Using data and ML to better track wildfire and assess its threat levels
Barrett Williams
Cloud ML Blog Editor
As California’s recent wildfires have shown, it’s often hard to predict where fire will travel. While firefighters rely heavily on third-party weather data sources like NOAA, they often benefit from complementing weather data with other sources of information. (In fact, there’s a good chance there’s no nearby weather station to actively monitor weather properties in and around a wildfire.) How, then, is it possible to leverage modern technology to help firefighters plan for and contain blazes?
Last June, we chatted with Aditya Shah and Sanjana Shah, two students at Monta Vista High School in Cupertino, California, who’ve been using machine learning in an effort to better predict the future path of a wildfire. These high school seniors had set about building a fire estimator, based on a model trained in TensorFlow, that measures the amount of dead fuel on the forest floor—a major wildfire risk. This month we checked back in with them to learn more on how they did it.
Why pick this challenge?
Aditya spends a fair bit of time outdoors in the Rancho San Antonio Open Space Preserve near where he lives, and wanted to protect it and other areas of natural beauty so close to home. Meanwhile, after being evacuated from Lawrence Berkeley National Lab in the summer of 2017 due a nearby wildfire, Sanjana wanted to find a technical solution that reduced the risk of fire even before it occurs. Wildfires not only destroy natural habitat but also displace people, impact jobs, and cause extensive damage to homes and other property. Just as prevention is better than a cure, preventing a potential wildfire from occurring is more effective than fighting it.
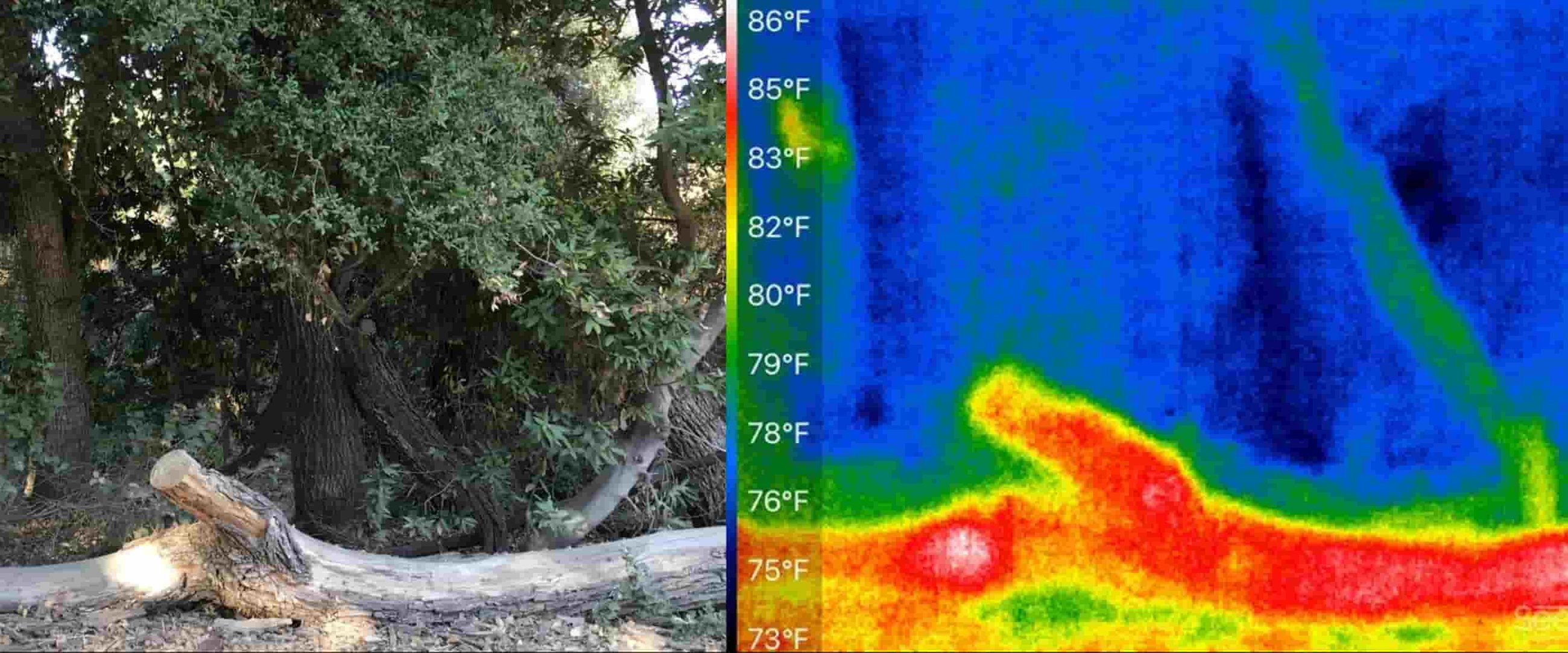
With a common goal, the two joined forces to explore available technologies that might prove useful. They began by taking photos of the underbrush around the Rancho San Antonio Open Space Preserve, cataloguing a broad spectrum of brush samples—from dry and easily ignited, to green or wet brush, which would not ignite as easily. In all, they captured 200 photos across three categories of underbrush: “gr1” (humid), “gr2” (dry shrubs and leaves), and “gr3” (no fuel, plain dirt/soil, or burnt fuel).
Aditya and Sanjana then trained a successful model with 150 sample (training) images (roughly 50 in each of the three classes) plus a 50 image test (evaluation) set. For training, the pair turned to Keras, their preferred Python-based, easy-to-use deep learning library. Training the model in Keras has two benefits—it permits you to export to a TensorFlow estimator, which you can run on a variety of platforms and devices, and it allows for easy and fast prototyping since it runs seamlessly on either CPU or GPU.
Preparing the data
Before training the model, Aditya and Sanjana ran a preprocessing step on the data: resizing and flattening the images. They used the image_to_function_vector, which accepts raw pixel intensities from an input bitmap image and resizes that image to a fixed size, to ensure each image in the input dataset has the same ‘feature vector’ size. As many of the images are of different sizes, the pair resized all their captured images to 32x32 pixels. Since Keras models take as their input a 1-dimensional feature vector, he needed to flatten the 32x32x3 image into a 3072-dimensional feature vector. Further, he defined the ImagePaths to initiate the list of data and label, then looped over the ImagePaths individually to load them to the folder storage using cv2.imread function. Next, the pair extracted the class labels (as gr1, gr2, and gr3) from each image’s name. He then converted the images to feature vectors using image_to_feature_vector function and updated the data and label lists to match.
Aditya and Sanjana next discovered that the simplest way to build the model was to linearly stacks layers, to form a sequential model, which simplified organization of the hidden layers. They were able to use the img2vec function, built into TensorFlow, as well as a support-vector-machine (SVM) layer.
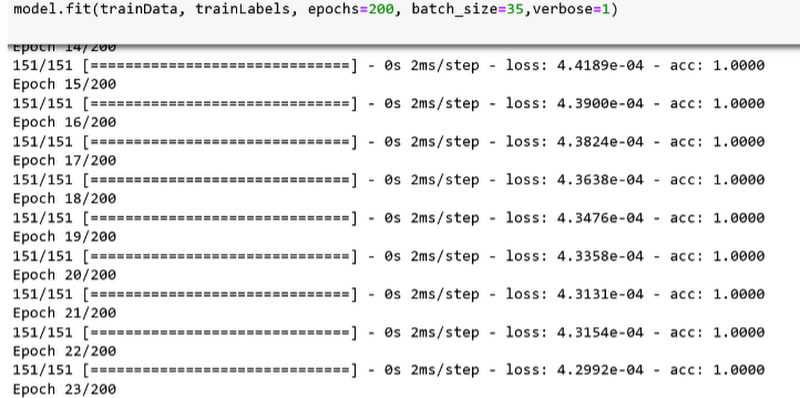
Next, the pair trained the model using a stochastic gradient descent (SGD) optimizer with learning rate = 0.05. SGD is an iterative method for finding an optimal solution by using stochastic gradient descent. There are a number of gradient descent methods typically used, including rmsprop, adagrad, adadelta, and adam. Aditya and Sanjana tried rmsprop, which yielded very low accuracy (~47%). Some methods like adadelta and adagrad yielded slightly higher accuracy but took more time to run. So they decided to use SGD as it offers better optimization with good accuracy and fast running time. In terms of hyperparameters, the pair tried different numbers of training epochs (50, 100, 200) and batch_size values (10, 35, 50), and he achieved the highest accuracy (94%) with epoch = 200 and batch_size = 35.
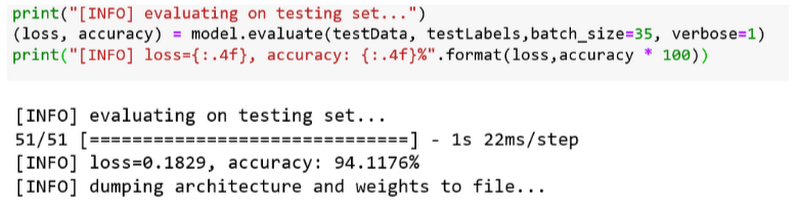
In the testing phase, Aditya and Sanjana were able to achieve the 94.11% accuracy utilizing only the raw pixel intensities of the fuel images.
The biggest challenge in this whole process was the data pre-processing step, as it involved accurately labeling the images. This very tedious task took Aditya and Sanjana more than four weeks while they created their training dataset.
Modeling fire based on sensor data
Although Aditya and Sanjana now had a way to classify whether different types of underbrush were ripe for fire, they wondered how they might assess the current status of an entire area of land like the Rancho San Antonio Open Space Preserve.
To do it, the pair settled on a high-definition image sensor, which connects over long-range, low-power LTE, to capture and relay images to Aditya’s computer, where they can run the model and classify the new inbound images. The device also collects a number of other metrics, including wind speed, wind direction, humidity, and temperature, and can classify an area of roughly 100 square meters (during daylight hours) to determine whether the ground cover will likely ignite or not. Aditya and Sanjana are currently collecting sensor data and testing the accuracy of their model at five different sites.

By combining real-time humidity and temperature data with NOAA-based wind speed and direction estimates, Aditya and Sanjana hope to determine in which direction a fire might travel. For the moment, the image-classification and the sensor-based prediction systems operate independently, but they plan to combine them in the future.
What’s next
Although currently the pair are simply running TensorFlow models on Aditya’s gaming notebook PC (a tool of choice for data scientists on the go), Aditya and Sanjana plan to try out Cloud ML Engine in the future, to enable more flexible scaling than was possible on a single laptop. Image gathering from remote forest areas is another challenge they want to tackle, and they’re experimenting with all-terrain ground and aerial drones to collect data for this purpose.
The pair also plan to continue their efforts working with Cal Fire to deploy their device. Currently Cal Fire determines moisture levels by weighing known fuels, such as wood sticks, a process that requires human labor. Aditya and Sanjana’s device offers the potential to reduce the need for that labor.

Although fire is an often devastating force of nature, it is inspiring that a team of high schoolers hope to provide an effective new tool to assist agencies in predicting and tracking both wildfires and the weather factors that enable them to spread.



