi-Zone Default Node Pool / Multi-Zone Preemptible node pool usually looks like:
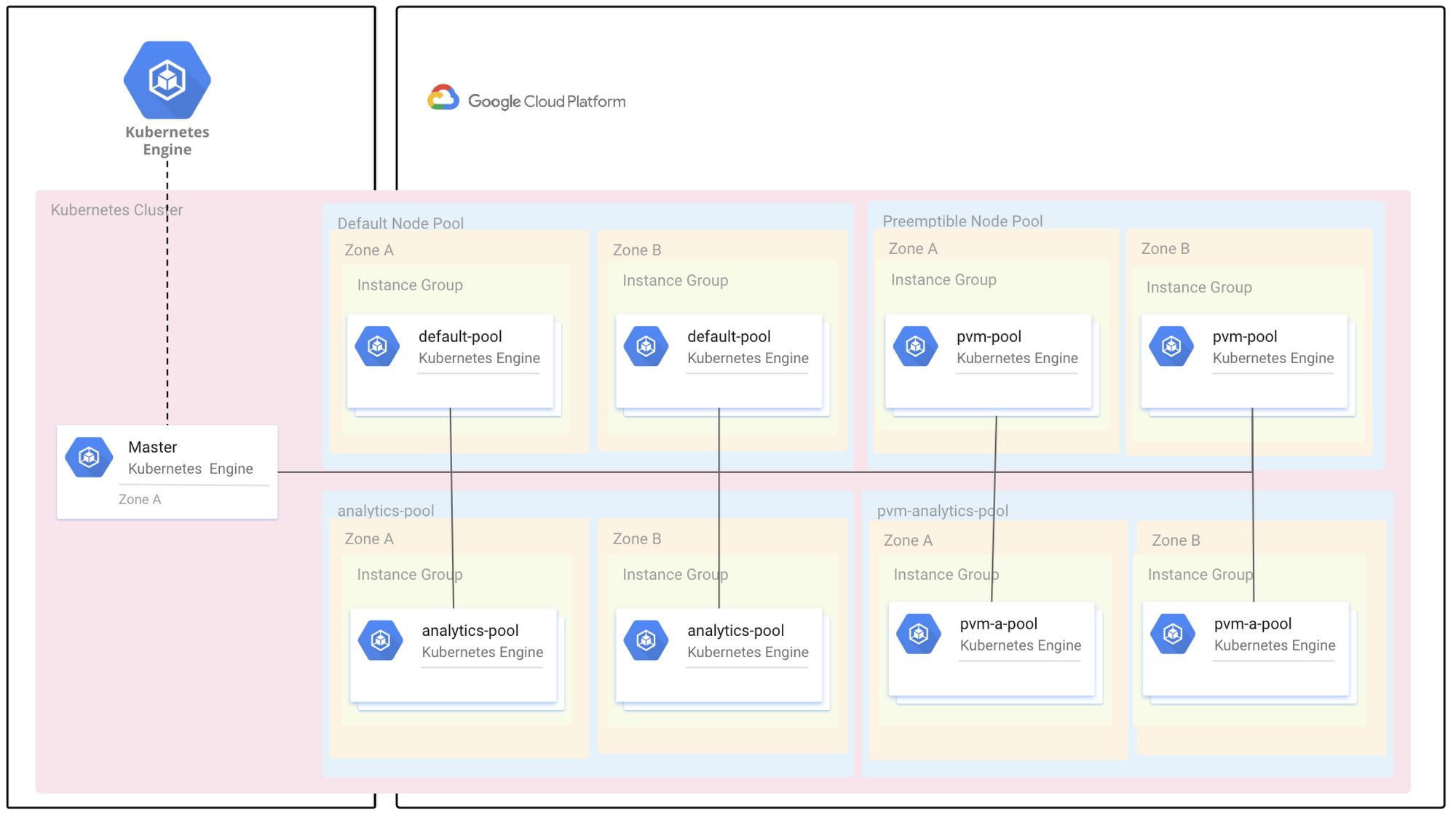
GKE’s autoscaler is very smart and always tries to first scale the node pool with cheaper VMs. In this case, it scales up the preemptible node pool. The GKE autoscaler then scales up the default node pool—but only if no preemptible VMs are available.
This schema explains in detail how the GKE autoscaler works:
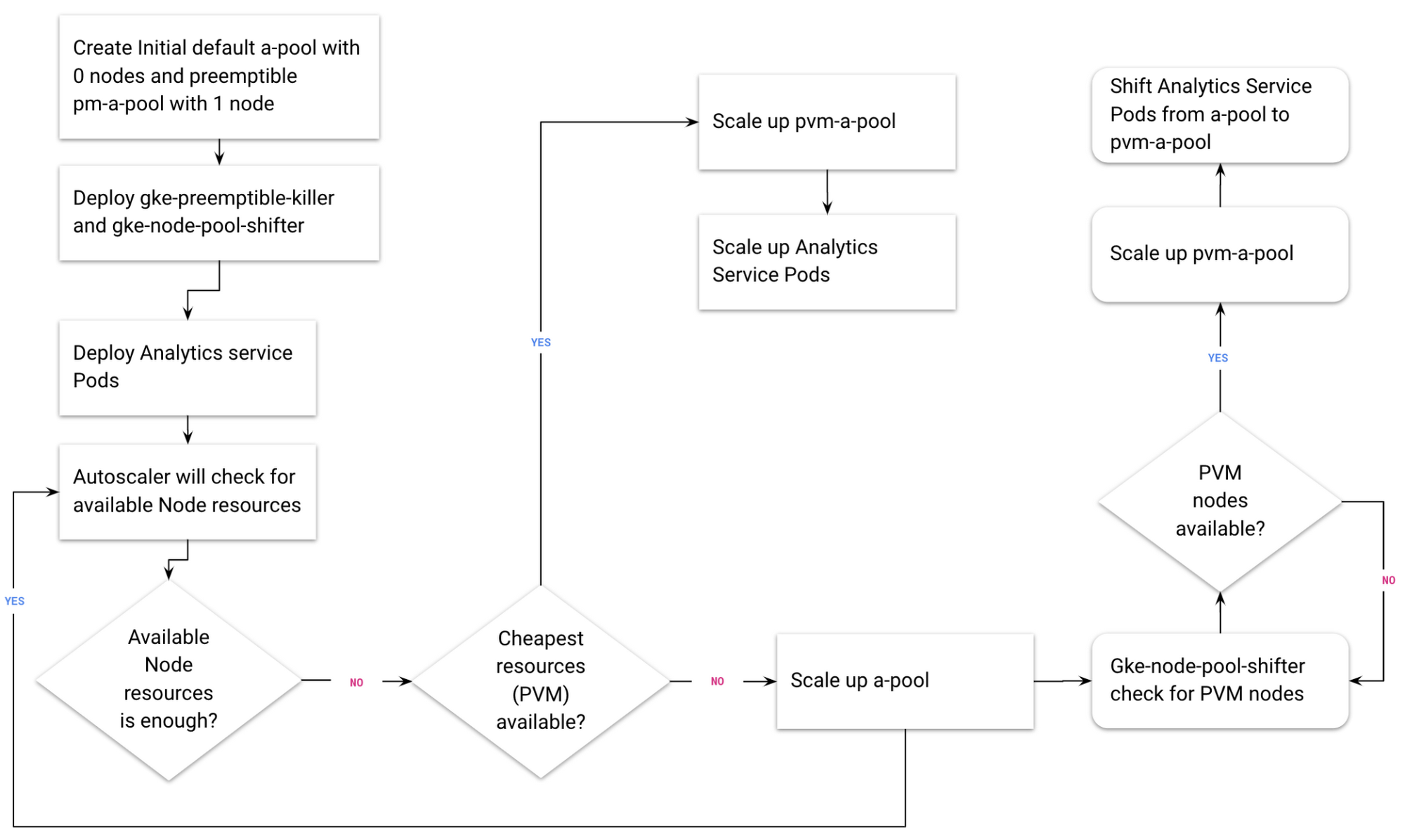
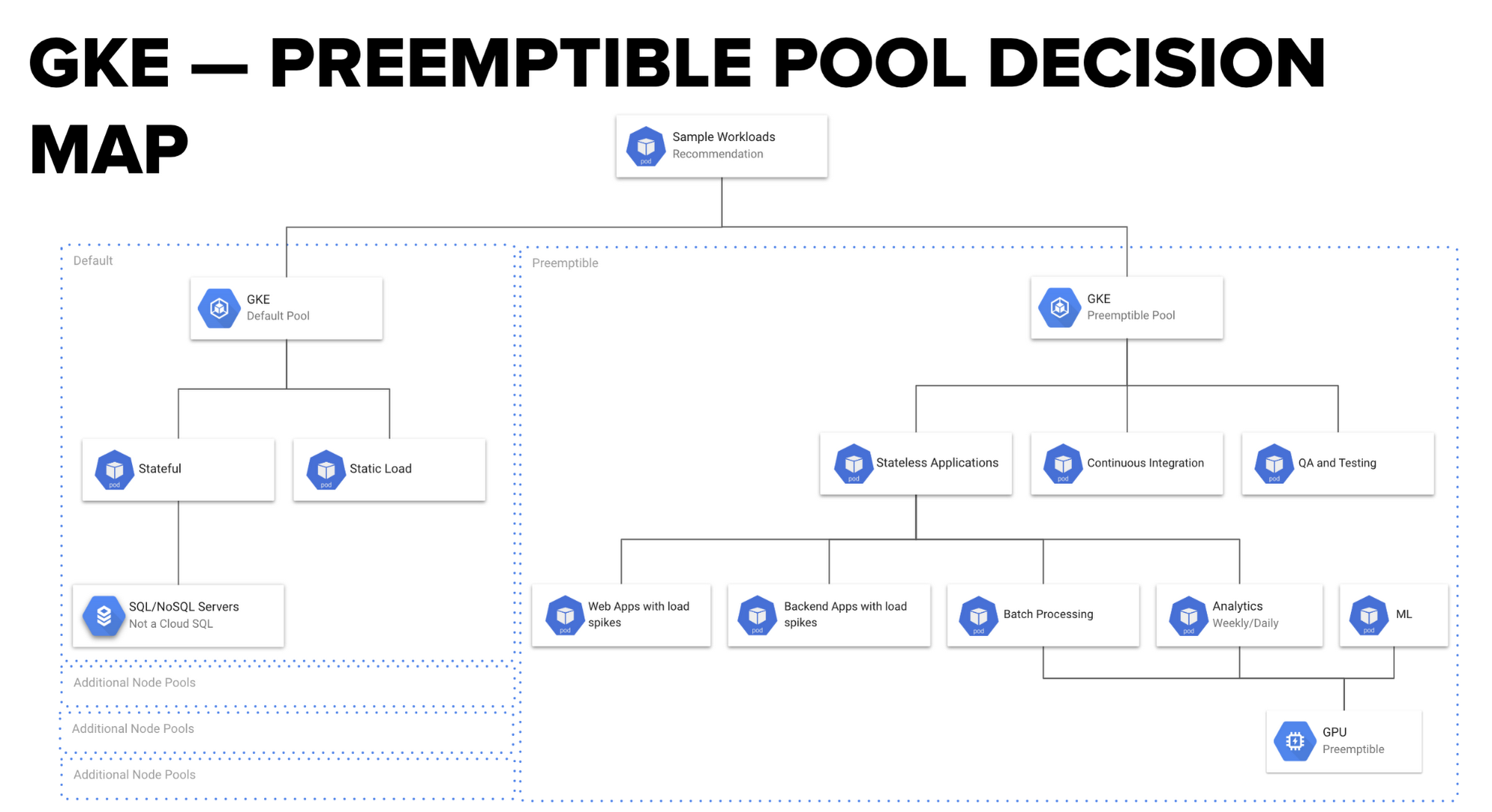
Using Kubernetes preemptible pools: tricks of the trade
There’s one thing to note: GKE preemptible pools are not a fit for all workloads. Your application should be able to tolerate unexpected pod failures.
Here’s a flowchart to help you to decide whether your workload is suitable for a GKE preemptible pool
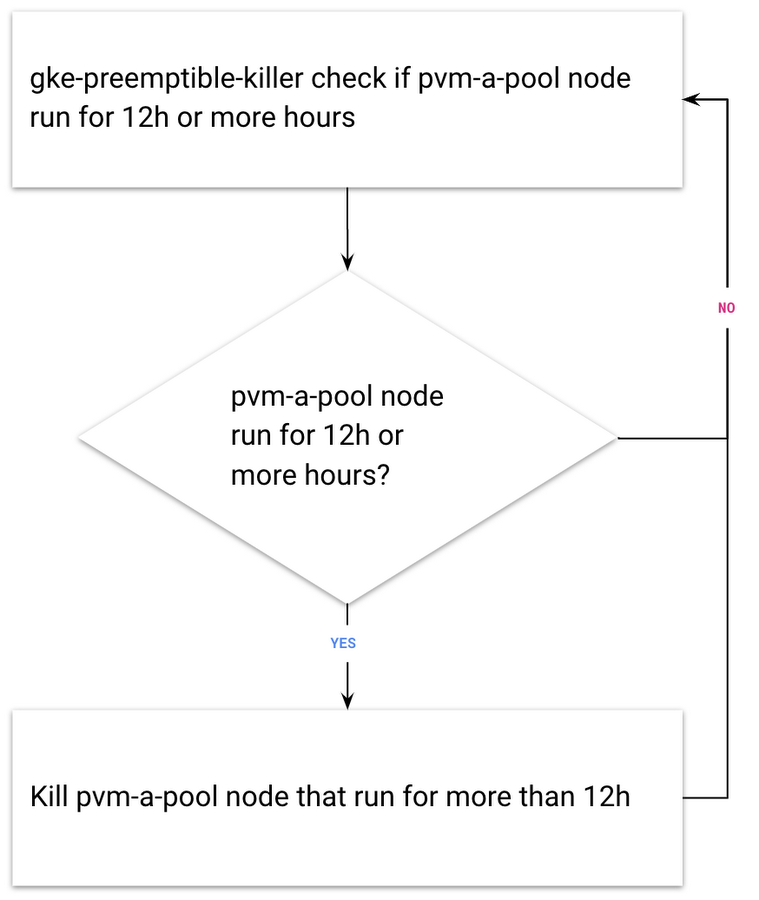
An important consideration is the fact that preemptible VMs last a maximum of 24 hours. After 24 hours, preemptible VMs will be released, and if you created all the nodes in your GKE preemptible node pool at the same time, then all the nodes will be released at the same time. One solution for this problem is Estafette CI’s great open-source solution: the Estafette GKE Preemptible Killer, a Kubernetes controller that ensures that the deletion of preemptible nodes in a GKE cluster is spread out, avoiding the risk that they’re all deleted at the same time after 24 hours.
Another great Estafette tool we recommend is the Estafette GKE Node Pool Shifter, to monitor node pools and move nodes to preemptible PVMs.
But wait! There’s more!
Cluster autoscaler and preemptible VMs are only two examples of how to make your Kubernetes cloud solution more cost-effective. Earlier this year, Google Cloud announced that you can now attach GPUs to preemptible VMs on Google Compute Engine as well as GKE, lowering the price of using GPUs by 50%, and providing a powerful, cost-effective and flexible environment for enterprise-grade machine learning, academic research, and VR/AR visualization.
At SoftServe, our experts are always discussing and discovering different ways to optimize our GKE deployments. Interested in joining the conversation? Join one of our upcoming Machine Learning meet-ups! We're touring Europe throughout the fall and winter—catch us at a meet-up near you.
