Orchestrate Vertex AI’s PaLM and Gemini APIs with Workflows
Mete Atamel
Cloud Developer Advocate
Introduction
Everyone is excited about generative AI (gen AI) nowadays and rightfully so. You might be generating text with PaLM 2 or Gemini Pro, generating images with ImageGen 2, translating code from language to another with Codey, or describing images and videos with Gemini Pro Vision.
No matter how you’re using gen AI, at the end of the day, you’re calling an endpoint either with an SDK or a library or via a REST API. Workflows, my go-to service to orchestrate and automate other services, is more relevant than ever when it comes to gen AI.
In this post, I show you how to call some of the gen AI models from Workflows and also explain some of the benefits of using Workflows in a gen AI context.
Generating histories of a list of countries
Let’s start with a simple use case. Imagine you want the large language model (LLM) to generate a paragraph or two on histories of a list of countries and combine them into some text.
One way of doing this is to send the full list of countries to the LLM and ask for the histories for each country. This might work but LLM responses have a size limit and you might run into that limit with many countries.
Another way is to ask the LLM to generate the history of each country one-by-one, get the result for each country, and combine histories afterwards. This might go around the response size limit but now you have another problem: it’ll take much longer because each country's history will be generated sequentially by the LLM.
Workflows offers a third and better alternative. Using Workflows parallel steps, you can ask the LLM to generate the history of each country in parallel. This would avoid the big response size problem and it would also avoid the sequential LLM calls problem, as all the calls to the LLM happen in parallel.
Call Vertex AI PaLM 2 for Text from Workflows in parallel
Let’s now see how to implement this use-case with Workflows. For the model, let’s use Vertex AI’s PaLM 2 for Text (text-bison) for now.
You should familiarize yourself with the Vertex AI REST API that Workflows will use, PaLM 2 for Text documentation and predict method that you’ll be using to generate text with the text-bison model.
I’ll save you some time and show you the full workflow (country-histories.yaml) here:
Notice how we’re looping over a list of countries supplied as an argument, making calls to the Vertex AI REST API with the text-bison model for each country in parallel steps and combining the results in a map. It’s a map-reduce style call to the LLM.
Deploy the workflow
Run the workflow with some countries:
You’ll get the results as fast as the slowest LLM call. Much faster than making each call sequentially. In a few seconds, you should see the output map with countries and their histories:
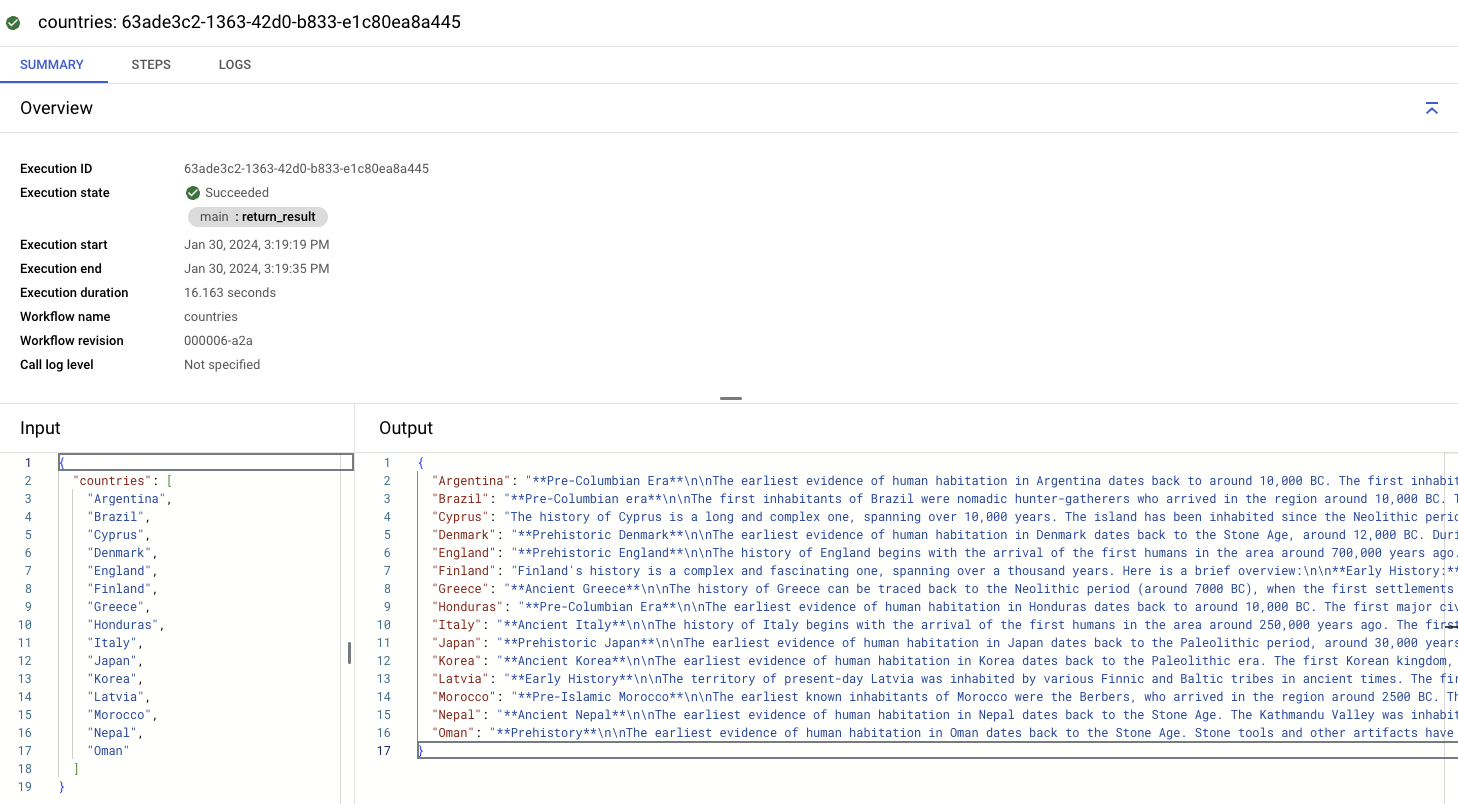
The full sample is in our GitHub repository here.
Call Vertex AI Gemini Pro from Workflows in parallel
You might be wondering: Isn’t Gemini the latest and best model I can use? You’re right and it’s totally possible to call Vertex AI Gemini Pro from Workflows with slight changes to the previous sample.
For Gemini, you should familiarize yourself with the Gemini API and the streamGenerateContent method that you’ll be using to generate text with the gemini-pro model.
I’ll save you time again and direct you to the full workflow using Gemini API in country-histories.yaml. I’ll just point out a couple of differences from the previous sample.
First, we’re using gemini-pro model and streamGenerateContent method:
Second, Gemini has a streaming endpoint, which means responses come in chunks and you need to combine the text in each chunk to get the full text. That’s why we have the following steps to extract and combine text from each chunk:
The full sample is in our GitHub repository here.
Call VertexAI Gemini Pro Vision from Workflows to describe an image
The real power of Gemini is its multimodal nature, which means it can generalize and understand and operate across different types of information such as text, code, audio, image and video.
So far, we’ve been generating text. Can we use Workflows to take advantage of the multimodal nature of Gemini? Sure, we can. As an example, you can use Workflows to get a description of this image from Gemini:

In this sample (describe-image.yaml), the workflow asks Gemini Pro Vision to describe the image in a Google Cloud Storage bucket:
Run the workflow:
You should see an output similar to the following:
Nice! The full sample is in our GitHub repository here. As an exercise, you can even extend this sample to describe a number of images in parallel and save the results to txt files back to the Cloud Storage bucket.
Summary
There are many ways of calling LLMs with client libraries, generated libraries, REST APIs, LangChain. In this post, I showed you how to call some of the gen AI models from Workflows. With its parallel steps and retry steps, Workflows offers a robust way of calling gen AI models. With its Eventarc integration, Workflows allows you to have event-driven LLM applications.
If you want to learn more, check our Access Vertex AI models from a workflow documentation page. As always, if you have any questions or feedback, feel free to reach out to me on Twitter @meteatamel.


