Building geo-distributed applications on GKE with YugabyteDB
Denis Magda
Director, Developer Relations, Yugabyte
Often, it is challenging to choose a single cloud region for application deployment. Imagine deploying your app on the US West Coast, only to discover several months later that most of your users experience high latency because they are located on the US East Coast and in Europe. Alternatively, consider the scenario where user data must be stored in and served from specific cloud regions to comply with data residency requirements, even when users are traveling and using your app abroad.
Google Cloud Platform’s infrastructure spans distant areas, countries, and continents. This infrastructure allows you to build geo-distributed applications that run across multiple availability zones, regions, or private data centers to ensure high availability, performance, and compliance.
The same infrastructure supports running YugabyteDB, a distributed database built on PostgreSQL, in any configuration necessary for a geo-distributed application. Depending on the application requirements, YugabyteDB can store data close to the user to comply with data regulatory requirements and minimize latency, as well as scale up and out, and withstand various outages.
Overall, geo-distributed apps offer several advantages. They can:
Serve user requests with low latency from nearly anywhere in the world
Withstand all sorts of outages
Comply with data regulatory requirements when expanding to new territories
The need for geo-distributed applications using Google Kubernetes Engine and YugabyteDB is coming up across a range of industry verticals and use cases. A few examples are covered below:
Streaming & Media: Streaming and media companies face regular “peak events” where they need to support a massive increase in the number of users registering or signing in. Imagine having to support the sudden rush of logins before the World Cup or Super Bowl. One of the fastest growing streaming companies in the U.S., adopted YugabyteDB to help support their geo-distributed application for user authorization by enabling rapid scaling across regions as needed thanks to YugabyteDB and the underlying Google Cloud services.
Financial Services: Examples of common distributed applications include payment processing, debt collections, and identity management. For example, a leading financial services firm for their containerized payment applications uses YugabyteDB to provide resilience against a zone or region failure and to help minimize latencies for users around the world.
Retail: Essential retail applications that are increasingly being modernized to help with a global reach include product catalogs and inventory management. With users able to make purchases from anywhere, a top 3 global retailer turned to YugabyteDB to help scale their product catalog to hundreds of millions of items and deliver fast access to shoppers anywhere. Another key benefit was the ability to have strongly consistent inventory data across regions. This allowed them to instantly identify out of stock items, saving them millions a year in fulfilling orders made after an item was out of stock.
One specific customer example is Justuno, a SaaS company that has been around since 2011 delivering the onsite messaging and popup lead capture needs of tens of thousands of websites, helping retailers and others accelerate visitor conversion rates. To power their next generation platform, Justuno turned to Google Cloud and YugabyteDB as key technologies to deliver a modern, distributed and highly-available data platform.
At Justuno, Google Cloud with YugabyteDB form a perfect combination to help us easily scale our applications across cloud availability zones and regions. The joint solution makes it extremely easy to build and maintain applications that comply with data regulatory requirements, expand to serve a global customer base, and maintain 24x7 availability.
Travis Logan, CTO, Justuno
This article demonstrates how to build a geo-distributed application on Google Kubernetes Engine (GKE) with YugabyteDB, using a geo-messenger app as an example.
The architecture of geo-distributed applications
The building blocks of a geo-distributed app are similar to a regular app that functions within a single availability zone. Like regular apps, geo-distributed apps are frequently deployed in Kubernetes, communicate via API gateways, and keep user data in databases.
But, there is one distinguishing characteristic. All the components of a geo-distributed application have to be distributed. This allows the app to span distant locations and scale horizontally.
Let’s review the essential building blocks of geo-distributed apps by looking into the architecture of the geo-messenger:
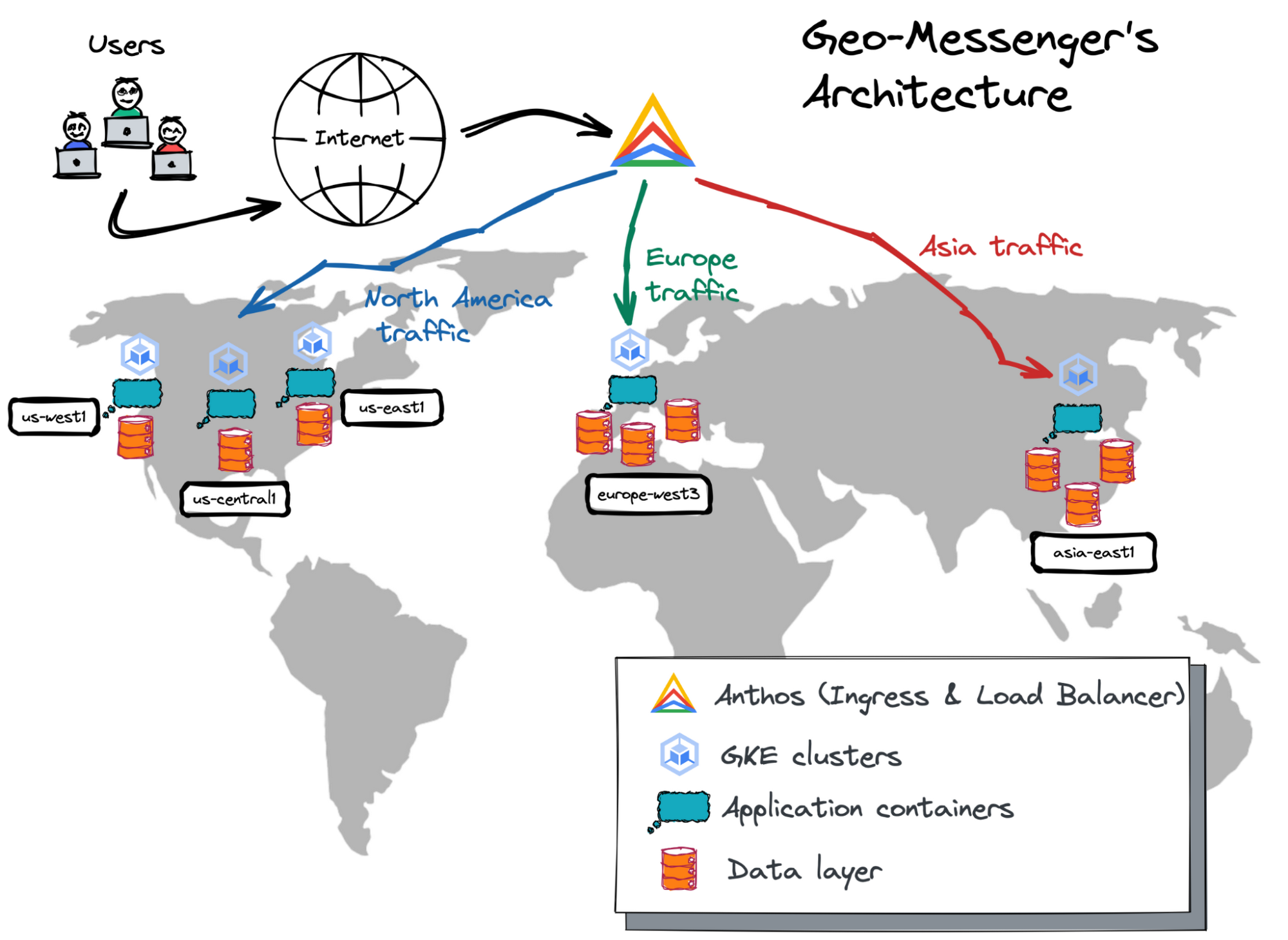
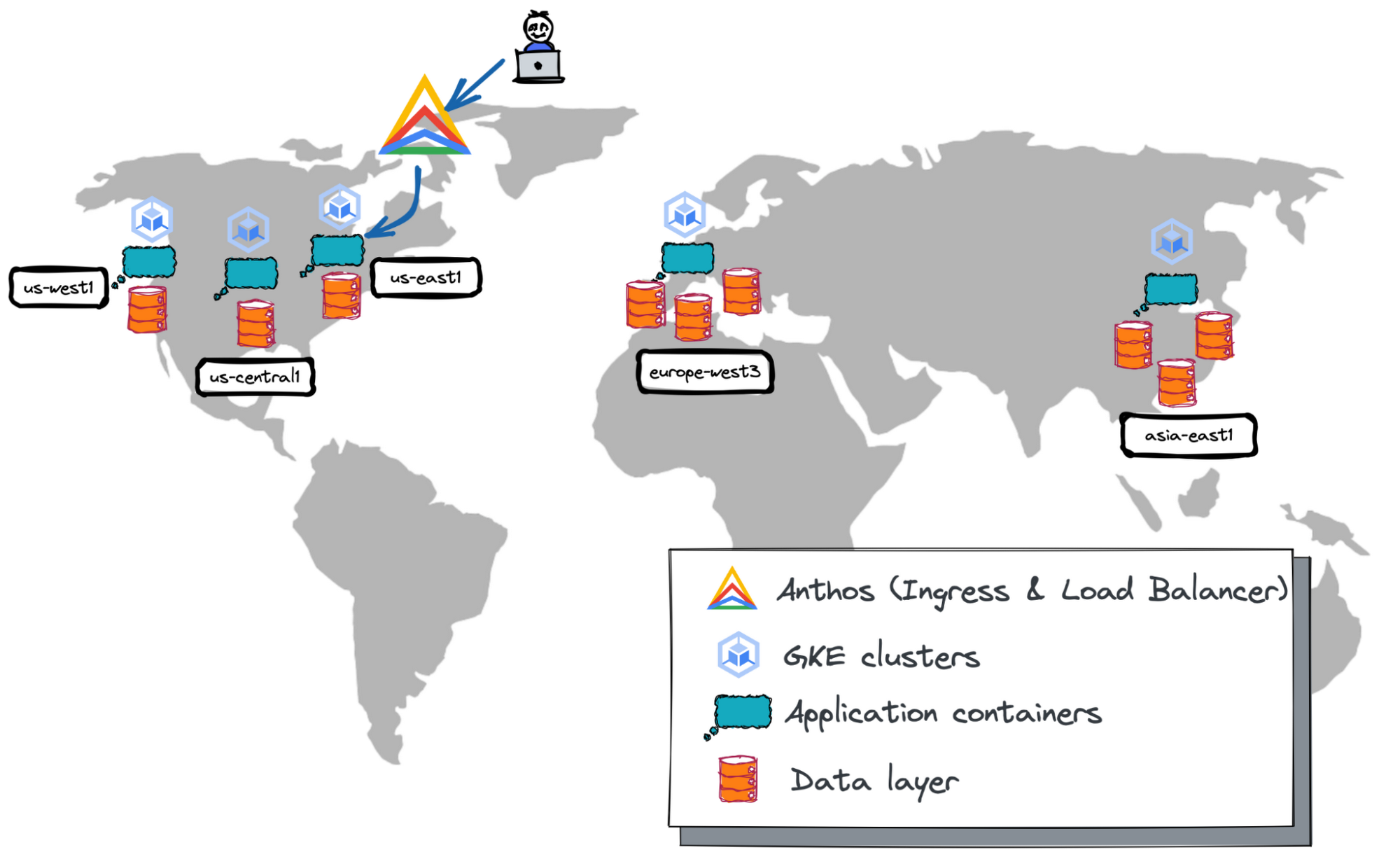
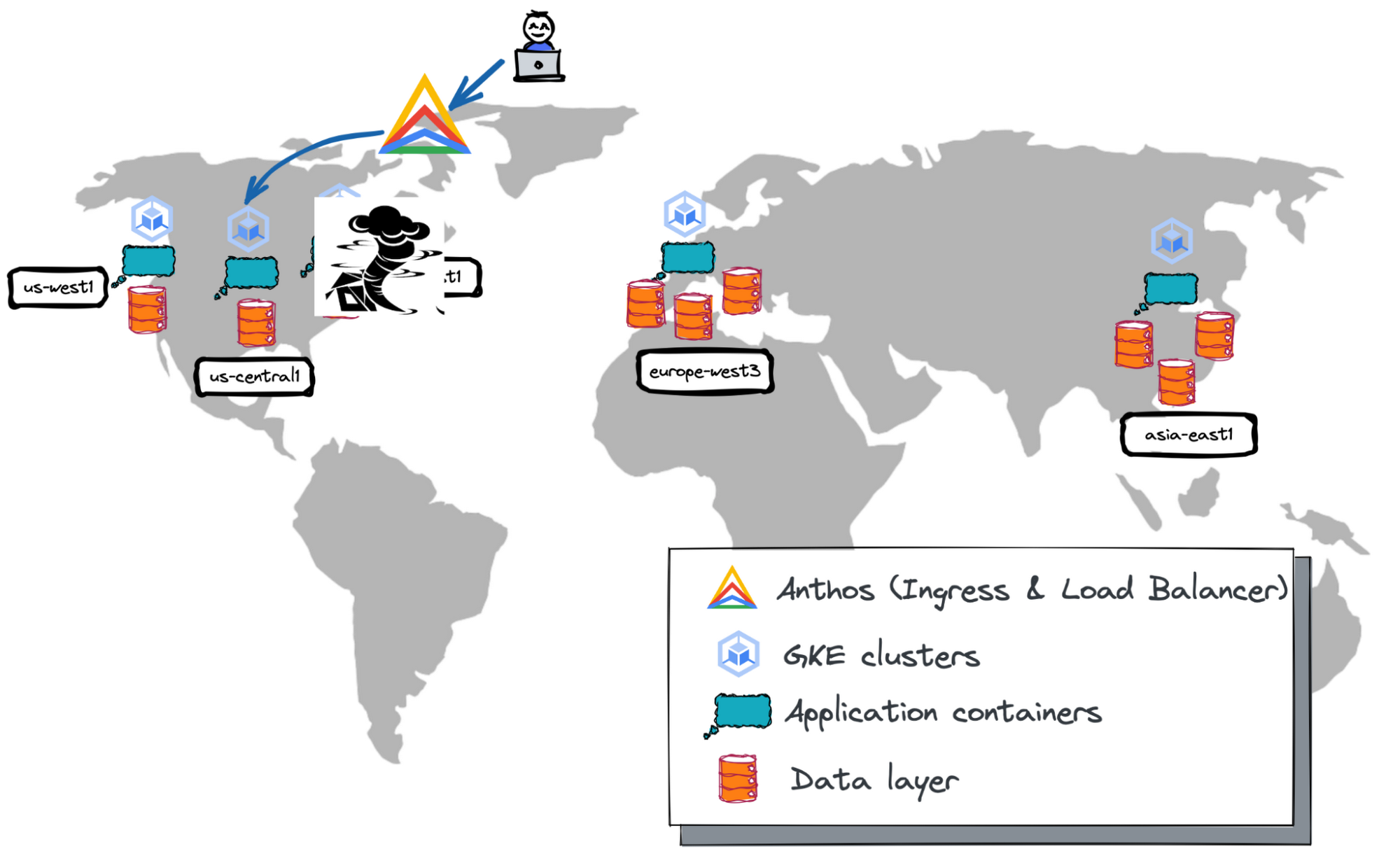
Our application is spread across five cloud regions. Three regions are in North America—us-west1, us-central1 and us-east1. The remaining two are in Europe and Asia—europe-west3 and asia-east1.
Each region runs a standalone Kubernetes cluster in GKE. The application containers are deployed to every cluster ready to serve user requests.
Google Anthos is used as a centralized management plane for the Kubernetes clusters. Anthos provides the multi-cluster ingress capability that automatically routes user requests to the nearest GKE deployment.
The data layer of geo-distributed apps is also distributed and scales horizontally. You should select a database offering based on your application use case, as well as your need for high availability, performance, data regulatory, and other requirements. The geo-messenger uses two globally distributed databases — Google Cloud Storage and YugabyteDB (discussed in more detail below).
Although the architecture includes many globally distributed components, it’s straightforward to bring it to life in the Google Cloud Platform (GCP). Let’s go ahead and deploy the geo-messenger following the architecture, and then test its fault tolerance, performance, and data residency capabilities.
Step 1: Provisioning Google Kubernetes Engine Clusters
GKE provides a managed environment for deploying, managing, and scaling your containerized applications on the Google infrastructure. As long as the geo-messenger can run in containers, the first step is to provision standalone Kubernetes clusters in every cloud region where an application instance needs to be available.
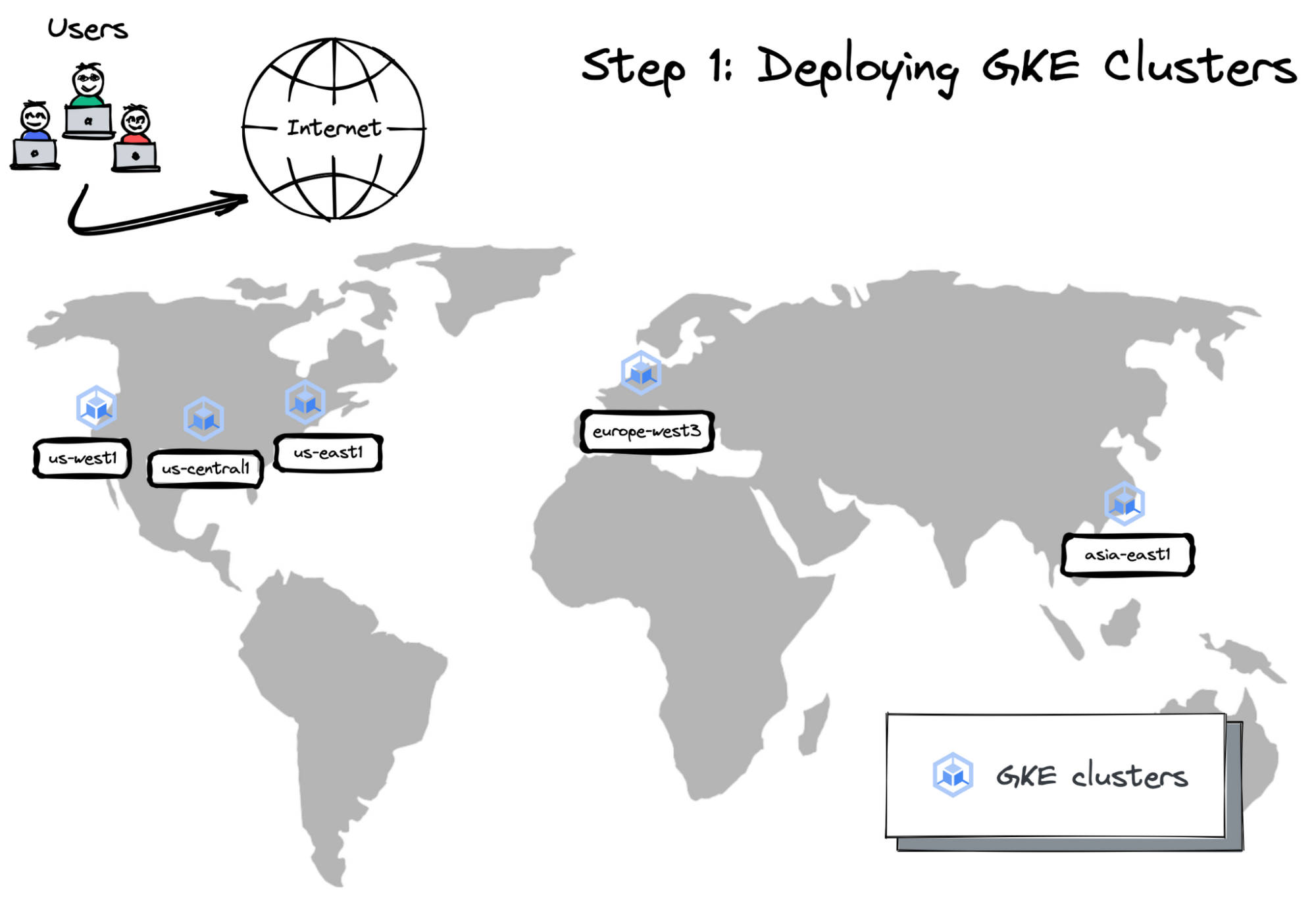
Create a dedicated Google Cloud project for the application
Enable Anthos and other required APIs
Create a service account for GKE clusters
Start GKE clusters in five cloud regions across North America, Europe and Asia
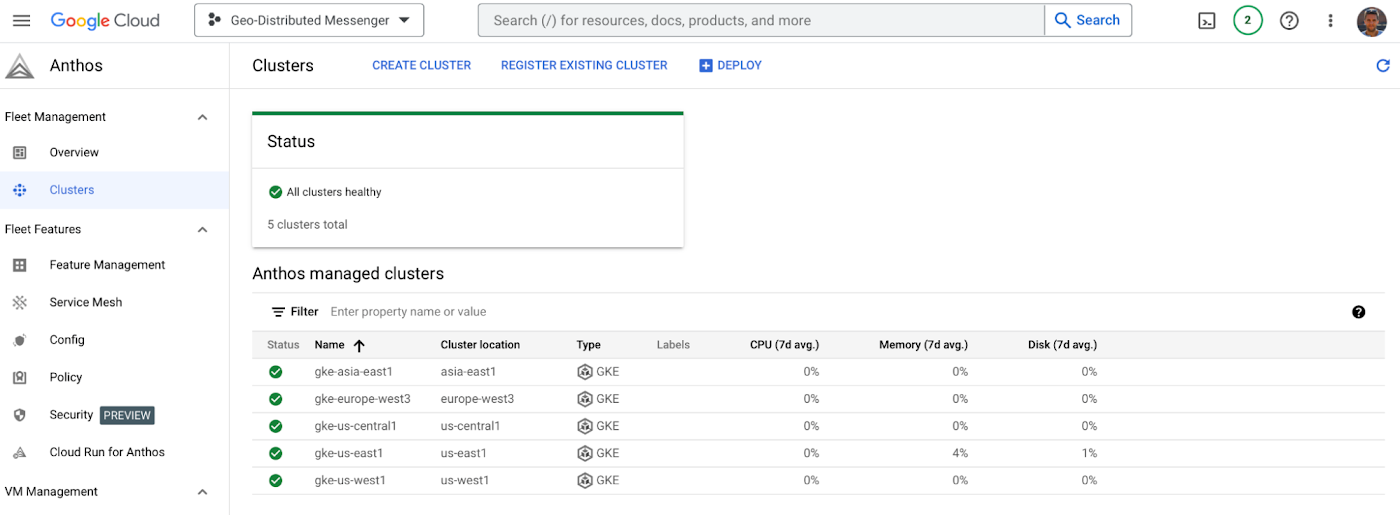
After the clusters are deployed, you can check that they are registered with the Anthos fleet:
You can also see the clusters on the Anthos management plane:
Step 2: Configuring databases
With the GKE clusters running across multiple geographies, the next step is to configure a distributed data layer.
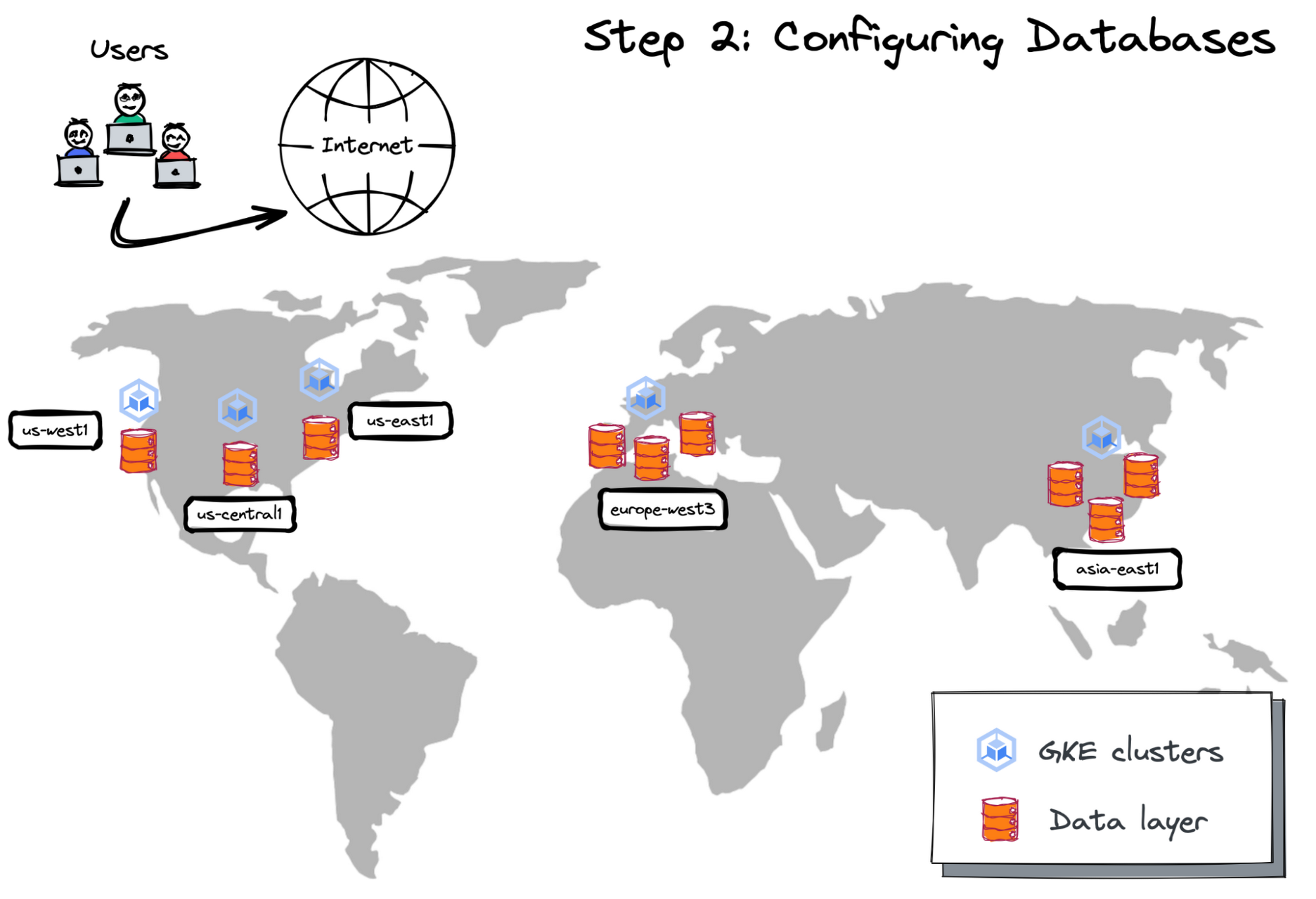
Picture 4. GKE Clusters With Data Layer
As mentioned earlier, you should select databases for a geo-distributed application based on your business use case, and other requirements such as performance and availability SLAs.
The geo-messenger comprises several microservices that use two databases—Google Cloud Storage and YugabyteDB.
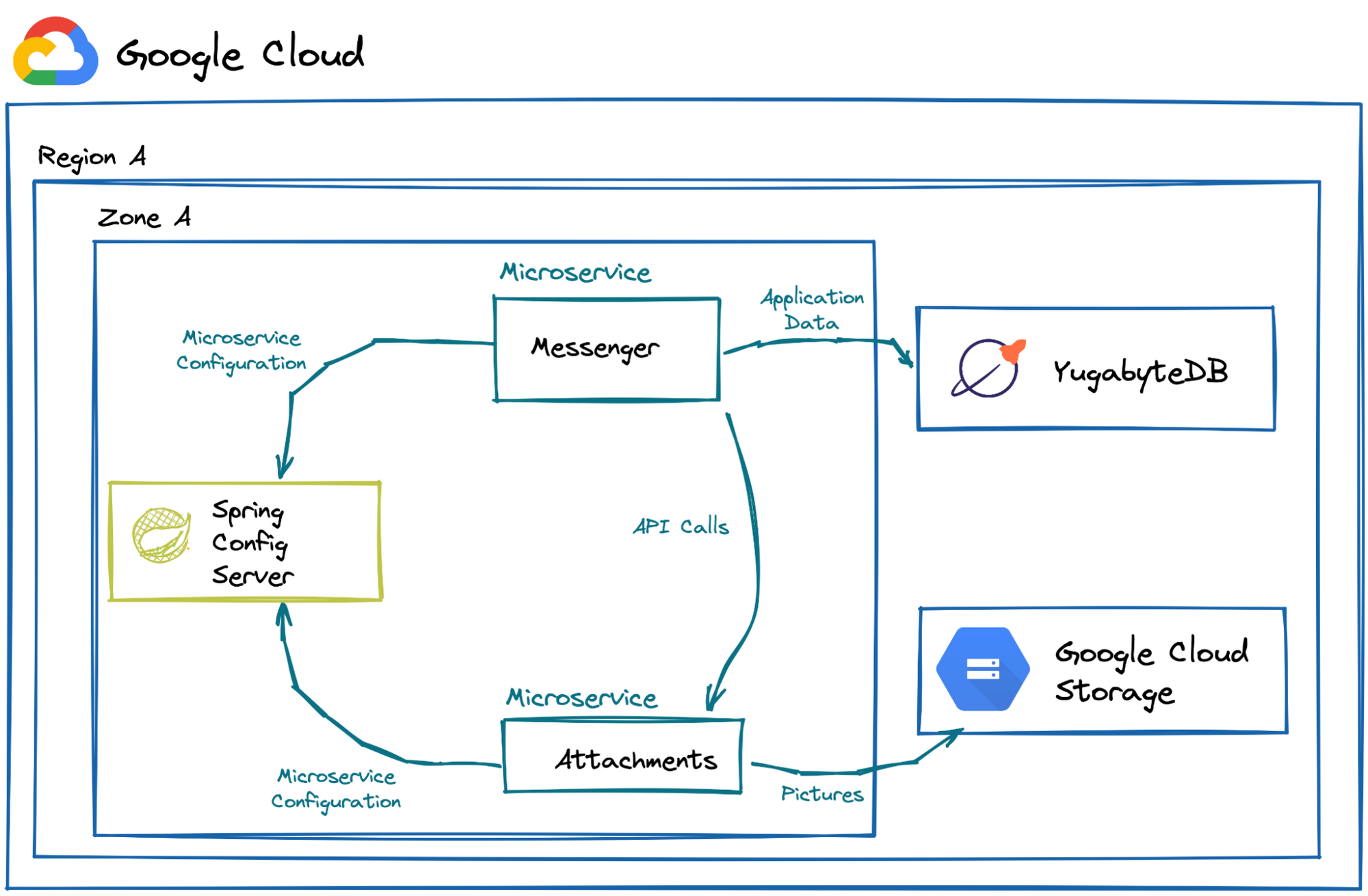
Picture 5. Geo-Messenger Microservices
The Messenger microservice implements the key functionality that every messenger app requires—the ability to send messages across channels and workspaces.
The Attachments microservice uploads pictures and other files. Both microservices are built on Spring Boot. When they start, they retrieve configuration settings from the Spring Cloud Config Server.
The Attachments microservice uses the globally distributed Google Cloud Storage, a managed service for storing unstructured data. With this storage, the geo-messenger can store and share pictures and other attachments in a scalable, performant, and reliable manner.
Cloud Storage can be enabled within minutes. Follow this section of the GitHub guide for guidance.
The Messenger microservice stores application data (user profiles, workspaces, channels, messages, etc.) in YugabyteDB, a PostgreSQL-compatible distributed SQL database.
The main motivation for selecting YugabyteDB as the primary system of record for the geo-messenger is the database's geo-partitioned deployment mode. With this mode, you deploy a single database cluster, and the data is then automatically pinned to and served from various geographies with low latency.
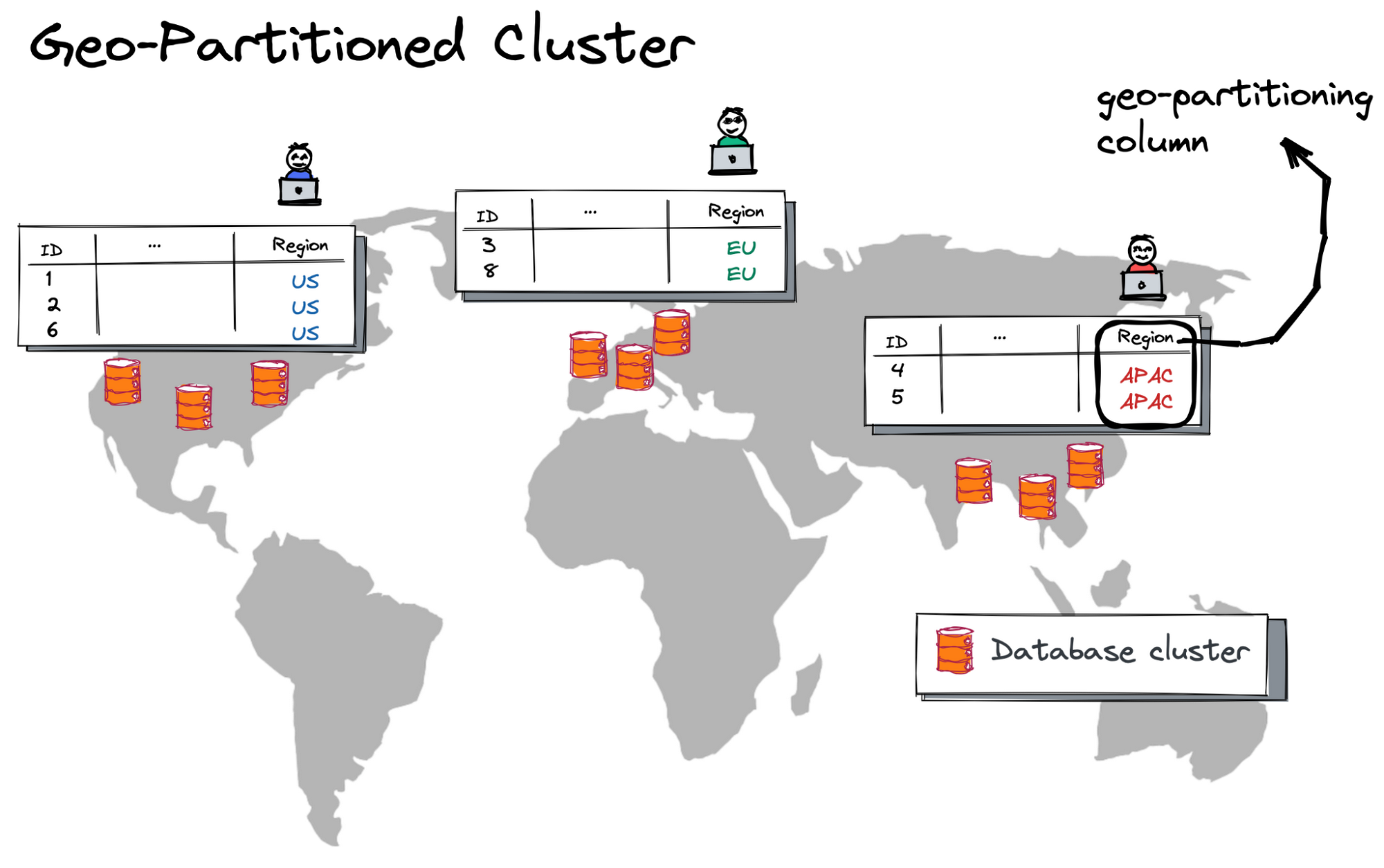
Picture 6. Geo-Partitioned YugabyteDB Cluster
A custom geo-partitioning column (the “Region” column in the picture above) lets the database decide on a target row location. For instance, if the Region column is set to EU, then a row will be placed in a group of nodes from the European Union. This also ensures compliance with local data residency requirements.
Follow this section of the GitHub guide to deploy a single geo-partitioned YugabyteDB Managed cluster, placing the database nodes in all the regions where the GKE clusters are already located.
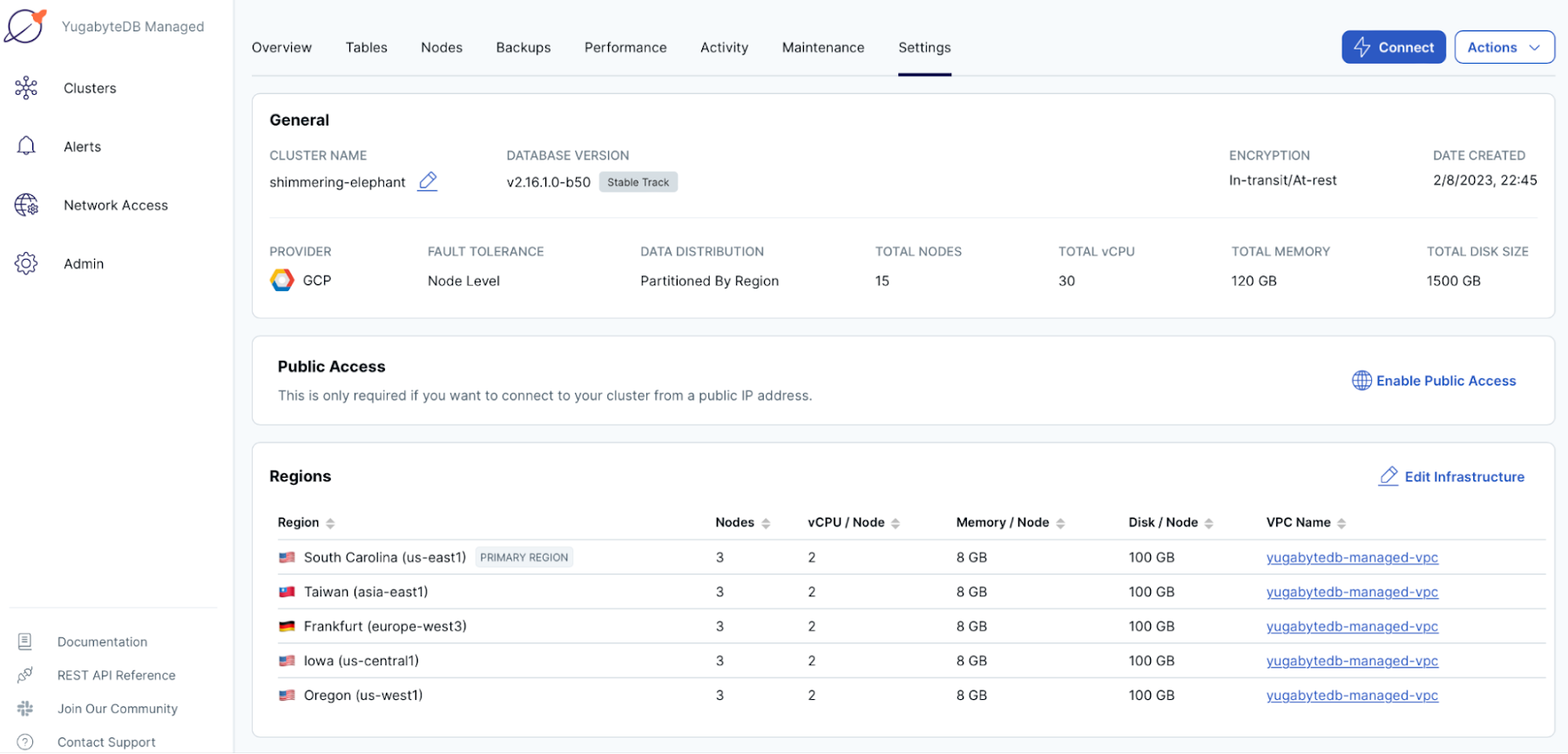
Picture 7. YugabyteDB Managed Cluster Settings
By co-locating database nodes with GKE clusters, the application containers can write to and read from the database with low latency, regardless of where a user request originates.
Step 3: Deploying application containers
After deploying the GKE clusters across North America, Europe, and Asia, and provisioning globally distributed databases, it’s time to deploy application containers in those locations.
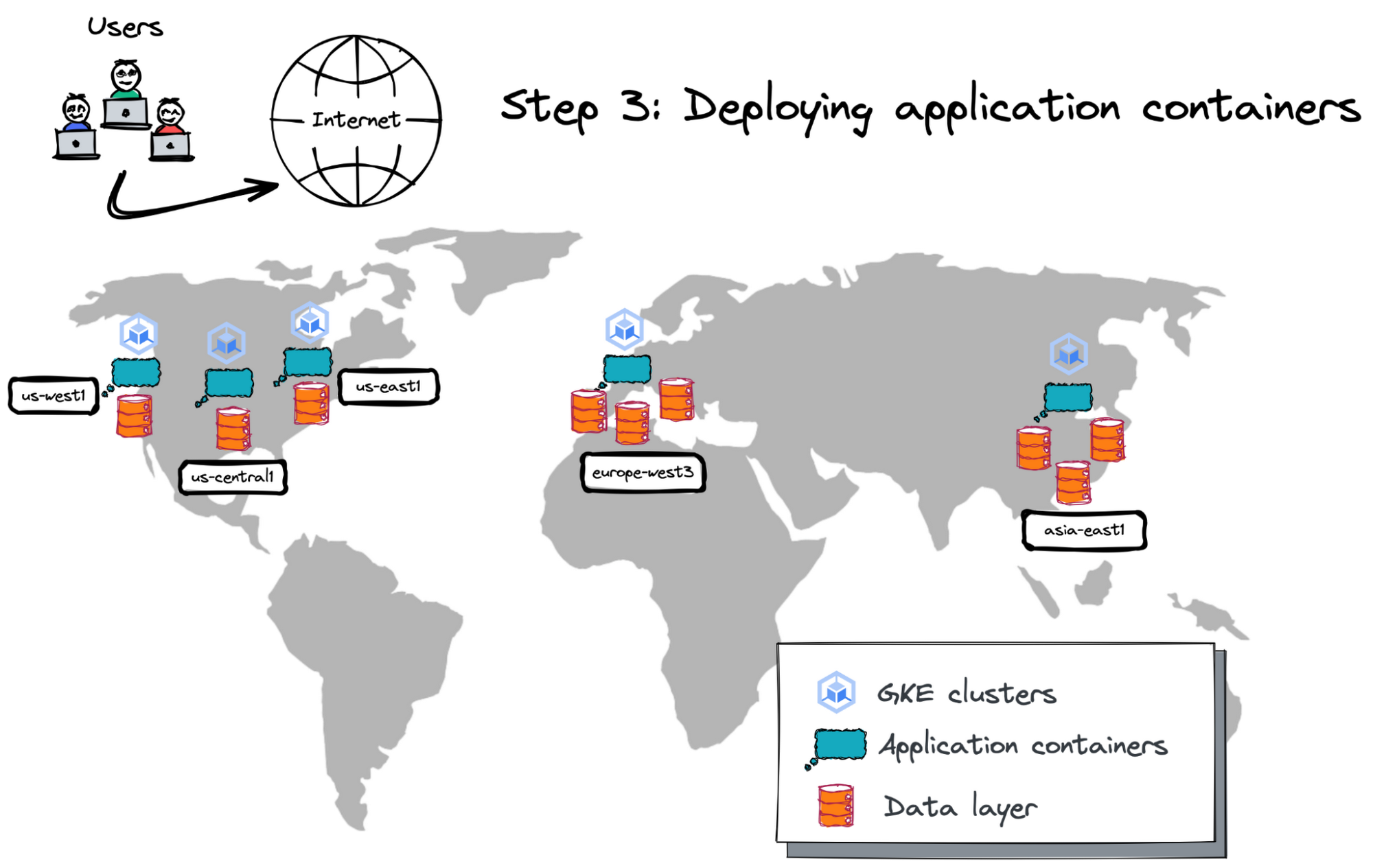
Picture 8. Application Containers Deployment
Follow the step-by-step GitHub guide to:
Create artifact repositories for application Docker images in every cloud location
Load application Docker images to the artifact repositories
Deploy application containers to all GKE clusters
Alternatively, you can see all the containers across all the GKE clusters on a single GKE dashboard:
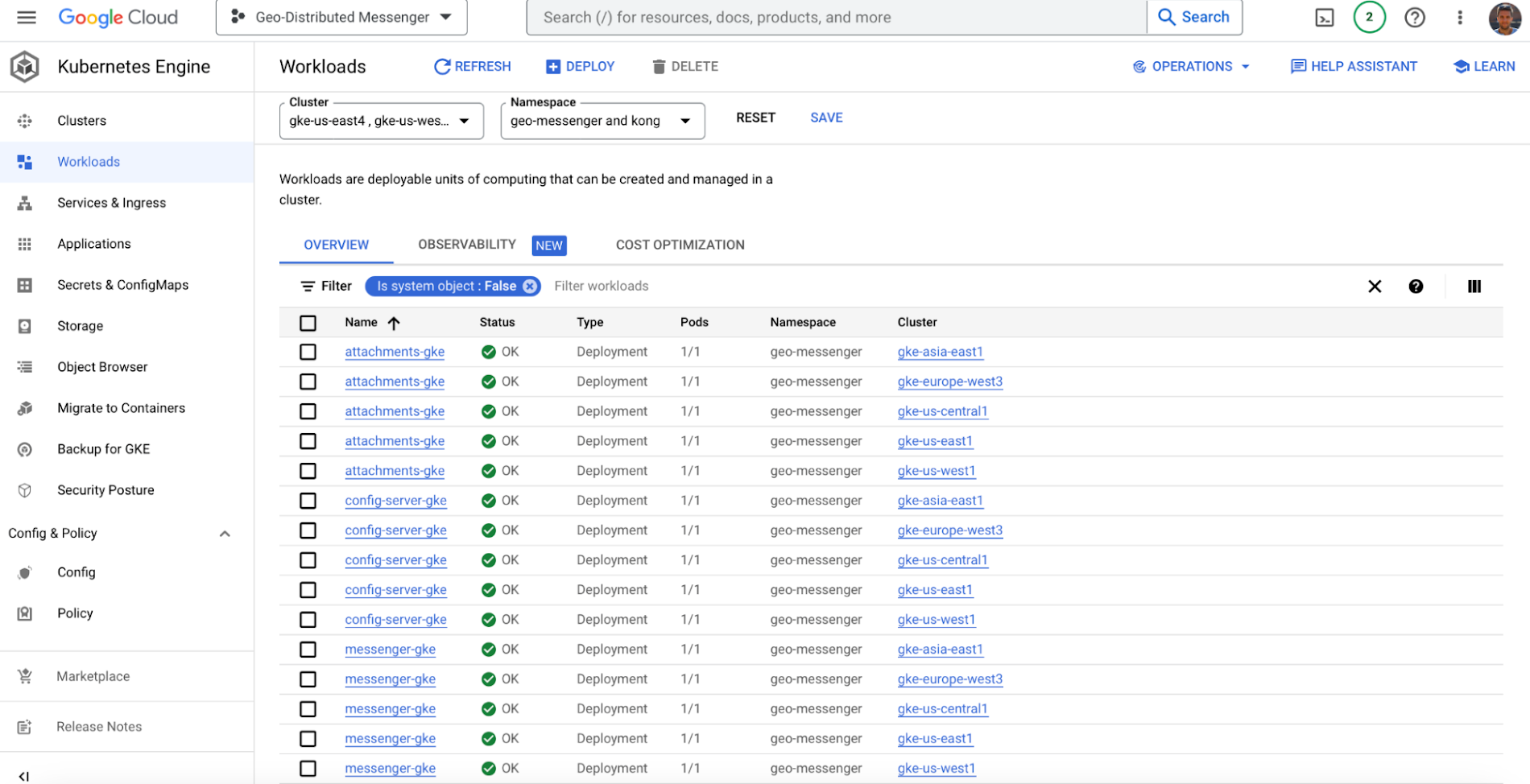
Picture 9. GKE Workloads Panel
1. Get the EXTERNAL_IP address for the LoadBalancer of the messenger-service service:
2. Open the IP address in your browser, sign in using the test@gmail.com/password account, and send a few messages with pictures:
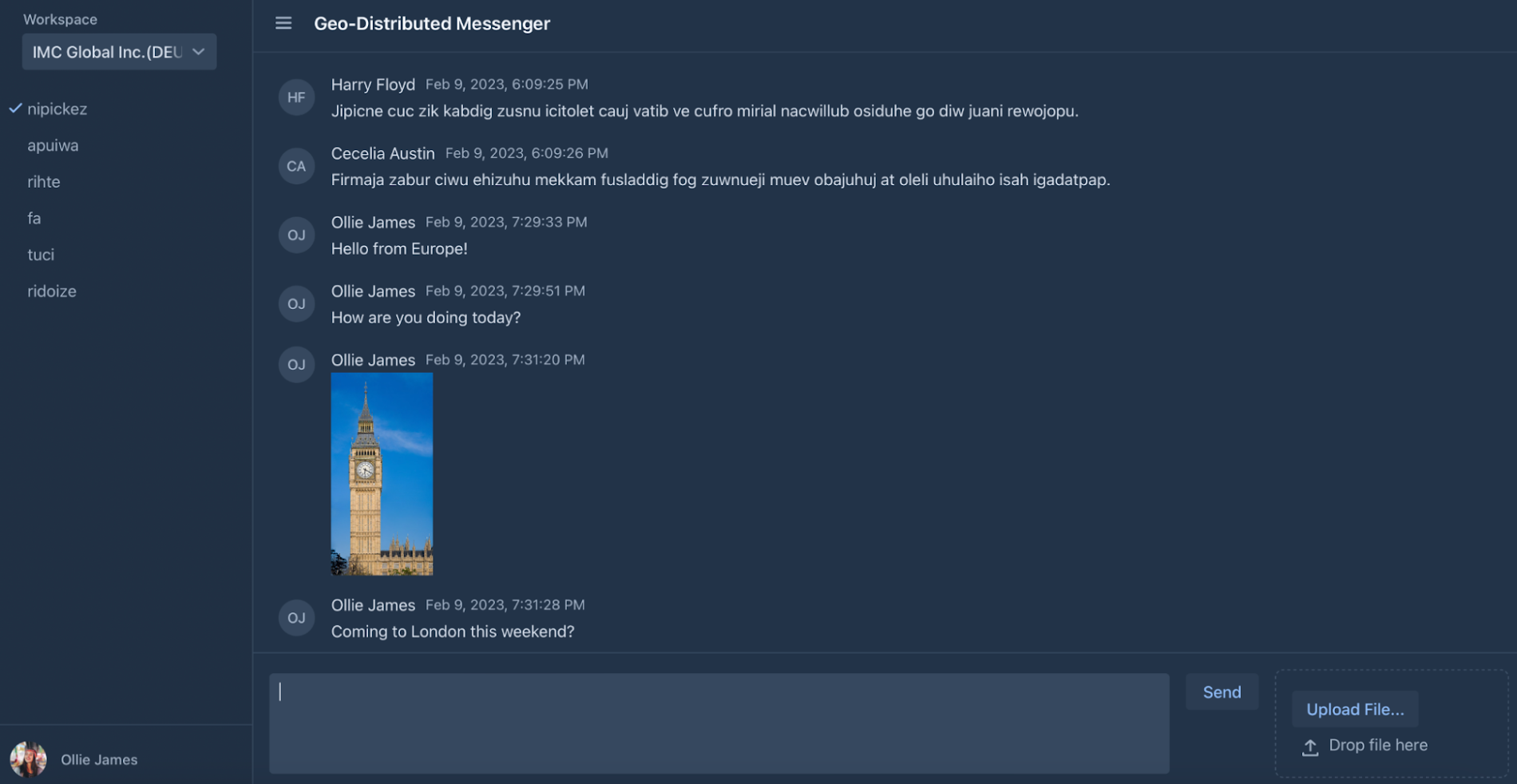
Picture 10. Messenger Instance in Europe
3. Similarly, you can connect to the Messenger’s microservice container deployed in Asia:
4. Open the EXTERNAL_IP address in your browser and send a few messages with pictures via the GKE cluster in the asia-east1 region:
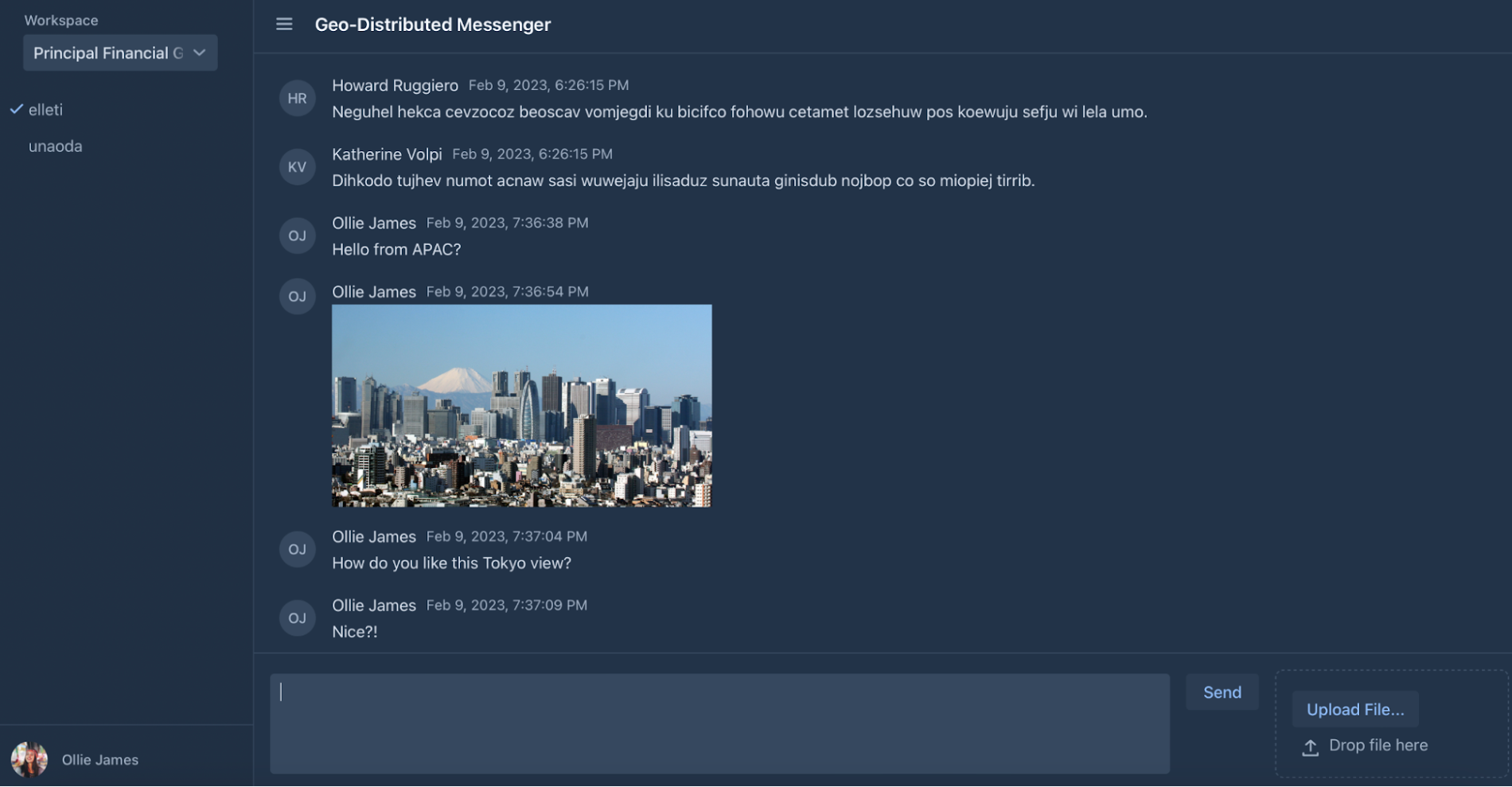
Picture 11. Messenger Instance in Asia
After deploying the containers across North America, Europe, and Asia, you have a fully functioning geo-distributed application. The next step is to automate the routing and load balancing of the user traffic to the nearest GKE clusters.
Step 4: Setting up multi-cluster ingress
After deploying multiple application instances in different cloud locations, you need to enable the multi-cluster ingress.
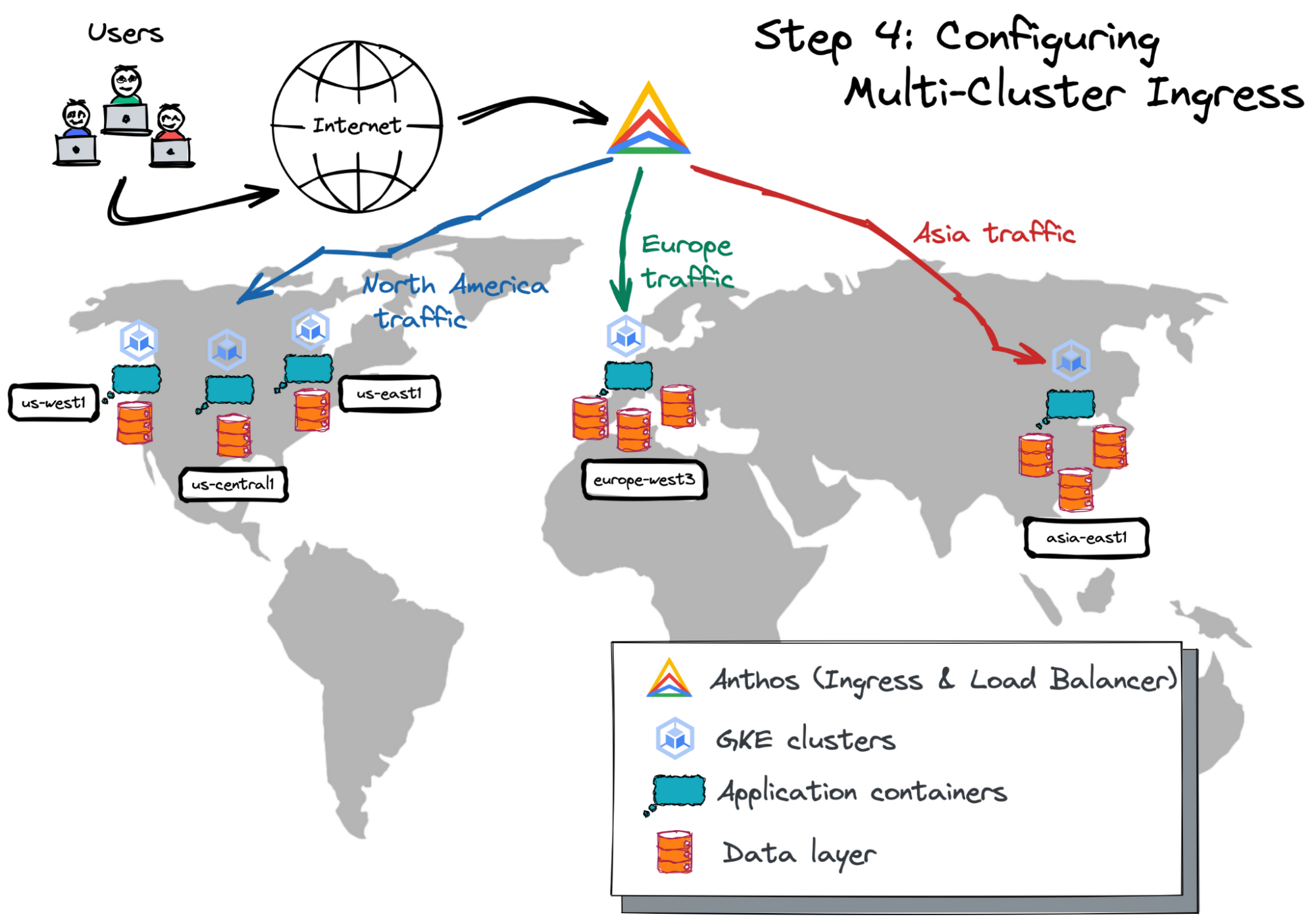
Picture 12. Multi-Cluster Ingress Configuration
Without the ingress, you would need to decide which GKE cluster and application container have to serve a particular user request. This is way too complicated and quickly becomes unmanageable.
The multi-cluster ingress is built on the global external HTTP(S) load balancer. The external load balancer is a globally distributed load balancer with proxies deployed at 100+ Google points of presence (PoPs) worldwide. These proxies, called Google Front Ends (GFEs), sit at the edge of Google's network, positioned close to the users.
The load balancer provides an external anycast IP address. This can be used as a single entry point through any PoP worldwide.
Follow this section of the GitHub guide to enable the ingress. Then use the IP address of the global load balancer as the main access point to the geo-messenger:
2. Open the IP address in your browser: http://VIP:80
For instance, if you live in the US East coast, then your requests will be routed to the network endpoint named k8s1-83efa7a8-geo-messe-mci-geo-messenger-mcs-svc-d3-8-14209346:
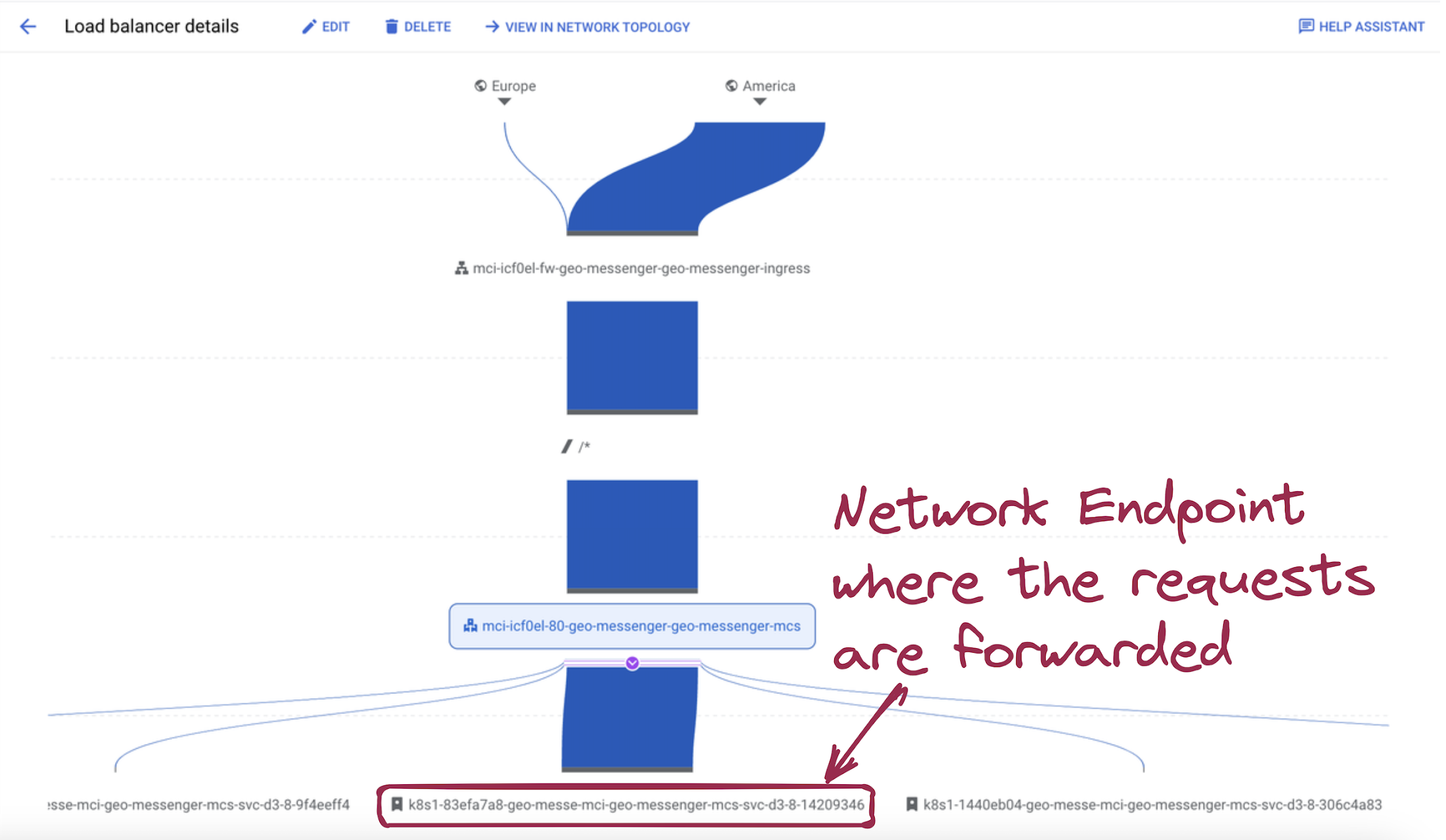
Picture 13. Traffic forwarding to the US East Coast
This network endpoint belongs to the GKE cluster in the us-east1 region:
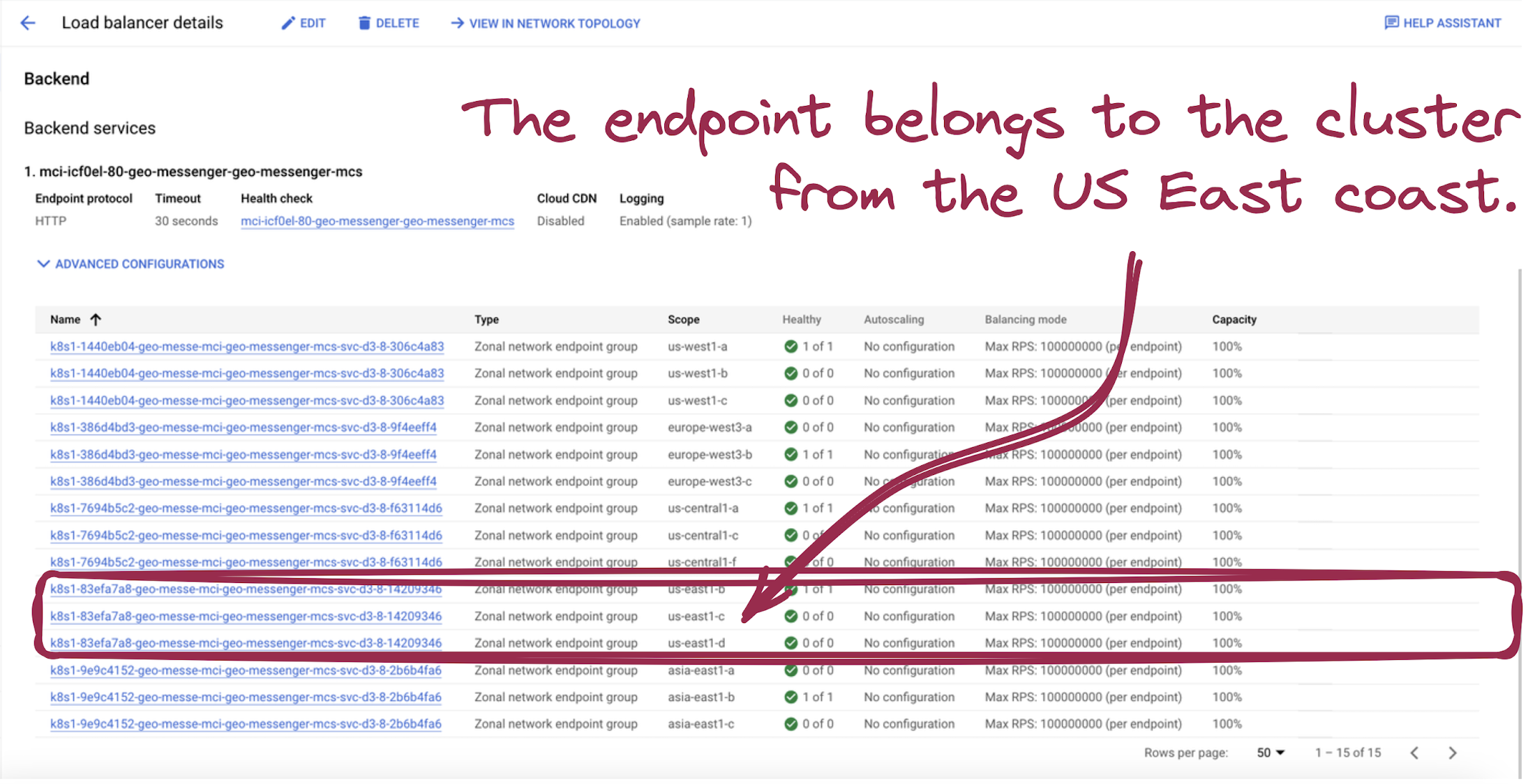
Picture 14. Network Endpoints in US East
This is how the multi-cluster ingress determines which GKE cluster will serve a particular user request.
Key benefits of geo-distributed apps
After configuring the multi-cluster ingress, you have finished deploying your geo-distributed application. Next, let’s use the deployed application to explore the key benefits of data residency, performance, and high availability provided by geo-distributed apps.
Testing data residency
One of the major benefits of geo-distributed apps is the ability to store and serve user data from required geographic locations. This ensures compliance with various data regulatory requirements such as GDPR.
The geo-messenger uses YugabyteDB in the geo-partitioned mode. In this mode, the database automatically pins the user data to required cloud regions based on the value of a geo-partitioning column.
Let’s connect to the database cluster and confirm the data is stored as requested:
1. Open a connection to the database and take a look at the structure of the Profile table:
2. The table is split into three partitions, with each partition storing data from a specific geography. The country_code column is used as a geo-partitioning key:
3. Get the first random user profile that has to be stored in Europe:
4. Confirm this user record with id=5 is stored in the profile_eu partition that belongs to the database nodes in the European Union:
5. Finally, make sure there is no single copy of the record in the partitions from North America and Asia:
Pinning specific user data to required cloud regions is how geo-distributed applications can comply with data regulatory requirements.
Testing Low Latency
Low latency across distant geographies is achieved by deploying GKE clusters with application containers and storing data close to the users.
Imagine that a user from Europe opens the geo-messenger and sends a message to a discussion channel pinned to Europe. The multi-cluster ingress will forward the user request to the GKE cluster in the europe-west3 region. The application container from that cluster will store the message to the database nodes within the same region.
The database will replicate the message across three nodes from three different availability zones within the europe-west3 region. The latency for this operation can be as low as 5 milliseconds:
Note: these are the logs of the Messenger microservice’s container that handles the user request.
The write latency will be the same for users in Asia who send messages to the channels pinned to that geography:
It may be that a user from Asia needs to send a message to a channel pinned to Europe. In this case, a database node from Asia automatically forwards the message to the nodes in Europe. The latency for this operation will be higher as long as the data needs to travel across the continent:
But, what’s important here is the ability to make cross-continent requests via a single database connection when necessary.
However, in practice, most read and write requests will be processed with low latency by the GKE clusters and database nodes closest to the user.
Testing Fault Tolerance
The last significant benefit of geo-distributed applications is the ability to tolerate all sorts of possible outages, including zone and region-level incidents.
Let’s emulate a region-level outage in the us-east1 region and see how the geo-messenger handles the incident. Suppose requests of a user from the US East coast are processed by the GKE cluster in the us-east1:
Picture 15. User Traffic Forwarding to US East
First, emulate an outage by stopping all the application containers in the GKE cluster on the US East coast:
Terminate the messenger-gke container:
2. The multi-cluster ingress will detect the outage momentarily and start forwarding the user's requests to another network endpoint name k8s1-7694b5c2-geo-messe-mci-geo-messenger-mcs-svc-d3-8-f63114d6:
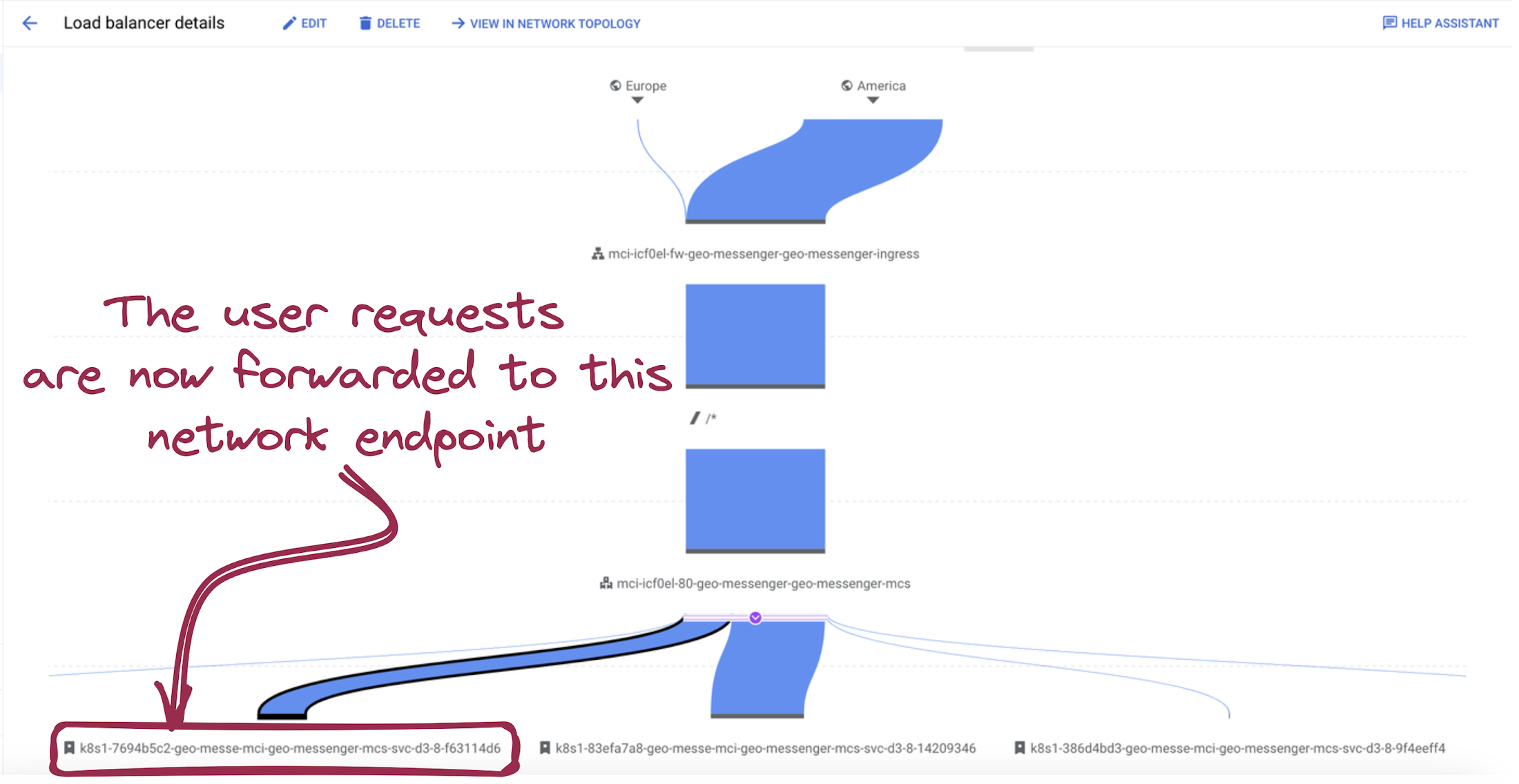
Picture 16. User Traffic Forwarding to Another Location
3. That endpoint belongs to the GKE cluster from the US Central region:
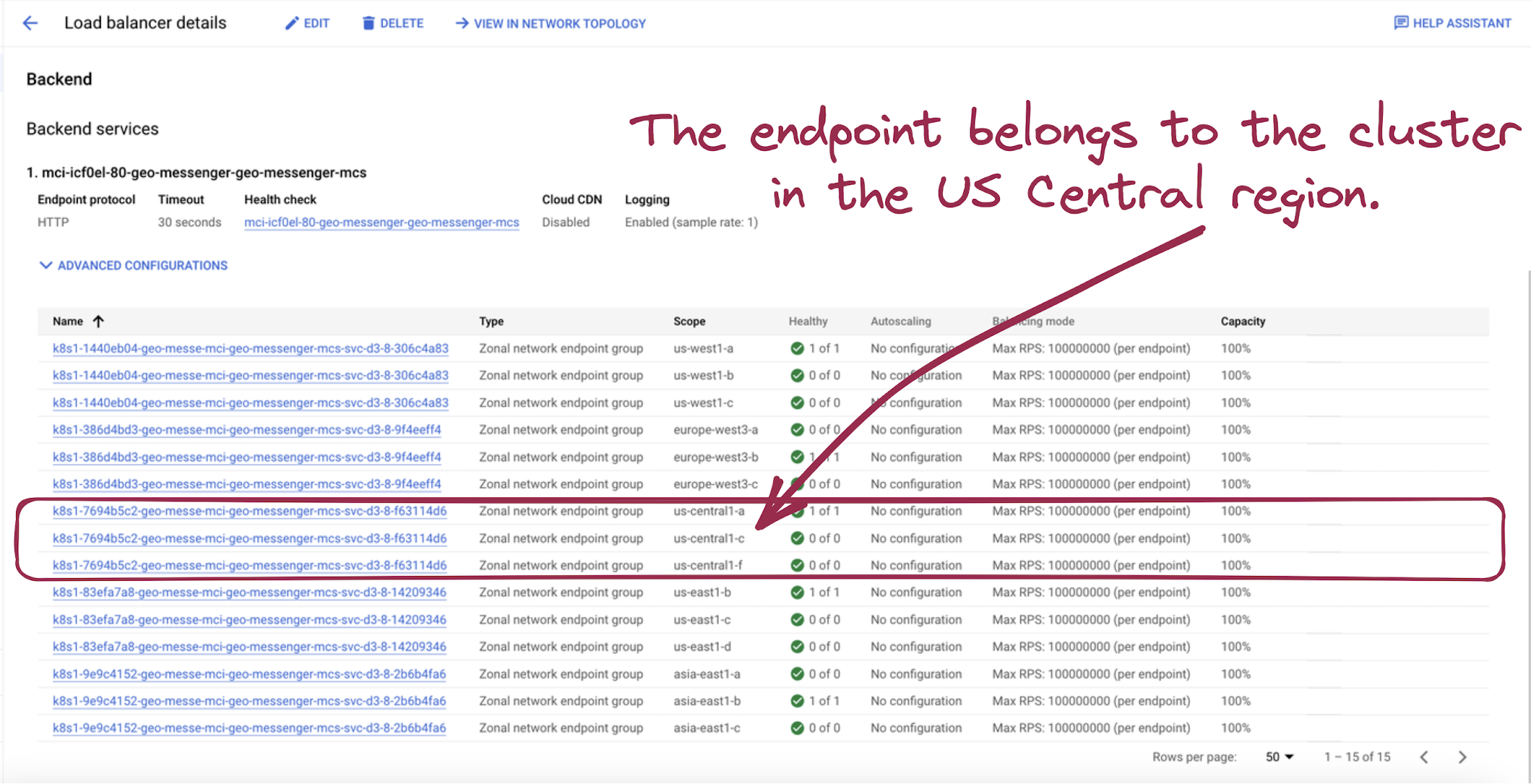
Picture 17. Network Endpoint in US Central
As you see, the multi-cluster ingress detects outages in your geo-distributed application and starts routing the user traffic to other closest GKE clusters.
This capability lets you avoid downtime and continue serving user requests, even during significant incidents.
Summary
Google Cloud Platform’s infrastructure and services, like Google Kubernetes Engine, Multi-Cluster Ingress, and Anthos, in combination with YugabyteDB, allow you to rapidly innovate by creating highly available, performant, and compliant geo-distributed applications.
Next steps:
Learn more about Google Kubernetes Engine (GKE) and Google Cloud Storage (GCS)
Discover more about YugabyteDB
Dive into distributed SQL with Distributed SQL Databases for Dummies
Ready to give it a try? Procure YugabyteDB through Google Cloud Marketplace, and build your first geo-distributed applications.
