Train ML models on large images and 3D volumes with spatial partitioning on Cloud TPUs
Youlong Cheng
Software Engineer, Google Brain
HyoukJoong Lee
Software Engineer, Google Brain
Convolutional neural networks (CNNs) are the foundation of recent advances in image classification, object detection, image segmentation, and many other computer vision applications. However, practitioners often encounter a problem when they try to train and run state-of-the-art computer vision models on larger input images: their CNN no longer fits on a single accelerator chip!
To overcome this limitation, Cloud TPUs now provide a new spatial partitioning capability that makes it possible to split up a single model across several TPU chips to process much larger input data sizes. This technique is general enough to handle large 2D images as well as 3D volumes, which makes it valuable for applications ranging from object detection for autonomous navigation to analysis of 3D medical scans. For example, Mayo Clinic has used spatial partitioning on Cloud TPU Pods to segment CT scans at their full 256x256x256 pixel resolution instead of being forced to downsample, which can cause accuracy loss and other issues.
At Google, we have been using spatial partitioning for many different applications, including medical image segmentation, video content analysis, and object detection for autonomous driving.
Cloud TPU spatial partitioning allows you to seamlessly scale your model by leveraging 2, 4, 8, or even 16 cores for training ML models that would otherwise not fit into the memory on a single TPU core. When using more than one core for your model, our XLA compiler will automatically handle the necessary communications among all cores. This means there are no code changes required! All you need to do is configure how the inputs to the model should be partitioned.
Below is an example of how one big image can be split up into four smaller images that are then processed separately on individual TPU cores.
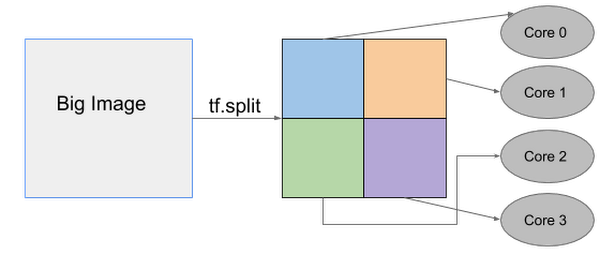
TPU spatial partitioning API
The TPU spatial partitioning API is supported in TPUEstimator; to use it, you specify in TPUConfig how to partition each input tensor.
The following is a TPUConfig example of four-way spatial partitioning for an image classification model. This configuration will split the features tensor into four parts along the height dimension (assuming the tensor has shape [batch, height, width, channel]).
Reference models
2D object detection
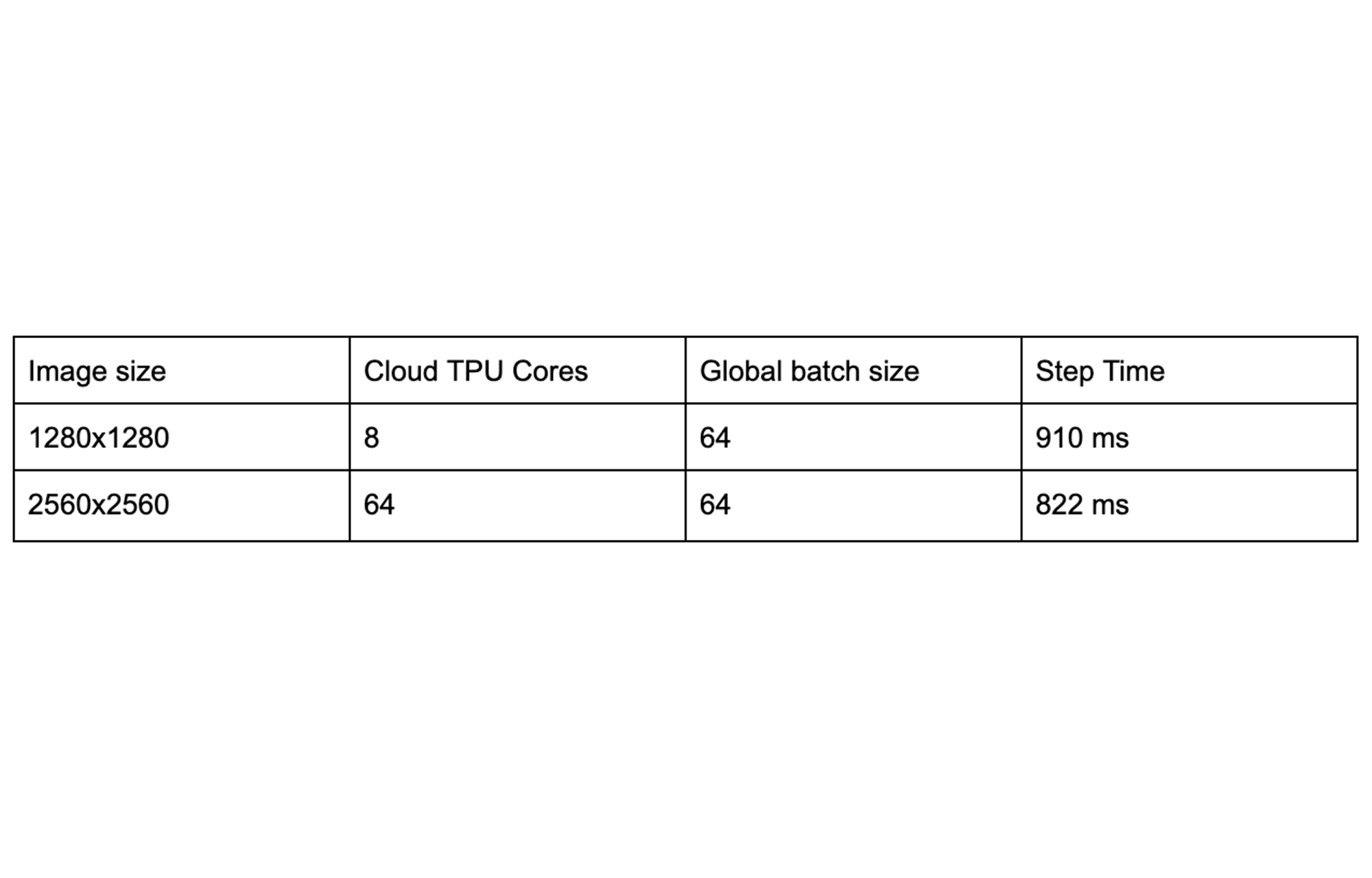
RetinaNet is an object detection model that localizes objects in images with a bounding box and also classifies the identified objects. The largest image size that fits on a single Cloud TPU core (with per-device batch 8) is 1280x1280. With spatial partitioning, we can train 4x larger images across the eight TPU cores of a single Cloud TPU device.
The table below shows that spatial partitioning can also be used across a multi-host Cloud TPU Pod slice to accommodate an even larger image size (2560x2560). By automatically distributing all of the necessary processing across 64 TPU cores, the overall step time remains low even when working with a much larger image:
3D image segmentation
3D UNet is a popular dense 3D segmentation model which has been widely used in the medical imaging domain. The original resolution for CT images can be as large as 256x256x256, which is too large to fit into a single Cloud TPU core. In the past, medical researchers would typically need to downsample the input volume to 128x128x128, potentially giving up accuracy in the process. With Cloud TPU spatial partitioning, no compromise is necessary: 16-way spatial partitioning makes it possible to process CT image scans at the the full input resolution of 256x256x256.
The table below shows that spatial partitioning across 128 TPU cores makes it possible to process a full-resolution 256x256x256 CT scan sample even faster than a 128x128x128 sample can be processed on a smaller number of cores.

Getting started with spatial partitioning
To learn how to configure spatial partitioning properly for your applications, consult this guide. You can also try out our reference models (RetinaNet, 3D UNet) to train 2D object detection and 3D image segmentation models with spatial partitioning enabled.
Acknowledgements
Many thanks to our collaborators Panagiotis Korfiatis, Ph.D., and Daniel Blezek, Ph.D., from Mayo Clinic for providing the initial 3D UNet model and training data.
Thanks also to those who contributed to this post and who helped implement spatial partitioning on Cloud TPUs, including Zak Stone, Wes Wahlin, Xiaodan Song, Greg Mikels, Yeqing Li, Le Hou, Chiachen Chou, and Allen Wang.