Powerful infrastructure innovations for your AI-first future

Mark Lohmeyer
VP & GM, Compute and AI Infrastructure
The rise of generative AI has ushered in an era of unprecedented innovation, demanding increasingly complex and more powerful AI models. These advanced models necessitate high-performance infrastructure capable of efficiently scaling AI training, tuning, and inferencing workloads while optimizing for both system performance and cost effectiveness.
Google Cloud has been pioneering AI infrastructure for over a decade, culminating in a unified architecture called AI Hypercomputer that seamlessly integrates workload-optimized hardware (TPUs, GPUs, and CPUs), open software, and flexible consumption models to power the most advanced AI models. This holistic approach optimizes every layer of the stack for optimal scale, performance, and efficiency across the broadest range of models and applications. AI Hypercomputer is one of the many reasons why Google Cloud was named a leader in Forrester’s AI Infrastructure Wave. Just last week, Google Cloud was also named a Leader in Gartner’s Magic Quadrant for Strategic Cloud Platform Services, where for the second consecutive year, we are the only Leader to improve on both vision and ability to execute.
This year we’ve made enhancements throughout the AI Hypercomputer stack to improve performance, ease of use, and cost efficiency for customers, and today at the App Dev & Infrastructure Summit, we’re pleased to announce:
- Our sixth-generation TPU, Trillium, is now available in preview
- A3 Ultra VMs powered by NVIDIA H200 Tensor Core GPUs will be available in preview next month
- Hypercompute Cluster, our new highly scalable clustering system, will be available starting with A3 Ultra VMs
- C4A VMs, based on Axion, our custom Arm processors, are now generally available
- AI workload-focused enhancements to Jupiter, our data center network, and Titanium, our host offload capability
- Hyperdisk ML, our AI/ML-focused block storage service, is generally available
Trillium: Ushering in a new era of TPU performance
TPUs power our most advanced models such as Gemini, popular Google services like Search, Photos, and Maps, as well as scientific breakthroughs like AlphaFold 2 — which recently led to a Nobel Prize! Today, we’re pleased to announce that Trillium, our sixth-generation TPU, is now available to Google Cloud customers in preview.
Compared to TPU v5e, Trillium delivers:
- Over 4x improvement in training performance
- Up to 3x increase in inference throughput
- A 67% increase in energy efficiency
- An impressive 4.7x increase in peak compute performance per chip
- Double the High Bandwidth Memory (HBM) capacity
- Double the Interchip Interconnect (ICI) bandwidth
Doubling the HBM capacity and bandwidth enables Trillium to work more effectively with larger models with more weights and larger key-value caches. Trillium's high compute-to-HBM ratio makes it ideal for a wide range of model architectures across training and inference. It also makes it particularly well-suited for training dense large language models (LLMs) like Gemma 2 and Llama, as well as targeted Mixture of experts (MoE) implementations. Furthermore, Trillium excels in compute-intensive inference, including large diffusion models like Stable Diffusion XL.
Trillium can scale up to 256 chips in a single high-bandwidth, low-latency pod using high-speed interchip interconnect (ICI). From there, you can scale to hundreds of pods, connecting tens of thousands of chips in a building-scale supercomputer, interconnected by our 13 Petabit per second Jupiter data center network. With Multislice software, Trillium enables near linear scaling of performance for training workloads across hundreds of pods. As the most flop-dense TPU to date, Trillium packs 91 exaflops of unprecedented scale in a single TPU cluster. This is four times more than the largest cluster we built with TPU v5p.
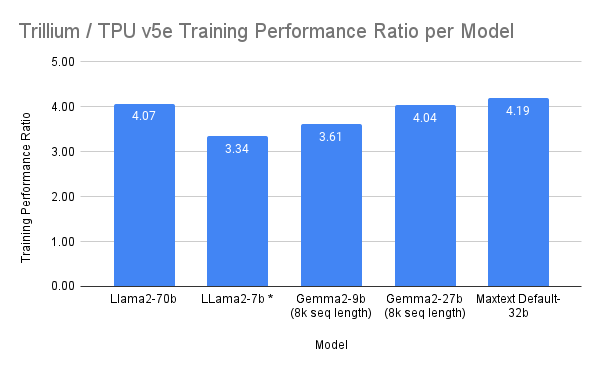
In benchmark testing, Trillium delivered more than a 4x increase in training performance for Gemma 2-27b, MaxText Default-32b, and Llama2-70B; and more than 3x increase for LLama2-7b, and Gemma2-9b compared to TPU v5e.
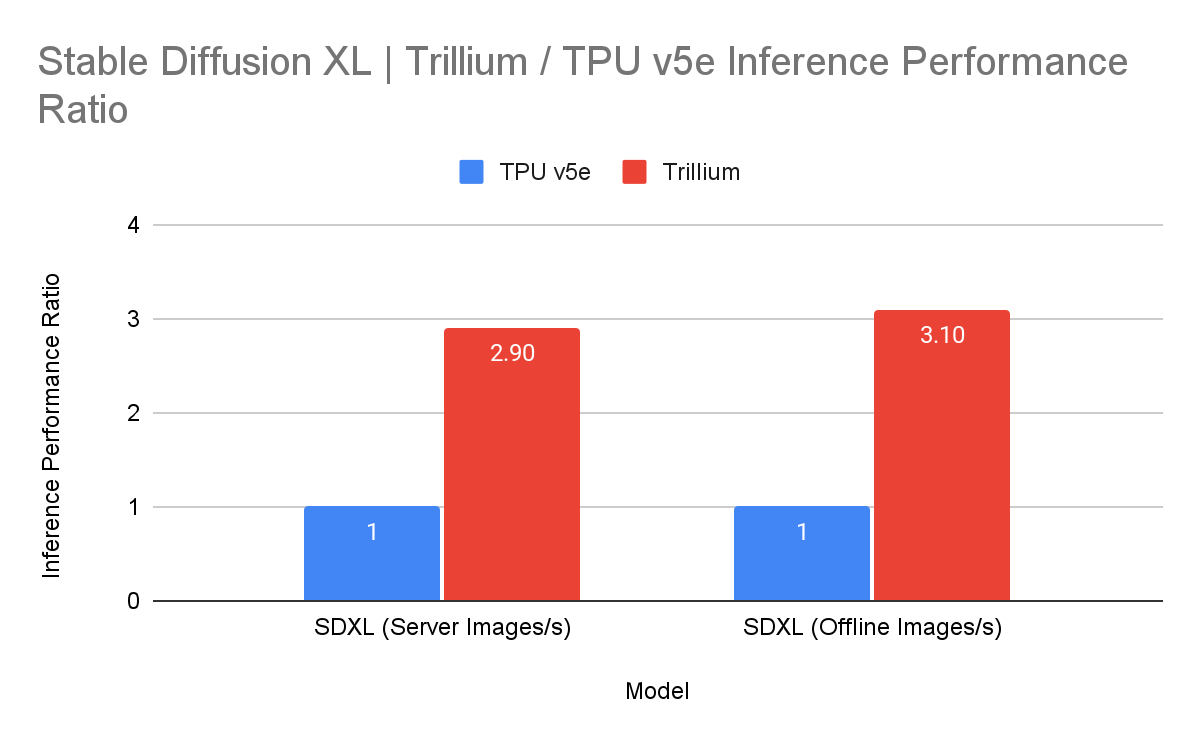
Trillium also delivers a 3x increase in inference throughput for Stable Diffusion XL compared to TPU v5e.
We design TPUs to optimize performance per dollar, and Trillium is no exception, demonstrating nearly a 1.8x increase in performance per dollar compared to v5e and about 2x increase in performance per dollar compared to v5p. This makes Trillium our most price-performant TPU to date.

What customers are saying
Customers that have used Trillium are enthusiastic about the results that they are seeing.
“At Deep Genomics, we are building an AI foundation model platform to design the next generation of RNA therapeutics for previously intractable diseases with high unmet need. Our first, proprietary foundation model is BigRNA, which underpins our leadership in RNA therapeutic discovery. BigRNA accurately predicts the tissue-specific regulatory mechanisms behind gene regulation and RNA expression, including the binding sites of proteins and microRNAs. Using Google’s Trillium TPUs, we ran BigRNA inference on tens of millions of variants in the human genome and generated trillions of biological signals that drive healthy and diseased cell states. This unprecedented database will help us and our partners identify new RNA interventions in both complex and rare diseases.”- Joel Shor, VP & Head of ML, Deep Genomics
“We are a technology hub, building next-gen apps using world-class expertise and cutting-edge tech. We used Trillium TPU for text-to-image creation with MaxDiffusion & FLUX.1 and the results are amazing! We were able to generate four images in 7 seconds — that's a 35% improvement in response latency and ~45% reduction in cost/image against our current system! We are excited to bring these improvements to millions of users around the world who use our apps, starting with our flagship apps, Nova and DaVinci in 2025!” - Deniz Tuna, Head of Development, HubX
“We’ve been using TPUs on our text-to-image and text-to-video models since Cloud TPU v4. With TPU v5p and AI Hypercomputer efficiencies we achieved a whopping 2.5x increase in training speed! The sixth generation of Trillium TPUs are incredible with a 4.7x increased compute performance per chip and 2x HBM capacity and bandwidth improvement over the previous generation. This came just in time for us as we scale our text-to-video models. We're also looking forward to using Dynamic Workload Scheduler Flex Start mode to manage our batch inference jobs and to manage our future TPU reservations.” - Yoav HaCohen, PhD, Core Generative AI Research Team Lead, Lightricks
“SkyPilot enables organizations to seamlessly and cost-effectively run AI workloads on various accelerators across regions. We’ve observed a growing number of customers leveraging Google Cloud’s Trillium TPU, to train and serve their foundation models. The ease of migration from previous TPU generations, combined with Trillium’s performance and cost-efficiency, enables our customers to accelerate model development and experimentation.” — Zongheng Yang, Project Lead, SkyPilot
Expanding the horizon with NVIDIA Accelerated Computing
We also continue to invest in our partnership and capabilities with NVIDIA, combining the best of Google Cloud’s data center, infrastructure, and software expertise with the NVIDIA AI platform, highlighted by A3 and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs.
Today we’re announcing an expansion of this portfolio with the new A3 Ultra VMs powered by NVIDIA H200 Tensor Core GPUs, coming to Google Cloud next month.
A3 Ultra VMs offer a significant leap in performance over previous generations. They are built on servers with our new Titanium ML network adapter, optimized to deliver a secure, high-performance cloud experience for AI workloads, including and building on NVIDIA ConnectX-7 network interface cards (NICs). Combined with our datacenter-wide 4-way rail-aligned network, A3 Ultra VMs deliver non-blocking 3.2 Tbps of GPU-to-GPU traffic with RDMA over Converged Ethernet (RoCE).
Compared with A3 Mega, A3 Ultra offers:
- 2x the GPU-to-GPU networking bandwidth, powered by Google Cloud’s Titanium ML network adapter and backed by our Jupiter data center network
- Up to 2x higher LLM inferencing performance with nearly double the memory capacity and 1.4x more memory bandwidth
- Ability to scale to tens of thousands of GPUs in a dense, performance-optimized cluster for large AI and HPC workloads (see below)
A3 Ultra VMs will also be available through Google Kubernetes Engine (GKE), which provides an open, portable, extensible, and highly scalable platform for large scale training and serving AI workloads.
Organizations like JetBrains are excited to be a part of our early testing for A3 Ultra VMs:
“JetBrains AI Assistant provides real-time code suggestions as developers type, so minimizing latency is critical for a seamless user experience. We've been using A3 Mega GPUs powered by NVIDIA H100 Tensor Core GPUs on Google Cloud to power our ML services across multiple regions. We are now excited to try out A3 Ultra VMs powered by NVIDIA H200 Tensor Core GPUs, which we expect will further reduce latency and enhance the responsiveness of JetBrains AI Assistant.” - Uladzislau Sazanovich, Machine Learning Team Lead, JetBrains
Hypercompute Cluster: Streamline and scale AI accelerator clusters
But it’s not just about individual accelerators or VMs — with AI and HPC workloads, you need to deploy, manage and optimize very large numbers of AI accelerators and their associated networking and storage, which can be complex and time-consuming. That’s why today, we’re announcing Hypercompute Cluster, which streamlines the infrastructure and workload provisioning, and ongoing operations of AI supercomputers with up to tens of thousands of accelerators. At its core, Hypercompute Cluster combines the best of Google Cloud’s AI infrastructure technologies so you can seamlessly deploy and manage a large number of accelerators as a single unit. With features such as dense co-location of resources with ultra-low latency networking, targeted workload placement, and advanced maintenance controls to minimize workload disruptions, Hypercompute Cluster is built to deliver exceptional performance and resilience, so you can run your most demanding AI and HPC workloads with confidence.
You can set up a Hypercompute Cluster with a single API call from pre-configured and validated templates for reliable and repeatable deployments. This includes containerized software with framework and reference implementations (e.g. JAX, PyTorch, MaxText), orchestration (e.g. GKE, Slurm), and popular open models such as Gemma2 and Llama3. Each pre-configured template is accessible as part of the AI Hypercomputer architecture and is validated for performance and efficiency so you can focus on innovating for your business.
Hypercompute Cluster will be available next month starting with A3 Ultra VMs.
A glimpse into the future: NVIDIA GB200 NVL72
We're also eagerly anticipating the advancements enabled by NVIDIA GB200 NVL72 GPUs, and we look forward to sharing more updates on this exciting development soon. In the meantime, here is a sneak peek at the racks we’re building to bring the performance benefits of the NVIDIA Blackwell platform to Google Cloud’s advanced, sustainable data centers early next year.

Google Axion Processors: Redefining CPU performance and efficiency
While TPUs and GPUs excel in specialized tasks, CPUs are a price-performant option for a broad range of general-purpose workloads, and are often used in conjunction with AI workloads to deliver complex applications. At Google Cloud Next ‘24, we announced Google Axion Processors, our first custom Arm®-based CPUs designed for the data center. Now, Google Cloud customers can take advantage of C4A virtual machines, the first Axion-based VM series, with up to 10% better price-performance than the latest generation Arm-based instances available from other leading cloud providers. C4A also offers up to 65% better price-performance and up to 60% better energy-efficiency than comparable current-generation x86-based instances for general-purpose workloads like web and app servers, containerized microservices, open-source databases, in-memory caches, data analytics engines, media processing, and AI inferencing applications.
We’ve seen incredible excitement for C4A from our customers and partners so far:
"Paramount+ is committed to delivering the highest quality viewing experiences across all our platforms. Google Cloud's Axion and C4A VMs provide the performance and efficiency we need to leverage the latest advancements in video-encoding technology. With C4A VMs, we're able to utilize higher efficiency of the new Arm processors to achieve 33% faster encode times compared to older VMs. This ensures we can encode and distribute content at scale for our viewers in a timely manner with a focus on video quality, vibrant visuals, and immersive audio, regardless of their device or connection."
- Jignesh Dhruv, VP Video Engineering, Paramount Streaming
"loveholidays is one of the fastest websites in travel. With Axion, we no longer have to trade off performance with cost optimization. We get an unprecedented level of performance, showing a 40% reduction in latency against T2D instances, all whilst saving costs on capacity."
- Dmitri Lerko, Head of Engineering, loveholidays
Every watt counts as AI models are increasingly demanding more power and performance. By combining Google’s silicon design expertise with the flexibility of Arm Neoverse, C4A VMs deliver significant performance and efficiency improvements across a variety of key workloads. Software optimization is also critical to accelerating AI capabilities, and with efforts such as the integration of our open Arm Kleidi technology into leading frameworks, we’re seeing even greater performance gains of up to 2-3x on C4A on a range of AI Inference workloads, compared to the previous generation of Arm-based VMs on Google Cloud.”
- Mohamed Awad, Senior Vice President and General Manager, Infrastructure Line of Business, Arm
Titanium and Jupiter Network: Enabling AI at lightspeed
We’re also excited to share that Titanium, a system of offload technologies that underpins our infrastructure, has been enhanced to support AI workloads. Titanium reduces processing overhead on the host through a combination of on-host and off-host offloads, to deliver more compute and memory resources for your workloads. And while AI infrastructure can benefit from all of Titanium’s core capabilities, AI workloads are unique in their accelerator-to-accelerator performance requirements.
To meet these needs, we have introduced a new Titanium ML network adapter that includes and builds on NVIDIA ConnectX-7 NICs to further support VPCs, traffic encryption, and virtualization. When integrated with our data-center-wide 4-way rail-aligned network, the system delivers non-blocking 3.2 Tbps of GPU-to-GPU traffic over RoCE, best-in-class security and infrastructure management.
Titanium's capabilities are further enhanced by our upgraded data center network, Google’s Jupiter optical circuit switching network fabric. Delivering native 400 Gb/s link speeds and a total bisection bandwidth (a realistic measure of bandwidth that represents how one half of the network can communicate with the other) of 13.1 Pb/s, Jupiter possesses the capacity to simultaneously support a video call for every individual on Earth. This immense scale is crucial to accommodate the growing demands of AI computation.
Hyperdisk ML is generally available
High-performance storage is critical to ensuring that compute resources remain highly utilized, optimized for system-level performance, and cost-efficient. Hyperdisk ML is our AI-focused block storage service that we announced in April 2024. Now generally available, it complements the computing and networking innovations discussed in this blog with purpose-built storage for AI and HPC workloads.
- Hyperdisk ML accelerates data load times effectively. For inference workloads, it drives up to 11.9x faster model load time, and for training workloads, it drives up to 4.3x faster training time.
- You can attach 2500 instances to the same volume, and get 1.2 TB/s of aggregate throughput per volume, which is more than 100x higher than offerings from major block storage competitors.
- Shorter data load times translate to less accelerator idle time and greater cost efficiency.
- GKE now automatically creates multi-zone volumes for your data. This lets you run across zones for greater compute flexibility (like reducing Spot preemption) while enjoying faster model loading with Hyperdisk ML.
In addition, check out this recent Parallelstore blog for more information about other storage enhancements for AI workloads.
Shaping the future of AI
Through these advancements in AI infrastructure, Google Cloud empowers businesses and researchers to redefine the boundaries of AI innovation. We are looking forward to the transformative new AI applications that will emerge from this powerful foundation.
To learn more about these announcements, please review the on-demand recording of our App Dev & Infrastructure Summit keynote.



