Using Vertex AI to build an industry leading Peer Group Benchmarking solution
Sean Rastatter
AI Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialThe modern world of financial markets is fraught with volatility and uncertainty. Market participants and members are rethinking the way they approach problems and rapidly changing the way they do business. Access to models, usage patterns, and data has become key to keeping up with ever evolving markets.
One of the biggest challenges firms face in futures and options trading is determining how they benchmark against their competitors. Market participants are continually looking for ways to improve performance, identifying what happened, why it happened, and any associated risks. Leveraging the latest technologies in automation and artificial intelligence, many organizations are using Vertex AI to build a solution around peer group benchmarking and explainability.
Introduction
Using the speed and efficiency of Vertex AI, we have developed a solution that will allow market participants to identify similar trading group patterns and assess performance relative to their competition. Machine learning (ML) models for dimensionality reduction, clustering, and explainability are trained to detect patterns and transform data into valuable insights. This blog post goes over these models in detail, as well as the ML operations (MLOps) pipeline used to train and deploy these models at scale.
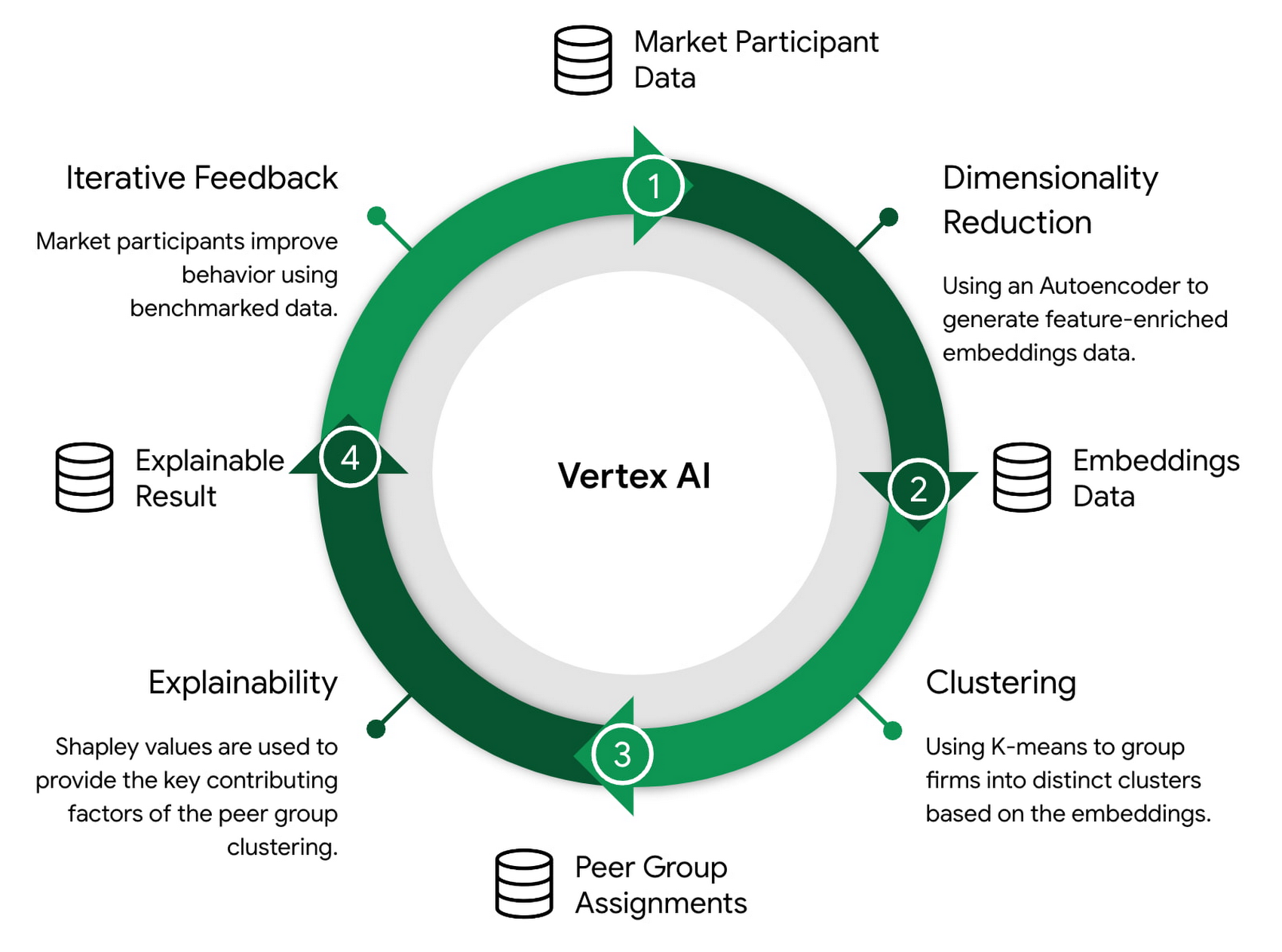
A series of successive models are used that feed predictive results as training data into the next model (e.g. dimensionality reduction -> clustering -> explainability). This requires a robust automated system for training and maintaining models and data, and provides an ideal use case for the MLOps capabilities of Vertex AI.
The Solution
Data
A market analytics dataset was used which contains market participant trading metrics aggregated and averaged across a 3 month period. This dataset contains a high number of dimensions. Specific features include buying and selling counts, trade and order quantities, types, first and last fill times, aggressive vs. passive trading indicators, and a number of other features related to trading behavior.
Modeling
Dimensionality Reduction
Clustering in high dimensional space presents a challenge, particularly for distance-based clustering algorithms. As the number of dimensions grows, the distance between all points in the dataset converge and become more similar. This distance concentration problem makes it difficult to perform typical cluster analysis on highly dimensional data.
For the task of dimensionality reduction, an Artificial Neural Network (ANN) Autoencoder was used to learn a supervised similarity metric for each market participant in the dataset. This autoencoder takes in each market participant and their associated features. It pushes the information through a hidden layer that is constrained in size, forcing the network to learn how to condense information down into a small encoded representation.
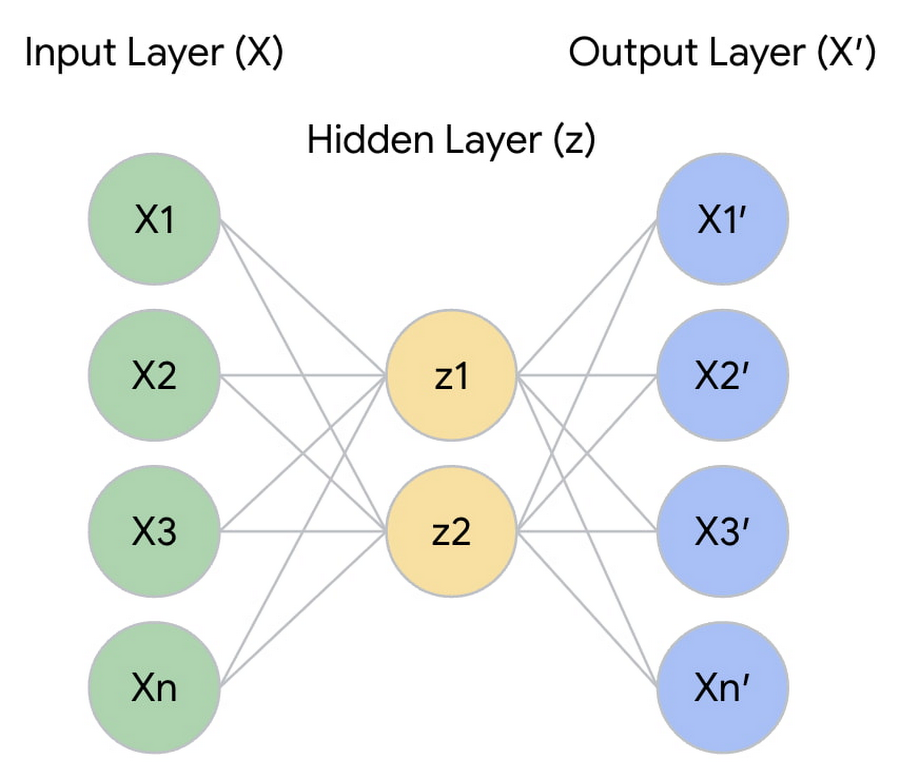
The constrained layer is a vector (z) in latent space, where each element in the vector is a learned reduction of the original market participant features (X); thus, allowing dimensionality reduction by simply applying X * z. This results in a new distribution of customer data q(X’ | X) where the distribution is constrained in size to the shape of z. By minimizing the reconstruction error between the initial input X and the autoencoder’s reconstructed output X’ we can balance the overall size of the similarity space (the number of latent dimensions) and the amount of information lost.
The resulting output of the autoencoder is a 2-dimensional learned representation of the highly dimensional data.
Clustering
Experiments were conducted to determine the optimal clustering algorithm, number of clusters, and hyperparameters. A number of models were compared, including density-based spatial clustering of applications with noise (DBSCAN), agglomerative clustering, gaussian mixture model (GMM), and k-means. Using silhouette score as an evaluation criterion, it was ultimately determined that k-means performed best for clustering on the dimensionally reduced data.
The k-means algorithm is an iterative refinement technique that aims to separate data points into n groups of equal variance. Each of these groups are defined by a cluster centroid, which is the mean of the data points in the cluster. Cluster centroids are initially randomly generated, and iteratively reassigned until the within-cluster sum-of-squares is minimized. Below: within-cluster sum-of-squares criteria.
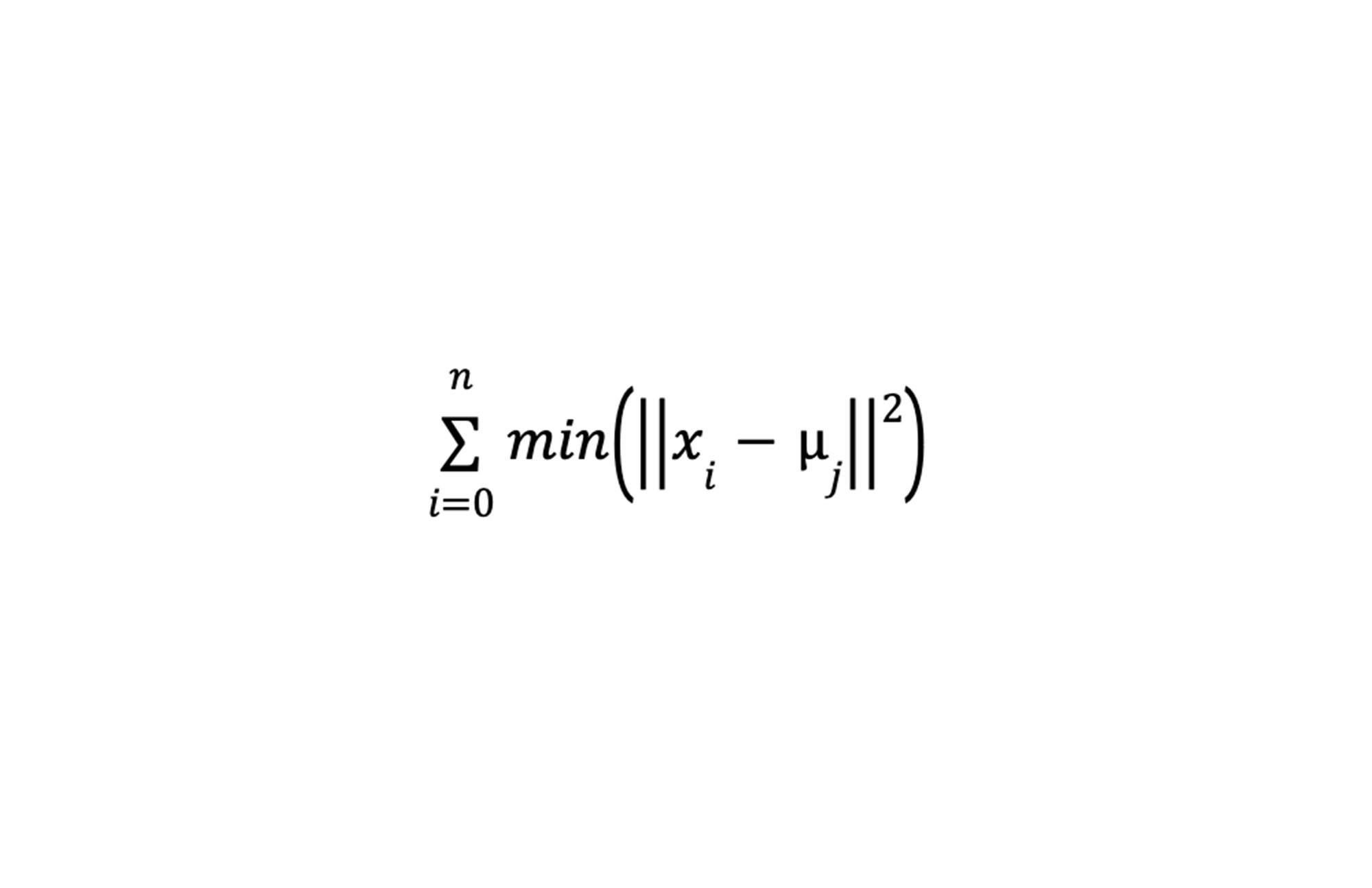
Explainability
Explainable AI (XAI) aims to provide insights into why a model predicts in a certain way. For this use case, XAI models are used to explain why a market participant was placed into a particular peer group. This is achieved through feature importance e.g. for each market participant, the top contributing factors towards a peer group cluster assignment.
Deriving explainability from clustering models is somewhat difficult. Clustering is an unsupervised learning problem, which means there are no labels or “ground truth” for the model to analyze. Distance-based clustering algorithms instead rely on creating labels for the data points based on their relative positioning to each other. These labels are assigned as part of the prediction by the k-means algorithm - each point in the dataset is given a peer group assignment that associates it with a particular cluster.
XAI models can be trained on top of k-means by fitting a classifier to these peer group cluster assignments. Using the cluster assignments as labels turns the problem into supervised learning, whereby the end goal is to determine feature importance for the classifier. Shapley values are used for feature importance, which explain the marginal contributions of each feature to the final classification prediction.
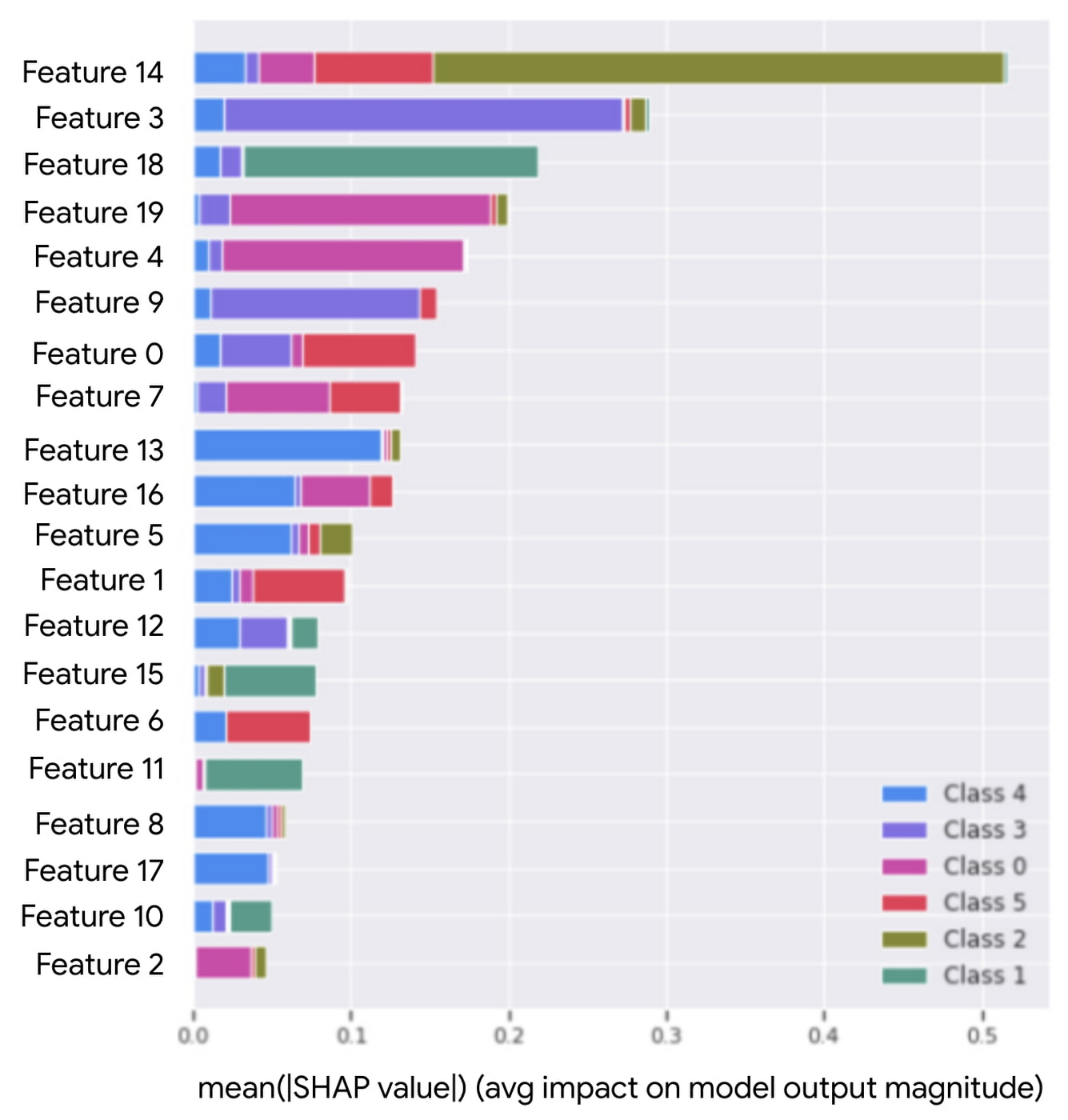
Shapley values are ranked to provide market participants with a powerful tool to analyze what features are contributing the most to their peer group assignments.
MLOps
MLOps is an ML engineering culture and practice that aims to unify ML system development (Dev) and ML system operation (Ops). Using Vertex AI, a fully functioning MLOps pipeline has been constructed that trains and explains peer group benchmarking models. This pipeline is complete with automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment and infrastructure management. It also includes a comprehensive approach for continuous integration / continuous delivery (CI/CD). Vertex AI’s end-to-end platform was used to meet these MLOps needs, including:
Distributed training jobs to construct ML models at scale using Vertex AI Pipelines
Hyperparameter tuning jobs to quickly tune complex models using Vertex AI Vizier
Model versioning using Vertex AI Model Registry
Batch prediction jobs using Vertex AI Prediction
Tracking metadata related to training jobs using Vertex ML Metadata
Tracking model experimentation using Vertex AI Experiments
Storing and versioning training data from prediction jobs using Vertex AI Feature Store
Data validation and monitoring using Tensorflow Data Validation (TFDV)
The MLOps pipeline is broken down into 5 core areas:
CI/CD & Orchestration
Data Ingestion & Preprocessing
Dimensionality Reduction
Clustering
Explainability
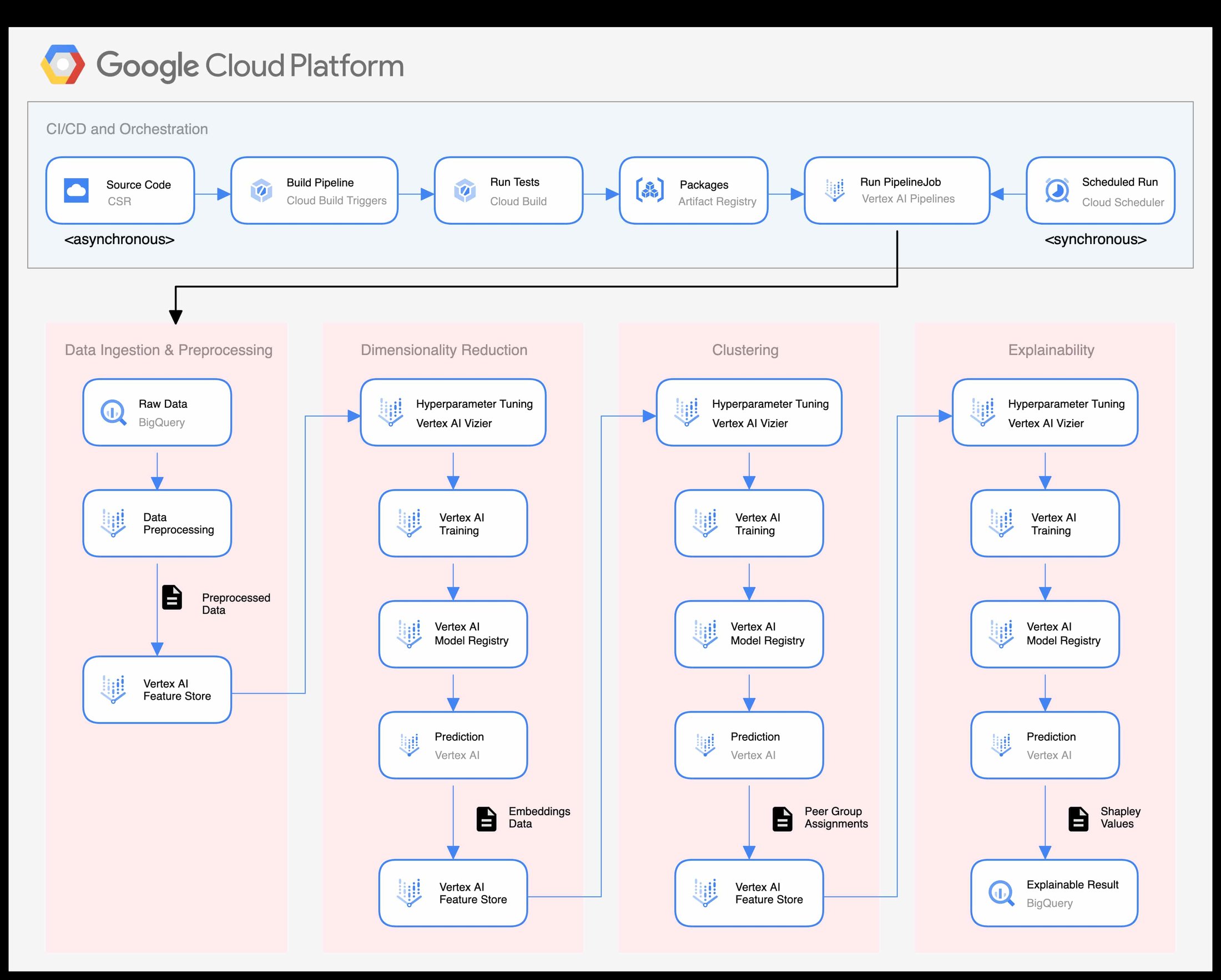
The CI/CD and orchestration layer was implemented using Vertex AI Pipelines, Cloud Source Repository (CSR), Artifact Registry, and Cloud Build. When changes are made to the code base, automatic Cloud Build Triggers are executed that run unit tests, build containers, push the containers to Artifact Registry, and compile and run the Vertex AI pipeline.
The pipeline is a sequence of connected components that run successive training and prediction jobs; the outputs from one model are stored in Vertex AI Feature Store and used as inputs into the next model. The end result of this pipeline is a series of trained models for dimensionality reduction, clustering, and explainability, all stored in Vertex AI Model Registry. Peer groups and explainable results are written to Feature Store and BigQuery respectively.
Working with AI Services in Google Cloud’s Professional Services Organization (PSO)
AI Services leads the transformation of enterprise customers and industries with cloud solutions. We are seeing widespread application of AI across Financial Services and Capital Markets. Vertex AI provides a unified platform for training and deploying models and helps enterprises more effectively make data driven decisions. You can learn more about our work at:
This post was edited with help from Mike Bernico, Eugenia Inzaugarat, Ashwin Mishra, and the rest of the delivery team. I would also like to thank core team members Rochak Lamba, Anna Labedz, and Ravinder Lota.




