Realizing cloud value for a render platform at Wayfair - Part 1
Jack Brooks
Wayfair; 3DTools Group
Yusuf Nazami
Senior Staff Engineer at Wayfair
At Wayfair, we have content creation pipelines that automate some portions of 3D model and 3D scene creation, and render images from those models/scenes. At a high level, suppliers provide us with product images and information about dimensions, materials, etc., and we use them to create photorealistic 3D models and generate proprietary imagery. But creating these 3D renders requires significant computation (rendering) capabilities. Last year, we performed a lift-and-shift migration to the cloud, but because we hadn’t optimized our workloads for the cloud, our costs bubbled up substantially. We worked closely with Google Cloud to optimize our render platform, driving an estimated ~$9M of savings on an annualized basis.
Let’s take a look at how we did it.
Lift and shift to Google Cloud
We’ve been working with the Google Cloud team to complete the transition from a hybrid cloud to a Unified Public Cloud strategy. We have two different “farms'' that we use, one primarily for automation tasks and the other for rendering tasks with:
The Automation farm is managed using OpenCue to dispatch jobs to the nodes
The Render Farm uses Deadline to dispatch jobs to the nodes; we completed migrating it from on-premises to the cloud In Q2 2022.
Here’s our lift-and-shift deployed architecture on Google Cloud:
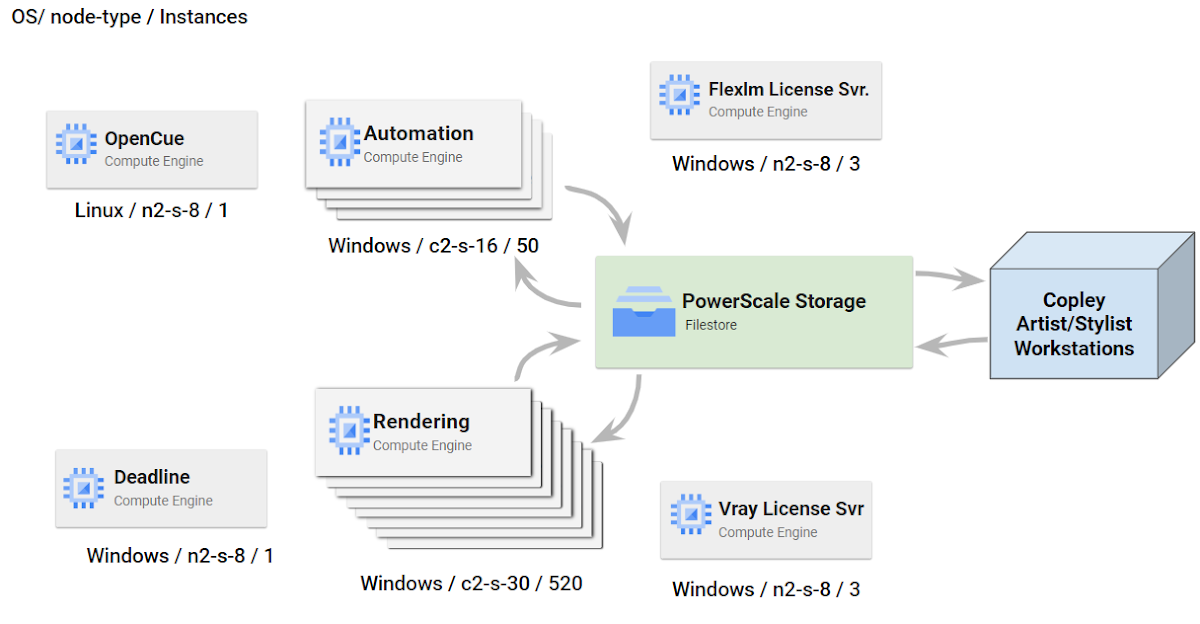
During the migration, our goal was to provide as-is SLAs to our customers without compromising the quality of the pipelines. Post-migration, we recognized inefficiencies in the deployed architecture, which was not well suited for the economics of the pay-as-you-go cloud model. In particular, the architecture had:
Poor infrastructure optimization with fixed farm size and one-size-fits-all machines
Missed opportunities for automation and consolidation
Minimal visibility into cost and render-hour usage across the farm
Wasted usage on rendering due to non-optimized workflows and cost controls
We realized that we could do better than a one-size-fits-all model. With a variety of compute available from Google Cloud, we decided to take advantage of it for the farm. This would help us not only optimize but also provide better visibility and the render-hour usage across the rendering farm, for greater savings.
Cost optimization strategy
We followed the three Cloud FinOps principles — inform, optimize and operate — to create a holistic strategy to optimize our spending and drive sustained governance going forward.
Simplified view
To create an execution plan, the first step was to thoroughly understand what was driving our cloud spending. When on-prem, we didn’t have a lot of insight into our usage and infrastructure costs, as those were managed by a centralized Infrastructure team. During deep dives, we realized that due to a lack of visibility into usage in our current state, , we had many inefficiencies with our deployed infrastructure footprint and how the farm is used by artists and modelers.
We formed a focused team of engineers, business stakeholders, infrastructure experts, and Google Cloud to drive discussions. To optimize rendering costs we needed to not only drive down the cost of the rendering platform but also optimize the workflows to reduce the render hours usage per asset. We developed a simplified formula of all-inclusive render cost per core hour and time needed for each asset, making it easier for each team to drive objectives with focus and transparency. On Google Cloud, we were shifting the focus from an owned asset to pay-per-usage model.
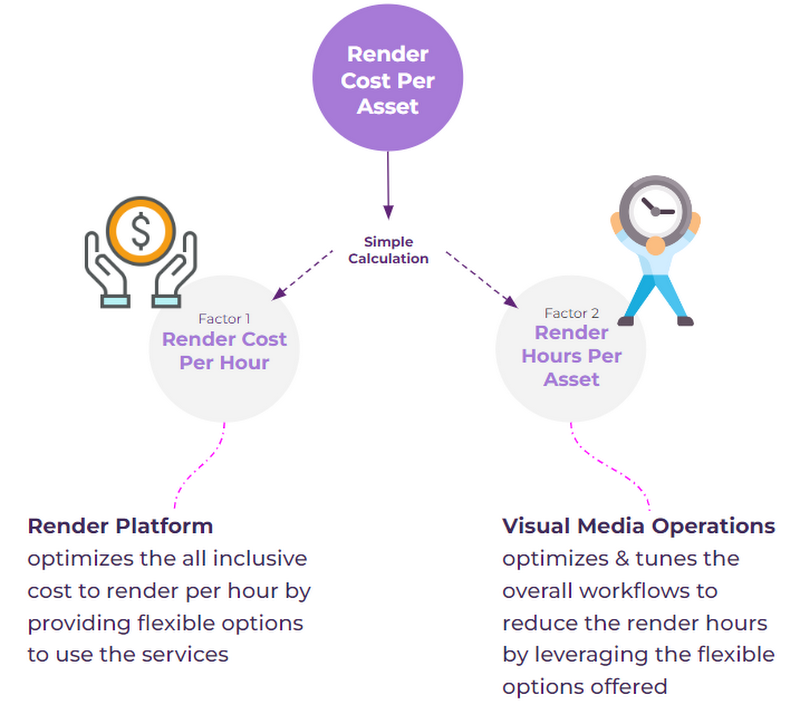
Identifying cost levers
One of our goals was to optimize all-inclusive cost to render per hour. We categorized the overall spend on the farm into various funnels, and assigned weights to the impact each lever can drive. At a high level, we looked into the following key areas:
Nodes - Are we using the right machine size and configurations on the farm? The current deployment had a single pool which forced the machine size to be optimized for worst-case usage, leading to waste for 90% of our use cases. Can we use GPU acceleration to optimize render times? What about leveraging instance types like Spot?
Utilization - How is the per node and overall farm utilization over 24X7X365? We looked at usage and submission patterns on the farm along with utilization to find out ways to drive efficiency.
Licenses - Because of the change from Enterprise License on-prem to Data Center license on Google Cloud, we were seeing license costs around 45% of the overall spend on the farm. What are the software license fees leveraged on the farm? What constraints do they enforce on scaling needs?
Other - We looked at storage, network transfers, and other miscellaneous costs on the farm. Together, they only accounted for 8% of the overall spend, so we deemed them insignificant to optimize initially.
Levers for optimizing usage
As part of our holistic strategy, we also set goals for improving workflow efficiency to optimize rendering hours. We realized during cost modeling that we could unlock large benefits by reducing the hours needed for the same unit of work. At a high level, we looked into the following areas:
Render quality - Can we optimize render settings like Irradiance, Noise, Threshold, and Resolution to reduce the render hours needed for each request without substantially impacting the quality of final renders?
Work unit - Can we reduce the number of render frames, render rounds, and angles for each request to reduce the number of renders needed per request and reduce waste in the pipeline?
Complexity - Can we look into optimizing specific materials or lightning settings and frames to reduce render complexity? Can we look at render requests at p90 based on render hours and create a feedback loop?
Artist experience - Can we improve the artist workflow by providing them with cloud workstations with local rendering and storage management to reduce the indirect invisible costs associated with rendering?
In our next article, we discuss how we applied the above strategies to plan and execute these initiatives, and share what we learned.
Googler Hasan Khan, Lead Principal Architect, Retail Global, contributed to this post.




